



TABLE OF CONTENT
What this piece entails
1. Current State of the Modern Data Stack
2. Getting into the Specifics
a) The Structure
b) Elements of the Stack
c) Before & After at a Glance
2024 kicked off with Matt Turck’s famed MAD Landscape, or a pile of all available and significant solutions in the Modern Data Stack. While it does look overwhelming, especially for folks in decision-making positions, more options mean more flexibility, right? Yes. But also no.
I'd like to cite one of the nice quotes from Winston Churchill. The nice thing about having the modern data stack, data mesh, real-time analytics, and feature stores is you always know exactly which database to choose for the job. Of course, Winston didn't say that. As far as I know, no one ever said that.
In fact, I hear people saying the opposite. Year after year, they say, the database landscape is getting more confusing. There are just too many options to pick from. Here's a bunch of data systems, most of which you're probably familiar with, or at least heard about.”
~Felix GV, Principal Staff Engineer LinkedIn
And all good things, including flexibility, come with a cost.

Once the MDS had become a part of the lexicon for VCs and CDOs and bankers, founders had every reason to claim the moniker for their own products. This isn’t a problem (or a conspiracy!), this is just how capitalism and ideas work.
This is when the vendor ecosystem in the modern data stack reached peak collaboration. The end-to-end problem was far too big for any one startup to solve, and so swim lanes were established and partnership ruled the day.
~Tristan Handy, The Analytics Engineering Roundup
While a collaborative ecosystem offered end users great flexibility, it also meant dealing with the complexity of an increasingly growing mesh of tools and vendors in the data landscape, most with lock-ins or high dependability owing to learning curves and heavy migrations.
Flexibility and complexity are often directly proportional. But at some point, the cost of complexity is far more overwhelming than the value of flexibility. We cannot deny the refreshing value the cloud technology and the surrounding ecosystem of the Modern Data Stack brought into the data industry.
But as it keeps growing and more solutions and options for existing solutions keep getting added, a ton of integration & maintenance overheads kick in along with a heavy cognitive overload to choose and climb the learning curves of different design patterns across different tools.
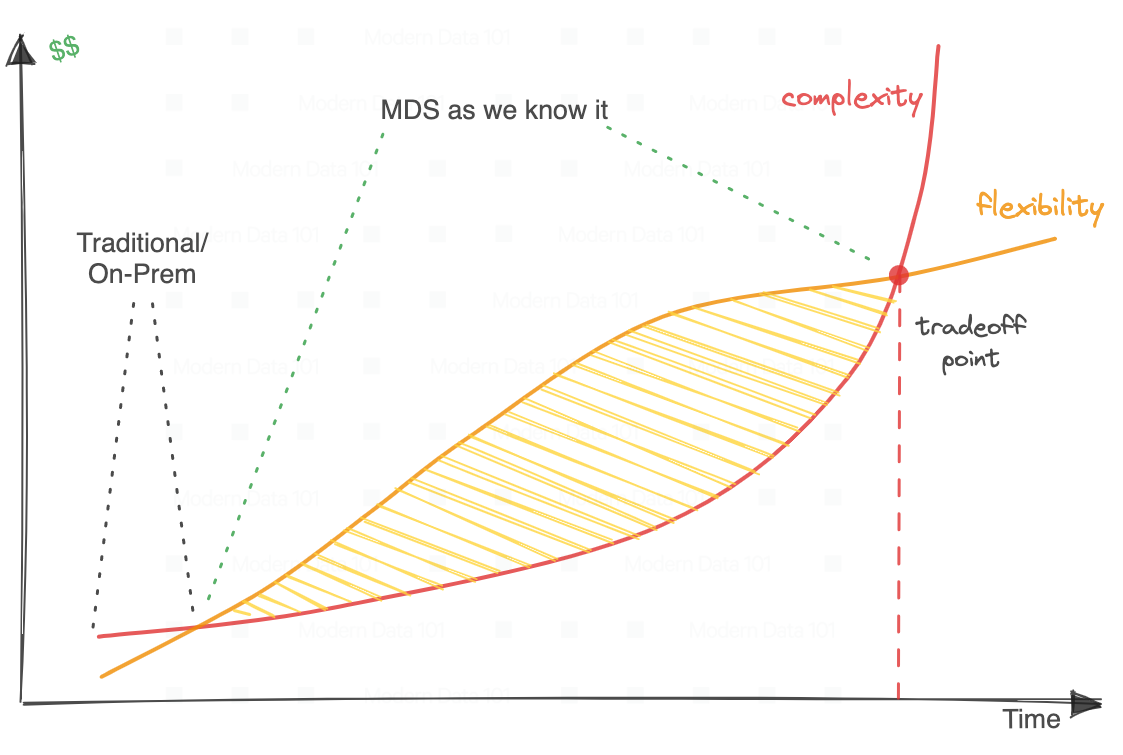
We are at a point where the value of each individual solution or investment is only partially leveraged by the organisation/team due to a lot of effort diverted towards maintenance and complexity management. We are at a point where the cost of complexity is higher than the value and cost of flexibility, which leads teams to limit efforts on certain complex pipelines, thereby limiting them from experiencing the full power of solutions they have already adopted.
So, What’s the “Modern” in Modern Data Stacks Now?
Data consumers have largely outgrown what MDS can offer. The industry's struggle with integration overheads and data silos has remained unresolved. Updating the “modern” in Modern Data Stacks has long been overdue.
- The “modern” way is not to omit these tools and discard all existing investments but to curb the overwhelm of these tools and enable them more efficiently.
- Allow more focus and effort on building data solutions and applications over managing complexities, plumbing, and learning curves of different design patterns across different tools.
- Become Data-First instead of Maintenance-First.
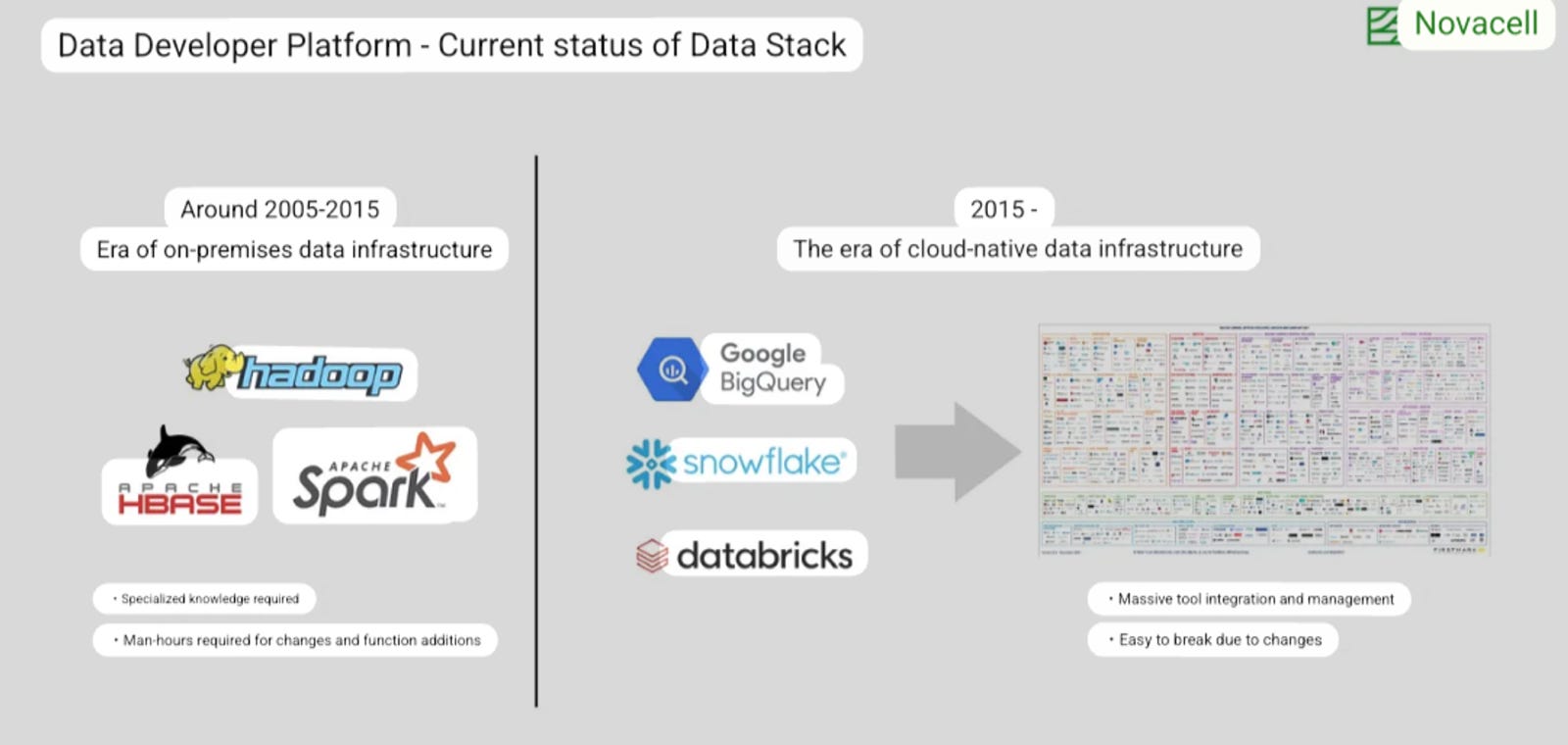
Current State of the Modern Data Stack
Keeping fancy naming conventions aside, let’s talk pure tech. In response to MDS complexities, the solution for the latest state of the Modern Data Stack lies in platform engineering. A unifying platform which:
- Furnishes standard interfaces to talk to data and existing tools (common access patterns)
- Demystifies complex and different access patterns of data sources
- One-time plug-in to interoperate with every other tool in the ecosystem
- Omits steep learning curves required to operate different tools
- Optimizes the ROI of each existing tool and pipeline
- Furnishes unified data governance (quality, observability, security), metadata management, and orchestration. (Platform has end-to-end ecosystem visibility)
- Enables declarative management of the data stack so engineers can focus on building solutions
Note how the platform doesn’t strive to replace existing solutions but rather enables and expands them.
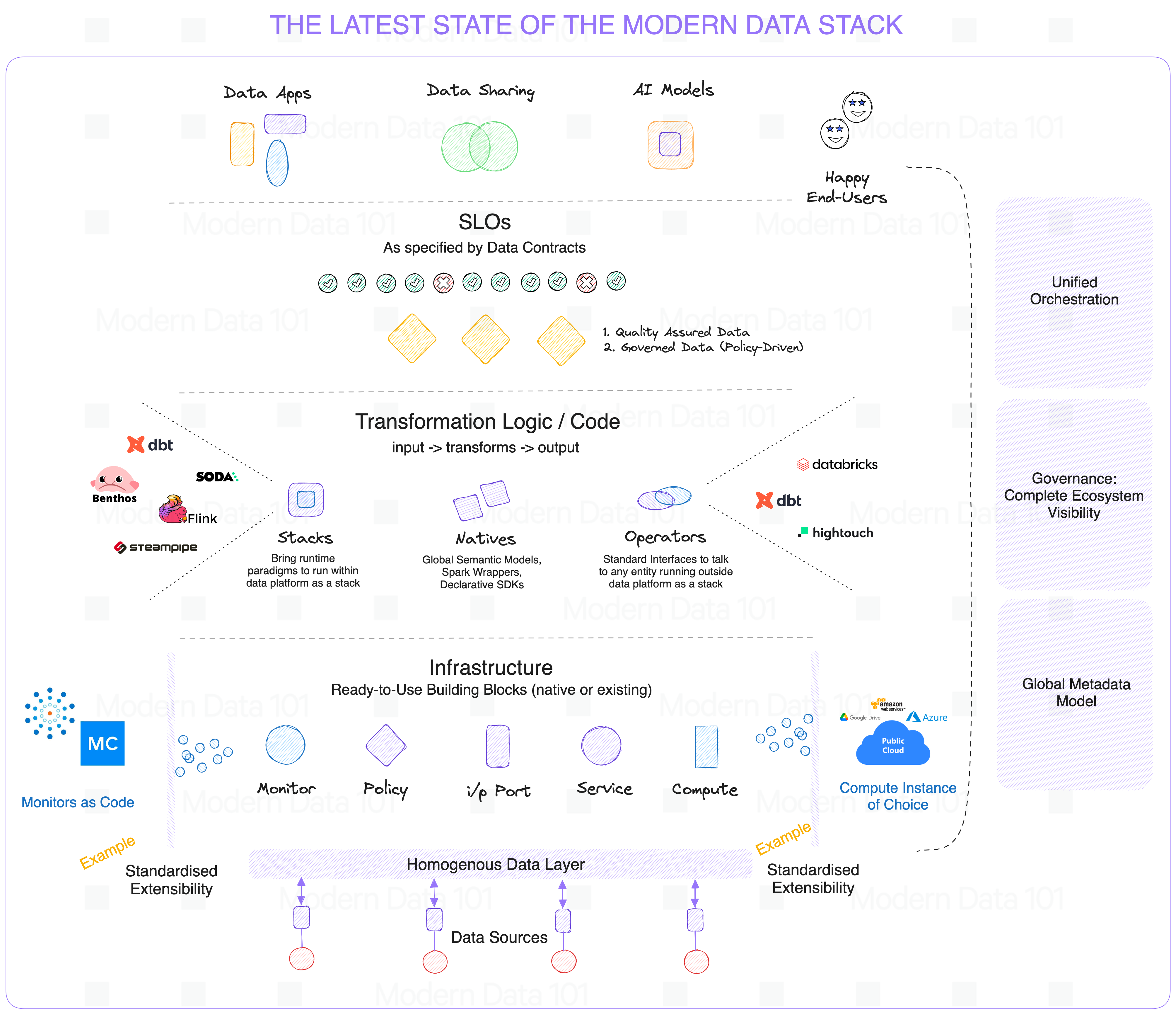
Data Platform as a Stack: Standardised interfacing with all existing tools, declarative data management, and e2e governance, orchestration, and metadata management.
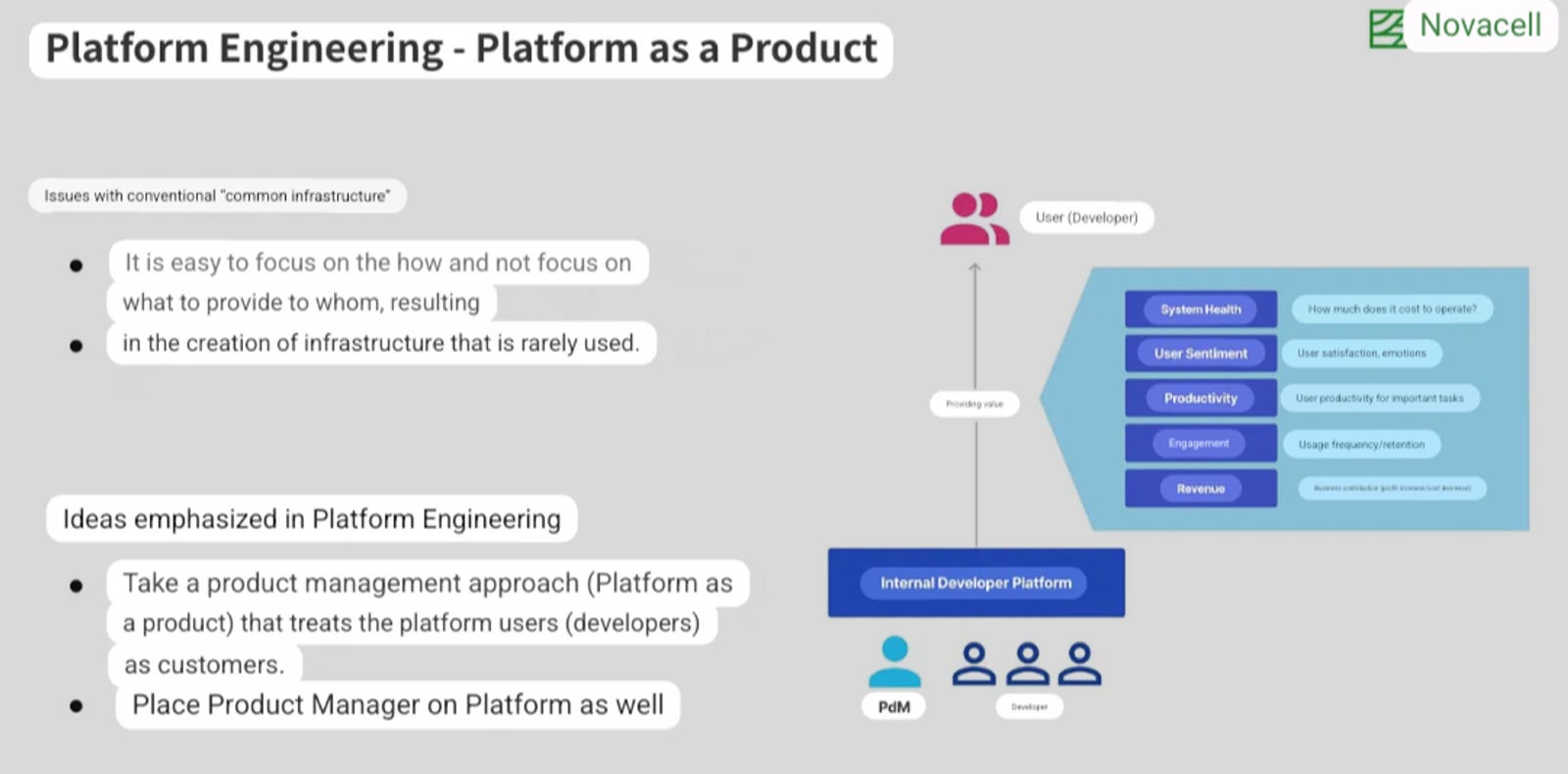
Platform engineering stemmed successfully in the software world through the Internal Developer Platform (IDP) standard. The Data Developer Platform standard was mirrored on the same and customised around the indefinite element of data which is missing from the software parallel.
datadeveloperplatform.org was launched recently as an infrastructure standard as a community-influenced repo for standards on platform engineering for data development: From objectives and design to capabilities and architecture standards. It soon changed shape from community-influenced to community-driven.
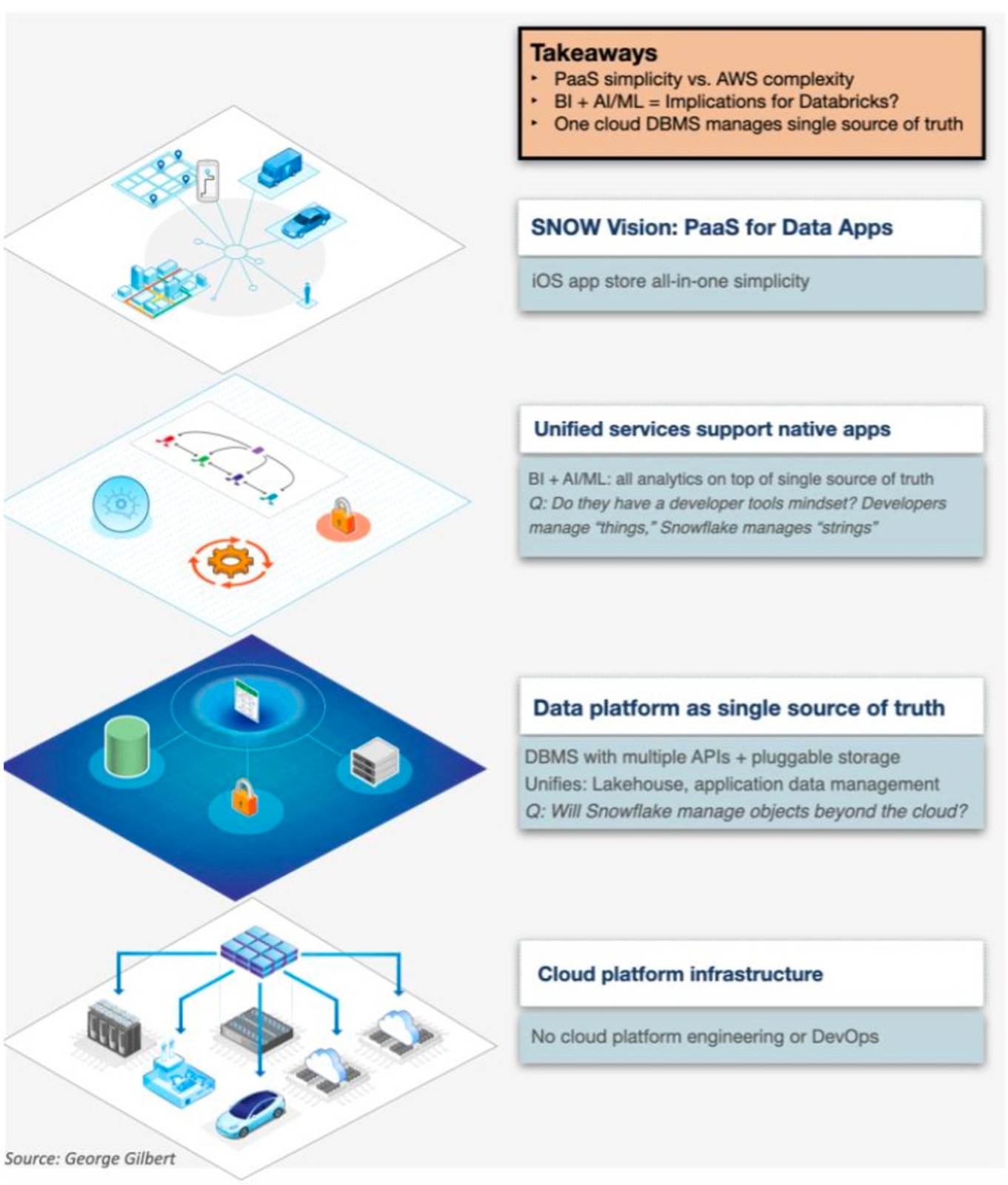
The incremental progress of the industry towards platform engineering as a unifying piece was also presented at the Snowflake Summit this year, where the data platform was positioned as the single source of truth in the organisation’s data stack.
We believe the maturity of organizations in terms of their data platform utilization is evolving rapidly. Our research indicates a dynamic environment where data platforms are progressively diversifying their capabilities.
~ David Vellante on The Cube Research, Co-Founder @SiliconANGLE Media
Data Developer Platforms were also presented at the Data Engineering Study where 22 Data Engineers from 5 companies looked back on the trajectory of 2023 and distilled it down to Data Developer Platforms and Platform Engineering as the natural next step for the data industry.
The industry-wide shift to Data Platforms as a Stack as the “Modern” or latest Data Stack is more prominent and macro than can be perceived in microscopic hype cycles.
This year saw some incredible platform players who are building some impressive and pioneering tech aligned to the standards condensed in datadeveloperplatform.org. They have repeatedly instilled faith in platform engineering as the next best step for truly data-driven experiences.
And it also served as validation for platform engineering for data when conversations around Data Platforms as a Stack shot up in some data communities this year. It was nice to see it surface in relevant dialogue and condense information from various community trails along the way.
Getting into the Specifics...
What Does the Current MDS, aka Data Platform as a Stack, Mean?
The latest state of the Modern Data Stack is essentially a self-serve data platform that enables you to build data solutions quickly by abstracting complex and distributed subsystems and delegating low-impact jobs to the platform. Such a self-serve platform, as most of us are aware, has also been mentioned as a critical necessity for the data mesh paradigm. datadeveloperplatform.org undertakes to standardise this.
This stack aims to help you leverage all existing tools and services to their optimum potential through standardised integration & access, resource optimisation, declarative control and management, and overall abstracted low-level complexities.
A Data Developer Platform (DDP) can be thought of as an internal developer platform (IDP) for data engineers and data scientists. Just as an IDP provides a set of tools and services to help developers build and deploy applications more easily, a DDP provides a set of tools and services to help data professionals manage and analyze data more effectively.
The primary value-add of a DDP lies in its unification ability- instead of having to manage multiple integrations and overlapping features of those integrations, a data engineer can breathe easy with a clean and single point of management.
The Structure of the Current Modern Data Stack
Tying the Volatile with Concrete
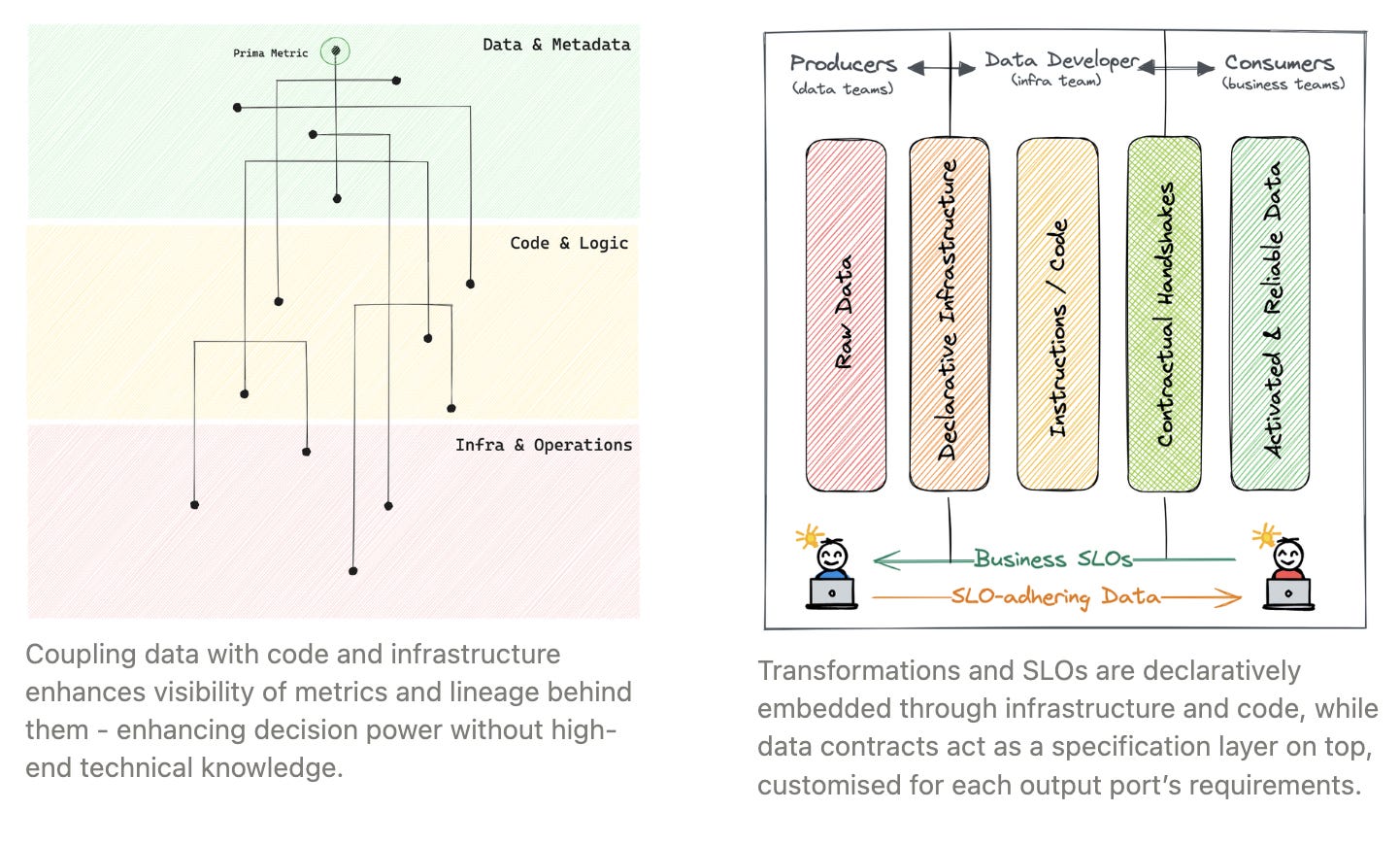
Data is the core entity of data stacks and solutions, and it is volatile and indefinite in nature. Which, in a way, is the primary root of all problems. You need to consistently govern it and monitor its consistency and quality to ensure everything that’s built around it works fine.
This is why coupling data with infrastructure and code (logic) brings a sense of stability to the solutions. When the nature of data changes, you know:
- If the change was induced by infra/code stack
- If the change was induced by external factors
- If the change demands changes in infra and code, and what changes exactly
Data, therefore, becomes part of a repeatable and reproducible cycle, which was essentially thought to be nearly impossible with the indefinite element of data. In other words, you inherently build data products with such a stack.
So, How Does the Journey of Data Look in a Data Platform as a Stack
Input sources → Source SLOs (quality condition + policies) → Transformations → SLOs for each O/P port → Consumption at Output Ports
How does this impact the Business & Data Consumers?
(Execs, Customers, Metric-Driven Teams)
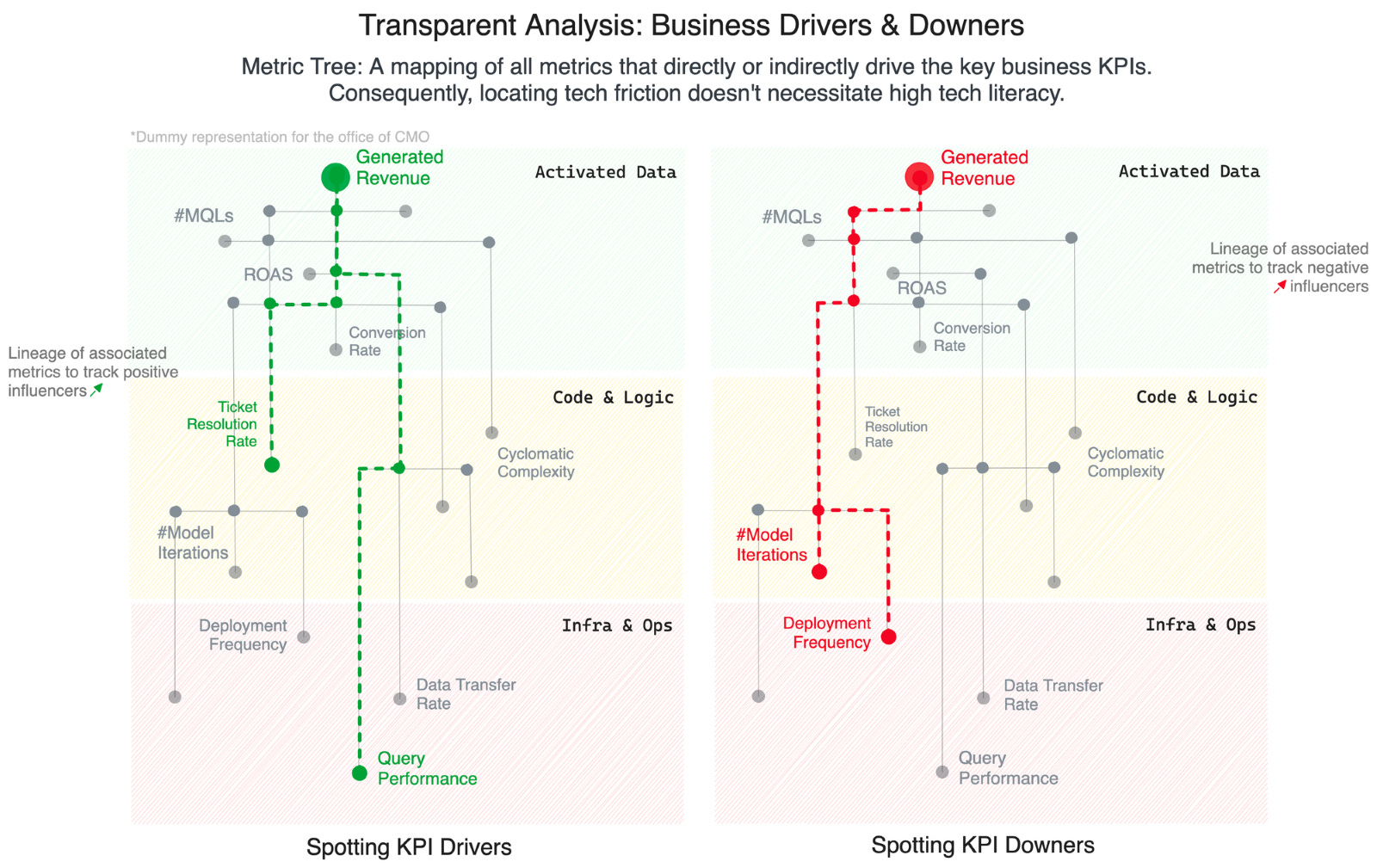
Let’s take the example of executives who are direct consumers of data and use it to define and execute strategic decisions. How does such a coupling help, say, CMOs & associated decision-makers:
- Ability to detect tracks which are fuelling primary business metrics/KPIs
- Ability to detect tracks which are pulling down the primary KPIs
- Informed calls on empowering or shutting down tracks across business initiatives and technical tracks without the need to be technically savvy or skilled
- Complete transparency and detailed lineage behind all metrics that are pushing the key metrics such as Revenue, Conversion Rate, or #MQLs forward
In essence, data initiatives can run at the pace of the business.
The complete stack at a glance that enables the above coupling →
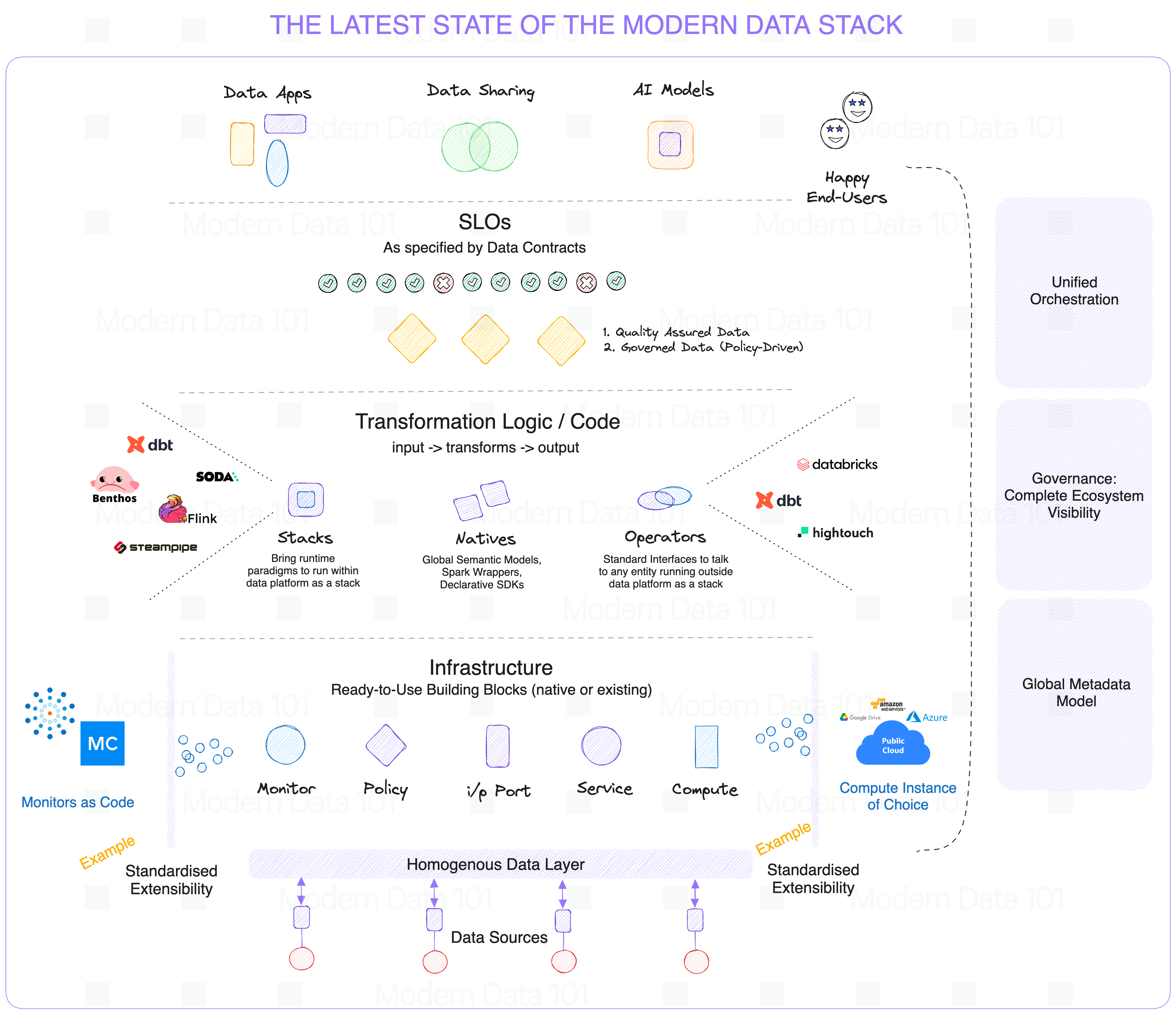
To learn more about data platforms as a stack, check out the independently maintained documentation on datadeveloperplatform.org.
Elements of the Stack
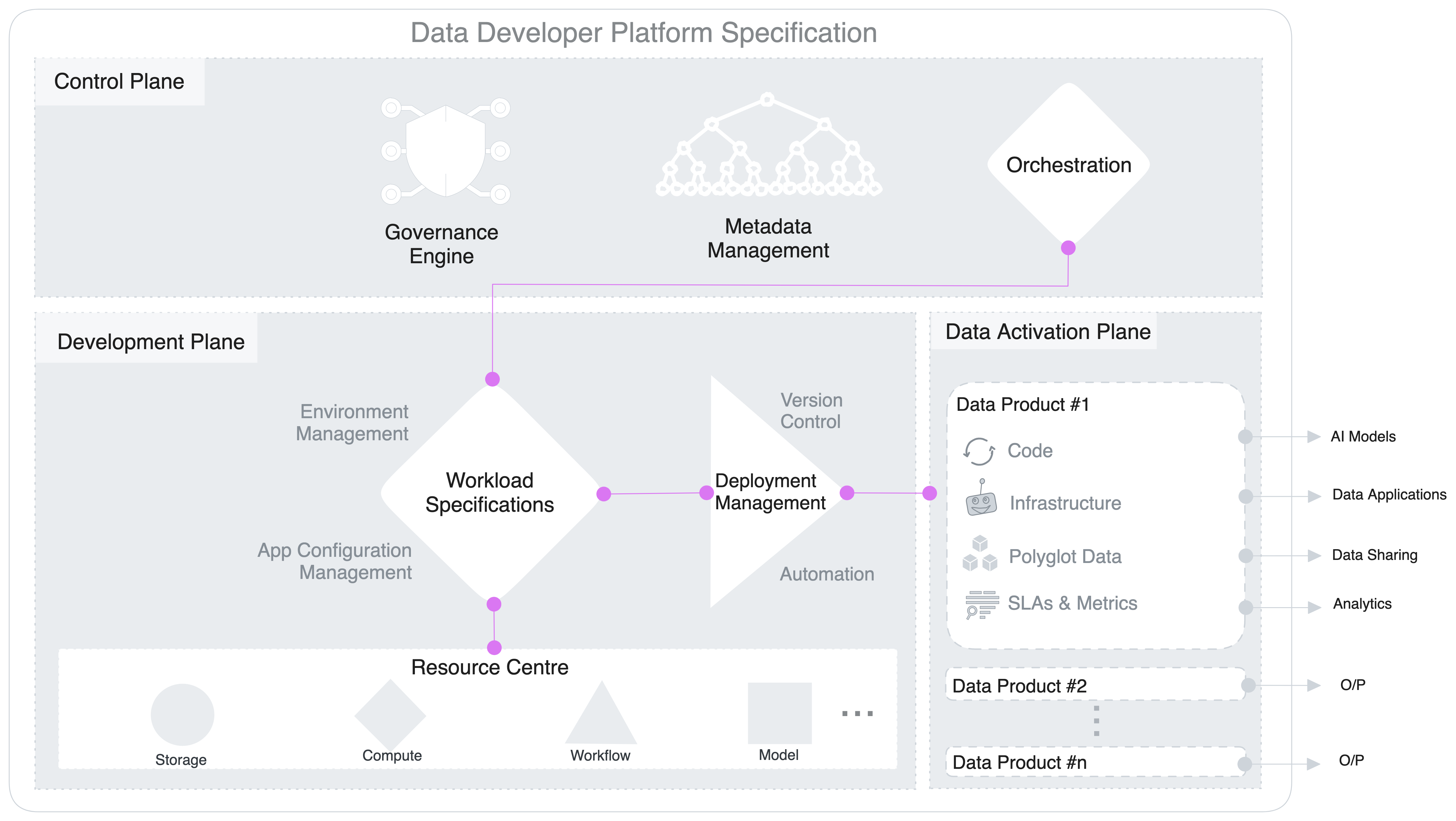
Control Plane
Heart of the stack with complete visibility across the data ecosystem.

Development Plane
A flexible and declarative workshop with standardised integration and interfaces.

Activation Plane
Where the data is actively used for end usecases.

Modern Data Stack: Before and After at a Glance













