





TABLE OF CONTENT
TOC
I. Data Product Refresher
II. Goals of Data Product Testing
III. Components of Data Product Testing Strategy
IV. Aspects of Data Products Considered for Testing
V. What, When, How: Testing During the Data Product Lifecycle
- Testing at Design Stage
- Testing at Develop Stage
- Testing at Deploy Stage
- Testing at Evolve Stage
VI. Facilitating Data Product Testing Strategy
- Role of Data Contracts, SLOs/SLIs
- Role of Data Platform
- Testing Dashboards to Boost Adoption
VII. Future Trends in Data Product Testing
Sneak Peek!
Before diving straight into Data Product Testing Strategies, let’s take a brief walk through the ABCs of data products for refreshed context.
I. Data Product Refresher
What are Data Products
Data products are "an integrated and self-contained combination of data, metadata, semantics, and templates. It includes access and logic-certified implementation for tackling specific data and analytics scenarios and reuse. A data product must be consumption-ready (trusted by consumers), up-to-date (by engineering teams), and approved for use (governed). (Source: Gartner)
What are the Components of a Data Product
*from an implementation/execution POV
In the context of Data Products within a Data Developer Platform or DDP (Data Product Implementation Platform Infrastructure), it represents the architectural quantum, the smallest deployable unit with high functional cohesion. It encapsulates all the necessary components required for its independent operation, including code, infrastructure configurations, support for handling polyglot data, and the ability to emit product metrics.
Code
Logic, algorithms, and data processing pipelines that drive the functionality of the Data Product. Includes data transformations, analytics models, and any custom code required to process and analyse the data. Developed using industry-standard programming languages and frameworks, ensuring maintainability and extensibility.
Infrastructure
Underlying systems, hardware, and software configurations needed to support the execution of a Data Product. Includes provisions for compute, storage, network connectivity, and other infra resources required for data processing and delivery. Designed to be scalable, reliable, and resilient for efficient execution of Data Products.
Polyglot data (input and output)
Data Product embraces polyglot data, which refers to diverse data formats, structures, and sources encountered in the data landscape. Structured, semi-structured, and unstructured data processing, allowing for seamless integration. Supports data ingestion, transformation, and enrichment to enable comprehensive data handling.
Product Metrics
Ability to emit product metrics, crucial for evaluating the Data Product's performance, usage, and effectiveness. May include data processing times, throughput, error rates, usage statistics, and other relevant performance indicators (also referred to as Data Product Metadata). Provides insights into the behaviour, efficiency, and impact of the Data Product, enabling data professionals to monitor its performance, optimise resource allocation, and identify areas for improvement.
What are the Stages of the Data Product Lifecycle
To have good context on Testing Strategies, it is especially important to refresh the idea of the Data Product Lifecycle because testing seeps into each stage and iteratively boosts the next.
The Data Product Lifecycle spans four stages: Design, Develop, Deploy, and Evolve. If you’ve not already built a solid understanding of these stages, we’ve got you covered and would highly recommend going through these resources first and then coming back to the Data Product Testing Strategy for enriched context.
📝 Editior’s Recommendation
Read first before diving into the details of Data Product Testing.
The Complete Data Product Lifecycle at a Glance | Issue #35
How to Build Data Products - Design: Part 1/4 | Issue #23
How to Build Data Products - Develop: Part 2/4 | Issue #25
How to Build Data Products - Deploy: Part 3/4 | Issue #27
How to Build Data Products - Evolve: Part 4/4 | Issue #30
II. Goals of Data Product Testing
🎯 Ensure Data Quality & Consistency
Data must be accurate, complete, and reliable to drive effective decision-making.
Why this Goal
Poor data quality breeds incorrect insights, operational inefficiencies, and a loss of trust in analytics. Without automated checks, missing values, schema drift, and inconsistent formats & outcomes silently degrade decision-making and downstream processes.
And then, you have three different answers for the same question. It just makes stakeholders lose trust in the data because they don't understand why there are three different answers to the same question. They don't know what to depend on.
~ Madison Schott, Analytics Engineer | Exclusively on Analytics Heroes by Modern Data 101 🎧
Outcome of fulfilling Goal
By embedding real-time validation and anomaly detection, organizations prevent costly errors, ensure seamless data operations, and maintain confidence in their analytics and AI initiatives.
🎯 Validate Business Logic, Transformations, & Semantics
Metrics, models, and transformations must align with business objectives to ensure meaningful insights.
Why this Goal
Flawed business logic results in inaccurate KPIs, misaligned reporting, and misguided strategic decisions. Without continuous validation, errors in transformations, semantic inconsistencies, and misconfigured models can distort outcomes and reduce trust in data products.
Every data initiative should tie back to business value, focusing on how our efforts contribute to revenue generation or cost reduction. This approach ensures that our data efforts align with organizational goals, enhancing our understanding and communication of the value we provide.
~ Ryan Brown, Sr. Data Engineer Architect | Exclusively on Analytics Heroes by Modern Data 101 🎧
Outcome of fulfilling Goal
A solid validation framework ensures that business logic remains consistent, transformations reflect true operational realities, and analytics provide actionable, high-confidence insights.
🎯 Monitor System Performance & Scalability
A data product must perform efficiently and scale seamlessly under growing workloads. Continuous monitoring also boils down to better features aligned to the user’s practical needs.
Why this Goal
As data volumes increase, performance bottlenecks emerge, leading to slower processing, delayed insights, and frustrated users. Without proactive monitoring, organizations risk system failures, unoptimized queries, and unexpected downtime.
Managing six data products for Wayfair's global supply chain involved a decentralized approach…Our monitoring system was integrated into Slack for real-time alerts, helping us address issues promptly. Maintenance typically took up 10-20% of our time, with the majority of our focus on developing new (Data Product) features.
~ Sitian Gao, Analytics Lead & Mentor | Exclusively on Analytics Heroes by Modern Data 101 🎧
Outcome of fulfilling Goal
Continuous performance testing equals data products that remain fast, responsive, and cost-effective at scale, supporting growing user demands and evolving business needs without disruptions.
🎯 Strengthen Governance, Security & Compliance
Data must be secure, governed, and compliant with industry regulations.
Why this Goal
Weak governance exposes organizations to security breaches, regulatory fines, and reputational damage. Without proper controls, unauthorized access, data leaks, and compliance violations become unmanageable business risks.
Data governance frameworks must be tailored to the organization's specific needs, acknowledging that every company has unique systems and resources. Data governance isn’t just about restricting access; it’s about ensuring the right people can access the data. The success of any governance framework ultimately relies on the human element, with data governance ambassadors playing a pivotal role in its effectiveness.
~ Sheila Torrico, Technical Product/Program Manager | Exclusively on Analytics Heroes by Modern Data 101 🎧
Outcome of fulfilling Goal
Strong governance frameworks, automated security checks, and regulatory compliance validation ensure data integrity, protect sensitive information, and maintain trust with customers and stakeholders.
🎯 Enable Continuous Deployment
Data products should evolve rapidly without breaking functionality.
Why this Goal
Slow, manual deployment processes introduce risks, delay innovation, and increase operational friction. Without automated testing and CI/CD, each update becomes a potential failure point, reducing agility and responsiveness.
A data product can't be built in isolation—it requires continuous input to be effective. A metric is only as useful as the context it provides, so ensuring its stability means keeping an eye on its underlying dimensions and continuously refining them.
~ Matthew Weingarten, Sr. Data Engineer | Exclusively on Analytics Heroes by Modern Data 101 🎧
Outcome of fulfilling Goal
Automated validation and deployment pipelines allow data teams to iterate quickly, minimize downtime, and accelerate time to value—ensuring that data products stay cutting-edge without sacrificing stability.
III. Components of Data Product Testing Strategy
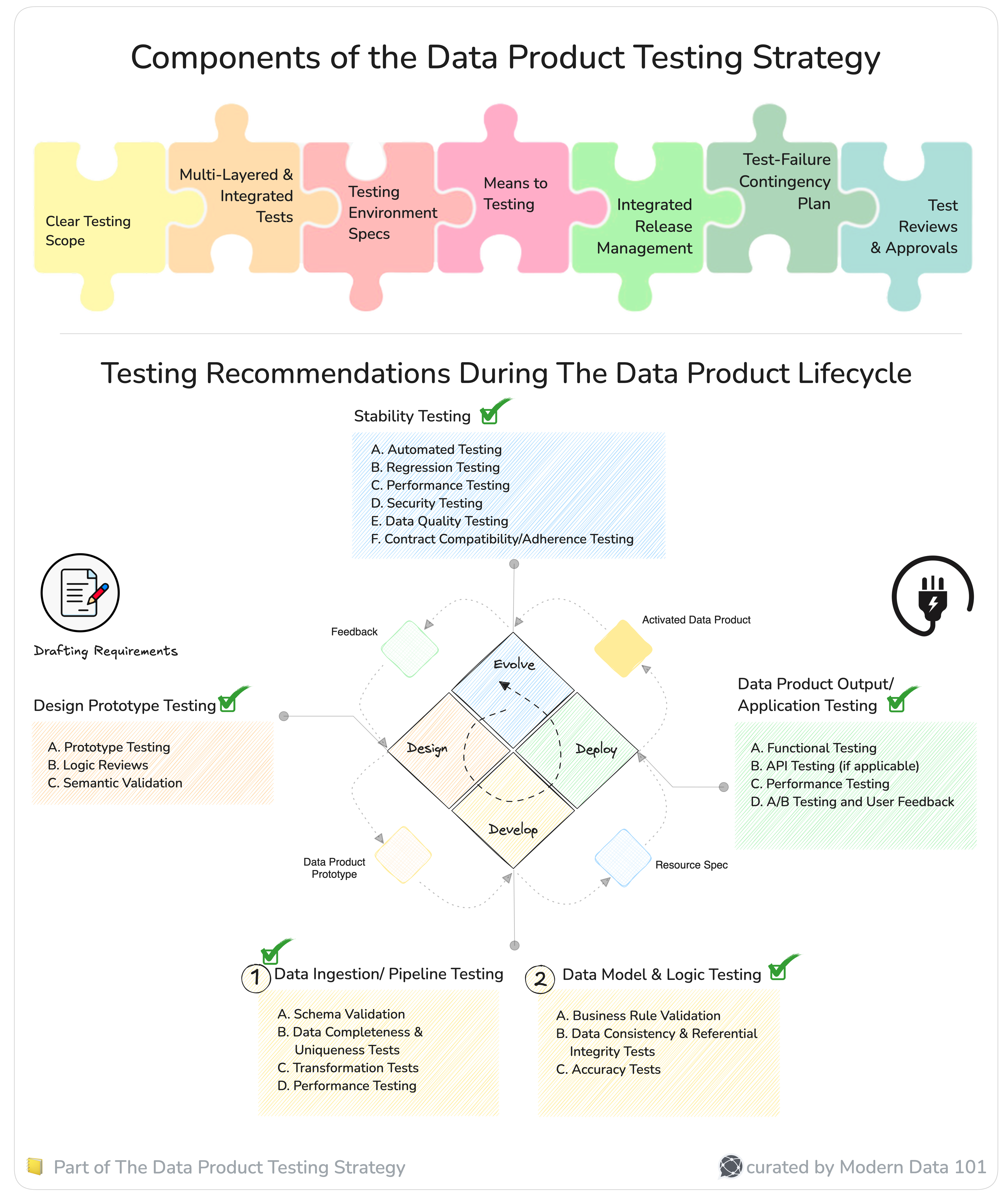
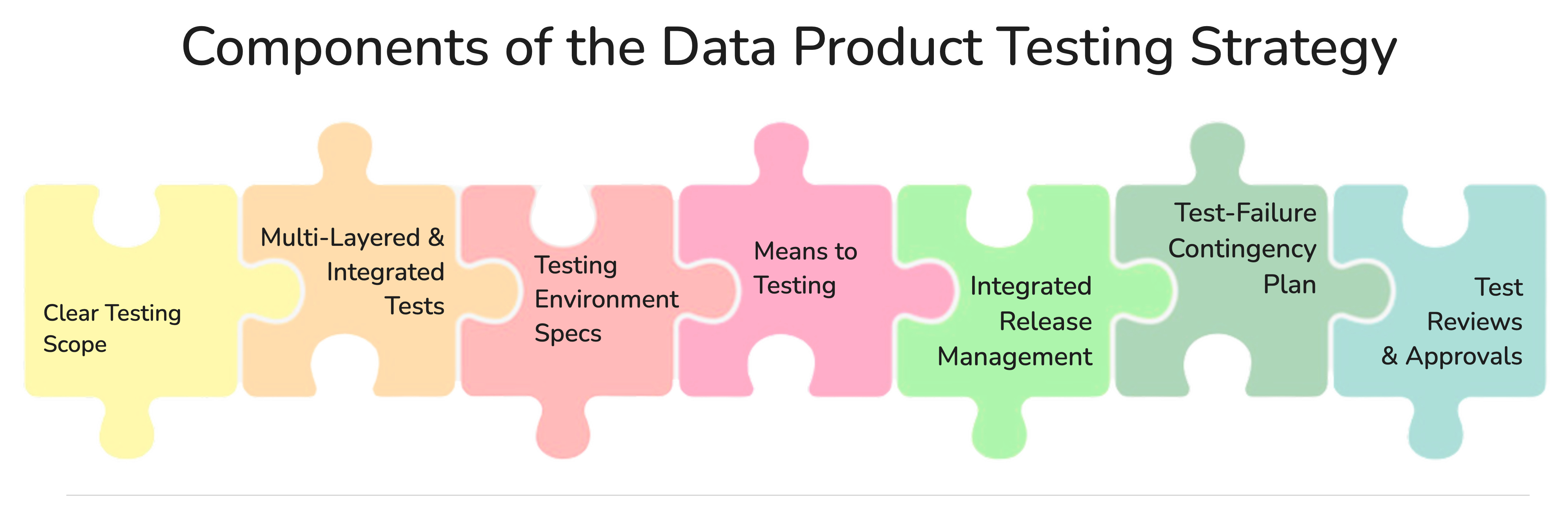
The seven key components of Data Product Testing Strategy include:
- Clear Testing Scope
- Multi-Layered Integrated Tests
- Testing Environment Specs
- Means to Testing
- Integrated Release Management
- Test-Failure Contingency Plan
- Test Reviews & Approvals
1: Clear Testing Scope
Clear ownership and decision-making structures are the backbone of an Effective Data Product Testing Strategy. Without a well-defined scope, teams operate in a fog—unsure who validates critical data transformations, signs off on model accuracy, or ensures compliance. This ambiguity breeds inefficiency, delays, and missed risks.
The best data organizations treat approval workflows as a strategic lever, assigning domain experts to review the aspects they understand best—data engineers for pipeline integrity, analysts for business logic, and compliance teams for security.
The result? Faster decisions, fewer bottlenecks, and a seamless bridge between testing and deployment.
2: Multi-Layered & Integrated Tests
A single testing layer is a single point of failure.
A robust data product testing strategy is built like a well-architected system—resilient, redundant, and deeply integrated.
- Unit Testing guarantees correctness at the transformation level
- Integration Testing ensures seamless interactions across data flows
- Regression Testing prevents changes from breaking existing functionality
- Automated Testing embeds quality into CI/CD pipelines, and
- Data Monitoring & Observability transforms static validation into a dynamic, real-time safeguard.
Without these layers working in unison, data systems remain fragile—susceptible to silent failures, costly rollbacks, and eroded business trust.
3: Testing Environment Specs
Testing in an environment that doesn’t mirror production is like test-driving a car in a parking lot and assuming it will perform on the highway.
Many failures—schema mismatches, unexpected latencies, or scalability bottlenecks—don’t reveal themselves until a system is under real-world pressure.
Yet, too many organizations test against unrealistic conditions, leading to a false sense of security. A best-in-class strategy treats the testing environment as a training ground for production, ensuring that every edge case, data volume, and integration is stress-tested before real users and systems rely on it.
4: Means to Testing
Testing should not be an afterthought—it must be woven into the fabric of data workflows. When validation exists outside the data platform, testing becomes a bottleneck rather than an enabler.
The most mature data teams embed testing directly within their orchestration layers, transformation tools, and CI/CD pipelines, allowing for real-time validation at every stage of the data product lifecycle.
This integration creates a system where errors surface early, issues are diagnosed in context, and testing evolves alongside development—rather than slowing it down. Such highly integrated testing environment and means are feasible on Unified Platforms, that enable common interfaces for different entities in the data ecosystem to easily talk to each other.
📝 Related Reads
Evolution of the Data Landscape: Fragmented Tools to Unified Interfaces | Issue #13
5: Integrated Release Management
A misaligned testing and release strategy creates two equally bad scenarios: either innovation is throttled by endless checks, or unverified changes are rushed into production.
The sweet spot lies in a testing framework that adapts to the organization’s release velocity—where automated checks provide rapid feedback loops, business-critical validations occur without friction, and no release happens without necessary approvals.
Organizations that master this balance unlock continuous deployment without sacrificing data quality, allowing them to innovate without fear of breakage.
6: Test-Failure Contingency Plan
Testing failures aren’t setbacks; they’re signals. But without a structured response, failures turn into fire drills—forcing teams into reactive mode, causing downtime, and increasing operational risk.
The best data organizations don’t just plan for failures; they design for resilience. Establish a failure response plan to convert testing breakdowns into learning loops. Automated rollback mechanisms, intelligent alerting systems, and structured root cause analysis transform test failures into learning loops, strengthening data systems over time.
In context of Product Testing, when failures are expected, prepared for, and systematically analyzed, they become a competitive advantage rather than a liability.
7: Test Reviews & Approvals
Data integrity isn’t achieved through good intentions—it’s the result of disciplined validation and governance. Without a structured test review and approval process, organizations risk deploying unreliable data products that undermine trust and decision-making.
High-performing teams create a multi-tiered approval structure, where technical, business, and compliance stakeholders each validate data from their unique vantage points. This ensures that data is not just technically correct but also aligned with business intent, regulatory standards, and operational needs—
creating an ecosystem where quality is a given, not a gamble.
IV. What Aspects of the Data Product Should Be Considered for Testing
A data product is not a monolith—it behaves more like a microservices system, where infrastructure, code, data, and performance continuously interact—as smaller building blocks. Testing must reflect this complexity, ensuring that no aspect becomes a blind spot.
The best data teams don’t just validate data correctness; they test the entire system’s resilience across multiple dimensions.
A. Infrastructure: Platform Stability & Policy Adherence
The foundation of any data product is its platform—where storage, compute, access policies, and scaling strategies determine reliability. Testing must validate infrastructure configurations, security policies, and compliance requirements to prevent unexpected failures or vulnerabilities. Without this, even well-tested data pipelines can break due to environmental inconsistencies.
📝 Related Reads
Building Data Platforms: The Mistake Organisations Make | Issue #54
Speed-to-Value Funnel: Data Products + Platform and Where to Close the Gaps
The Essence of Having Your Own Data Developer Platform | Issue #9
B. Code: Unit & Data Validation Tests for Transformation Accuracy
Every data transformation is a potential point of failure. Testing at the code level—through unit tests for logic correctness and data validation tests for transformation outputs—ensures that data is manipulated as intended. This prevents silent errors, where incorrect transformations propagate unnoticed, corrupting downstream insights.
📝 Related Reads
Data Pipelines for Data Products | Issue #29
dbt for Data Products: Cost Savings, Experience, & Monetisation | Part 3
C. Data: Model Integrity, Validation, and Governance
Raw data is meaningless without context, structure, and policy enforcement. Testing must validate:
- data models (schema integrity, business logic adherence)
- data validations (missing values, anomalies, data drift)
- data serving (API responses, access control)
- data policies (privacy, retention), and
- data quality (consistency, completeness, freshness).
Organizations that fail to test these aspects risk unreliable insights, compliance violations, and broken user experiences.
📝 Related Reads
Data Product Prototype Validation ✅
D. Performance: Query Speed, Uptime, and Refresh Rate
A data product is only valuable if it’s performant at scale. Testing must assess query response times (ensuring fast analytics), uptime and availability (minimizing downtime risk), and data refresh rates (ensuring real-time or batch updates align with SLAs). Without performance testing, a perfectly accurate dataset can still be useless due to sluggish response times or stale insights.
📝 Related Reads
Monitoring Lifecyle during Data Product Evolution ♻️
V: What, When, How: Testing During the Data Product Lifecycle
Let’s take a glimpse at how the above components come into play when the Data Product Lifecycle stages are at play. What particular testing requirements are applicable and how to implement them.
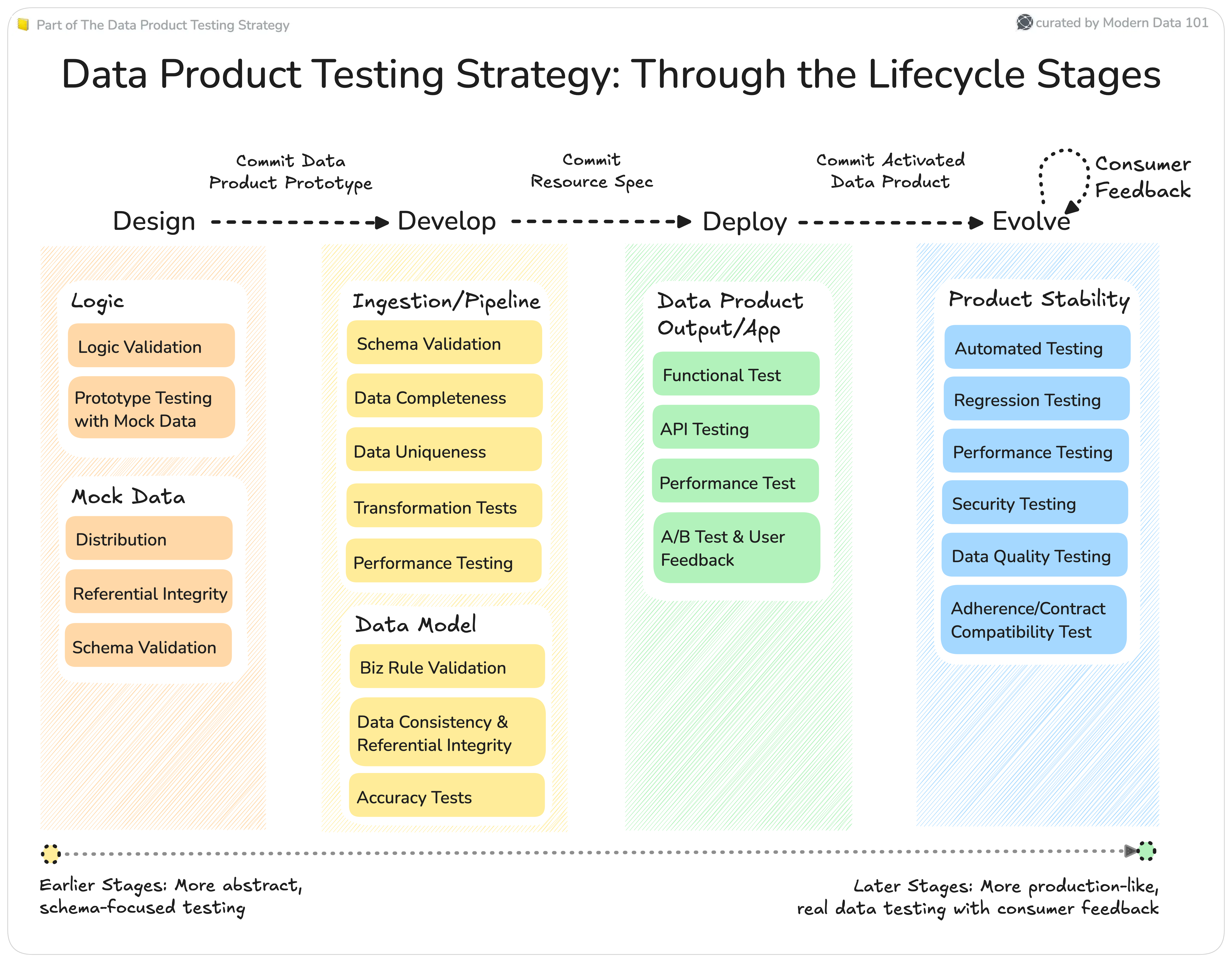
Testing at Design Stage
During data product design, precisely define Service Level Objectives (SLOs) and Service Level Indicators (SLIs) to ensure data product value. This involves identifying output ports (query interfaces, APIs, files) and specifying data quality expectations for each, including data freshness, business rules for integrity, and acceptable error margins. This crucial step is supported by a structured discovery exercise, as seen in the ThoughtWorks Data Mesh Acceleration Workshop. This exercise, which is focused on usage patterns, enables teams to collaboratively define SLOs by understanding consumer expectations, trade-offs, and the business impact of the data product. This ensures that data products meet consumer needs and deliver consistent value.
The design stage results in the Data Product Prototype: a semantic model complete with context, requirements (which would also be used for test cases), and definitions. Once the design prototype is ready, it’s critical to validate if the connections, keys, and overall data product model actually work when data starts flowing through the model.
Plugging in the physical data sources is a potential blunder at this stage. It would unnecessarily loop in the data engineer and get them stuck in frustrating iterations of data mapping every time a flaw is discovered in the prototype. Exploring and discovering data and then transforming it for the right mapping is a longer process and, therefore, inefficient unless the prototype is declared a working model.
This calls for sophisticated mock data as a service. In one of our internal surveys on analytics engineers, we found that generating data for testing was surprisingly challenging, given the intricacies and patterns of different domain data on which insight-generating pipelines depend like a stack of dominoes.
This is why mock or synthetic data needs to closely imitate the original data that will be plugged into the prototype (say, CRM data from industry ‘x’). For instance, the Accounts and Contacts data should simulate the 1:N relationship, or foreign keys and primary keys should be populated in sync, etc. Naturally, mock data must also be tested.
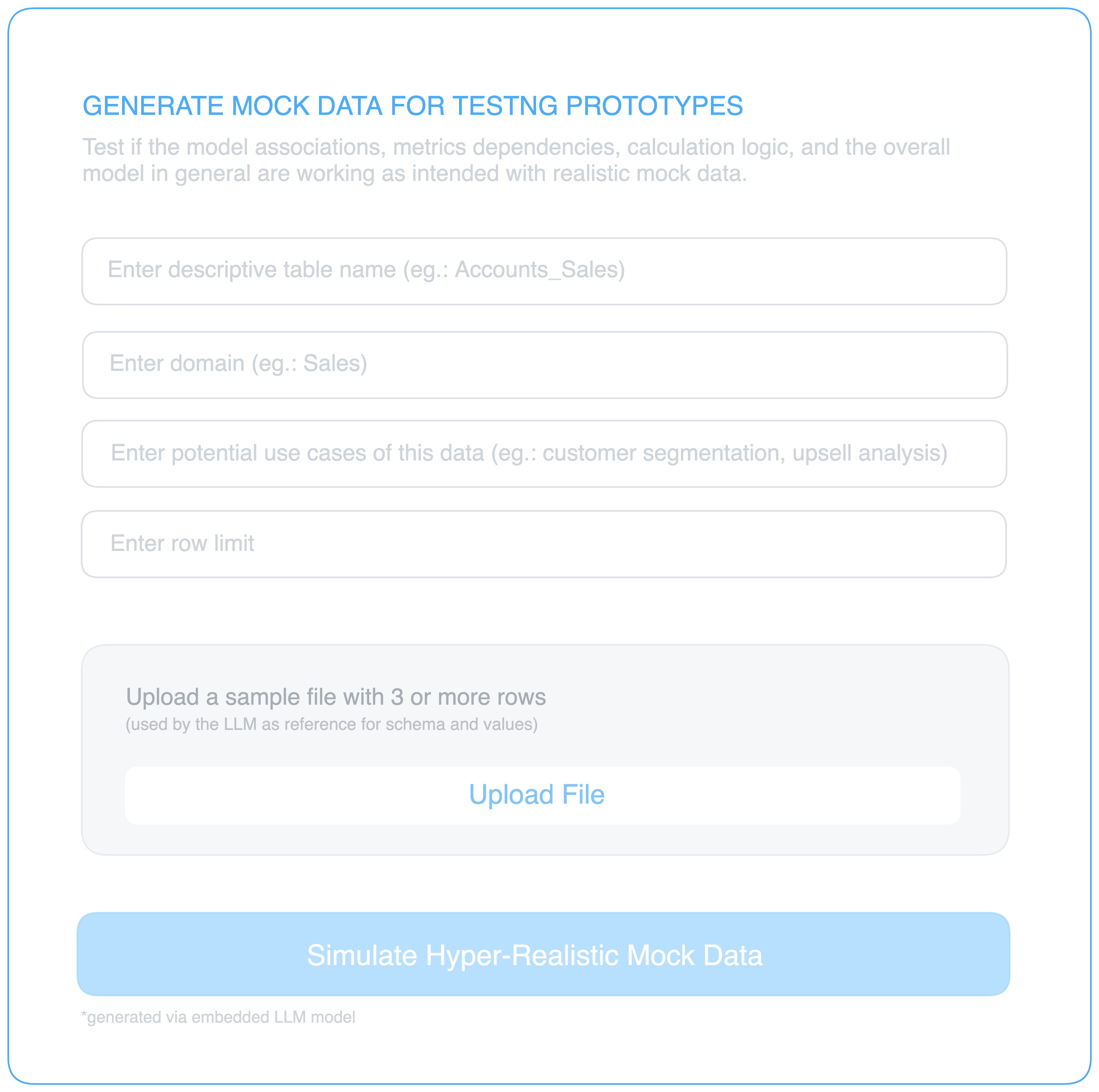
Given the advent of advanced AI during the last couple of years, realistic mock data for testing purposes is no longer a frustrating rule-based and iterative cycle. We’ll not go into the details behind such AI algorithms in the scope of this piece.
📝 Further references
- Building an Amazon.com for Your Data Products by Barr Moses, Manisha Jain, and Pablo Porto
- Some of the above excerpts from: Data Product Prototype Validation ✅ by Modern Data 101 Authors
Testing at Develop Stage
Data Ingestion/Pipeline Testing
Focus: Data Availability, Validity, and Transformation
A. Schema Validation, including Data Type and Format Validation
Purpose
Ensure that incoming data conforms to the expected schema (data types, column names, etc.). This prevents errors downstream.
Implementation
Create automated tests that check the schema of incoming data against a predefined schema. Tools like Great Expectations, Deephaven, and custom scripts can be used.
Integration in Build
Run these tests immediately after the data ingestion steps in the data pipeline.
B. Data Completeness and Uniqueness Tests
Purpose
Verify that essential fields are not missing (null values) and that data is unique where required (e.g., unique customer IDs).
Implementation
Use SQL queries, data quality frameworks (Great Expectations, etc.), or custom scripts to check for null values, duplicate records, and data completeness.
Integration in Build
Implement these tests after data is ingested and transformed.
C. Data Transformation Tests (ETL/ELT)
Purpose
Ensure that data transformations (e.g., cleaning, aggregation, filtering) within the pipeline produce the correct results.
Implementation
- Unit tests: Test individual transformation functions or steps in isolation. Use frameworks like pyTest (Python) to create unit tests, including mock data.
- Integration tests: Verify the entire transformation process. Compare the output of a pipeline step with an expected output based on a predefined input and transformation logic.
Integration in Build
Apply these tests after each transformation step in your pipeline.
D. Performance Testing
Purpose
Ensure the data ingestion and transformation process is efficient and scalable.
Implementation
Measure the processing time and resource consumption (CPU, memory) of each pipeline stage. How to?
Integration in Build
Run these tests periodically as the data product evolves or when significant changes are introduced.
Data Modeling & Logic Testing
Focus: Accuracy, Relationships, and Business Rules
A. Business Rule Validation
Purpose
Ensure the data models and business logic accurately reflect the business rules and requirements.
Implementation
Translate business rules into testable scenarios. For example, "If a customer is a gold member, they receive a 10% discount." Write tests that verify the data model's adherence to these rules. This might involve SQL queries, data validation frameworks, or custom scripts.
Integration in Build
Test rules during data transformations and/or at the point where business logic is applied (e.g., in a data warehouse or a data application).
B. Data Consistency and Referential Integrity Tests
Purpose
Ensure data relationships are maintained (e.g., foreign key constraints) and that data across different tables or sources is consistent.
Implementation
Use SQL queries to check for orphaned records (e.g., a customer record referencing a non-existent order) or inconsistencies between related data. Data quality frameworks can also automate these checks.
Integration in Build
Perform these tests after data loading and transformation.
C. Accuracy Tests
Purpose
Validate the accuracy of calculations, aggregations, and derived metrics.
Implementation
- Compare to source: If possible, compare the data product's output to the data from the source system(s).
- Manual verification: Run manual checks for a representative sample of data to verify the accuracy of the data.
- Test with known data: Create test datasets with known outcomes and use them to validate the calculations performed by your data product.
Integration in Build
This should happen after data transformation and model building.
Testing at Deploy Stage
Data Product Output/Application Testing
Focus: Functionality, User Experience, and Performance)
A. Functional Testing
Purpose
Ensure that the data product's features and functionalities work as expected from the user's perspective.
Implementation
Write test cases that cover all user interactions with the data product. This includes checking user interfaces, API endpoints, report generation, and data visualizations.
Integration in Deploy
In the Deploy phase, especially when UI elements or APIs are deployed.
B. API Testing (if applicable)
Purpose
Verify that the data product's APIs work correctly, return the expected data, and handle error conditions gracefully.
Implementation
Use API testing tools like Postman, Insomnia, or automated testing frameworks to send requests to your APIs and validate the responses.
Integration in Deploy
After the API is deployed.
C. Performance Testing
Purpose
Ensure the data product responds quickly and efficiently, especially under heavy load.
Implementation
Use load testing tools to simulate concurrent user requests and measure response times, throughput, and resource consumption.
Integration in Deploy
Regularly as features are added or usage increases.
D. A/B Testing and User Feedback
Purpose
If your data product has alternative design options or features, use A/B testing to compare different versions and collect user feedback to identify which performs better and is more usable.
Implementation
Implement A/B testing platforms or analyze user behavior data to measure the success of alternative versions.
Integration in Deploy
After some initial feature deployment.
Testing at Evolve Stage
The Evolve phase focuses on continuous improvement, optimization, and innovation to further enhance the product and provide value to customers.
In the Evolve phase, data product testing practices should focus on ensuring that the product remains stable, scalable, and secure while also continuing to evolve and improve. Here are some testing practices to consider:
- Automated Testing: Implement automated testing scripts to run on a regular schedule, ensuring that the product remains stable and functional after new changes or updates are deployed.
- Regression Testing: Perform regression testing to ensure that new changes or updates do not break existing features or functionality.
- Performance Testing: Conduct performance testing to ensure that the product can handle increased traffic, user growth, or changes in data input.
- Security Testing: Perform security testing to identify vulnerabilities such as exposure of PII and ensure that the product remains secure wrt compliance, including data and access policy validations
- Data Quality Testing: Automate data quality testing to ensure that the data provided to users is accurate, complete, and relevant with adherence to promised SLO.
- Contract Compatibility/Adherence Testing: Conduct compatibility testing to ensure that the product honors the contracts in place to ensure usability by consumers/other data products in the ecosystem
VI. Facilitating Data Product Testing Strategy
Focus: Business metrics/measure of success across different aspects of a Data Product (ensuring data product delivers value at all times). How:
A. Role of Data Contracts, SLO/SLIs
Goal: Ensuring the data contracts are adhered to, making data products rightful citizens on the mesh.
Data Contracts
As data mesh adoption continues to gain momentum, decentralized domain teams are empowered to deliver value faster through data products. To maximize their potential and cater to diverse use cases, these data products are often reused within or across domains. However, this reuse scenario creates a need for coordination between data product teams, known as 'providers' and 'consumers’, to ensure a seamless data mesh experience.
To enable data products to evolve independently without disrupting their consumers, a crucial practice has emerged: defining and utilizing Data Product Contracts.
A well-known data product specification out there is Bitol.
Data Product Contracts serve as formal agreements outlining the expectations, data interfaces, and constraints between providers and consumers. They ensure that both parties understand the terms of engagement, including how data will be delivered, the conditions for its use, and the responsibilities of each team. By defining these contracts, organizations can promote transparency, facilitate smoother integrations, and allow for the independent evolution of data products without compromising consumer needs.
📝 Related Reads
Role of Contracts in a Unified Data Infrastructure | Issue #11
SLO/SLI
*below is a direct excerpt from one of Manisha’s previously published pieces
The developer will define the service-level-asset definition of OAM spec consisting of SLO and SLIs, the platform creates the monitors based on the specification.
A service-level objective (SLO) is a target that a service or data product should meet to be considered reliable and valuable to its users.Service-level indicators (SLIs), meanwhile, are the metrics used to measure the level of service provided to end users.
We defined SLIs for each SLO of the data product. Some of them are as described below:
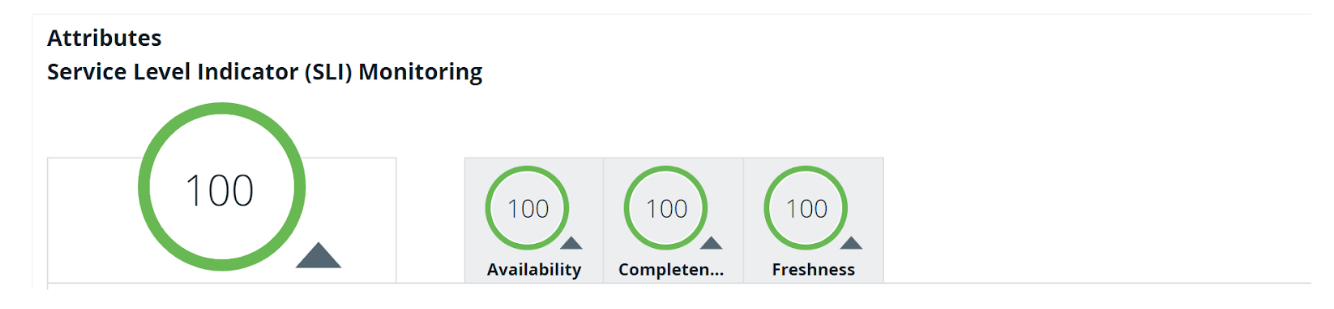
Availability
This refers to the uptime of the underlying data set. It’s verified by checking the existence of the underlying table in the lakehouse/warehouse. The SLI Uptime Indicator is calculated based on an average amount of time in which data product has been available for the past few days. For example, the hourly data availability indicator over a 20-day rolling period.
Completeness
This helps us ensure that the row count should not be below the known historic threshold. The SLI Volume Indicator is calculated by comparing the total number of rows of the last update with the average of the past few days update.For example, the SLI has a passing value (in percentage) which represents that whenever the data product has been updated the number of records in it have never fallen above five percent from its last update in the past 20 days.
Freshness
This refers to the refresh time of the underlying data set. It’s verified by checking the update/refresh time on the underlying table in storage. The SLI Freshness Indicator is calculated based on the average freshness of data for the past few days. For example, the SLI for a daily refresh has a passing value (in percentage) which represents the freshness of the data product in the past 20 days for every day.
It’s worth noting that namespaces (logical workspaces) isolate/separate a collection of monitors that you are able to define. Monitors from different namespaces are isolated from each other. This helps to:
- Avoid conflict or override monitor configurations across data product teams.
- Manage monitors across different environments in different pipelines.
B. Role of Data Platform
A self-serve platform is a first class principle for data mesh. Its prime objective is to expedite the delivery of data products and shield data product developers from infrastructural complexity.
This allows them to focus on the creation and maintenance of data products to add business value, rather than solving the same data engineering problems again and again.
~ Manisha Jain in A streamlined dev experience in Data Mesh: Platform team’s POV
From Testing and Automation pov, the platform can provide a template to define data quality tests along with monitoring spec. The data product team is responsible to define, and platform ensures the spec is provisioned to run the tests and monitor the KPI and alert on deviation there via automation in a self-serve manner.
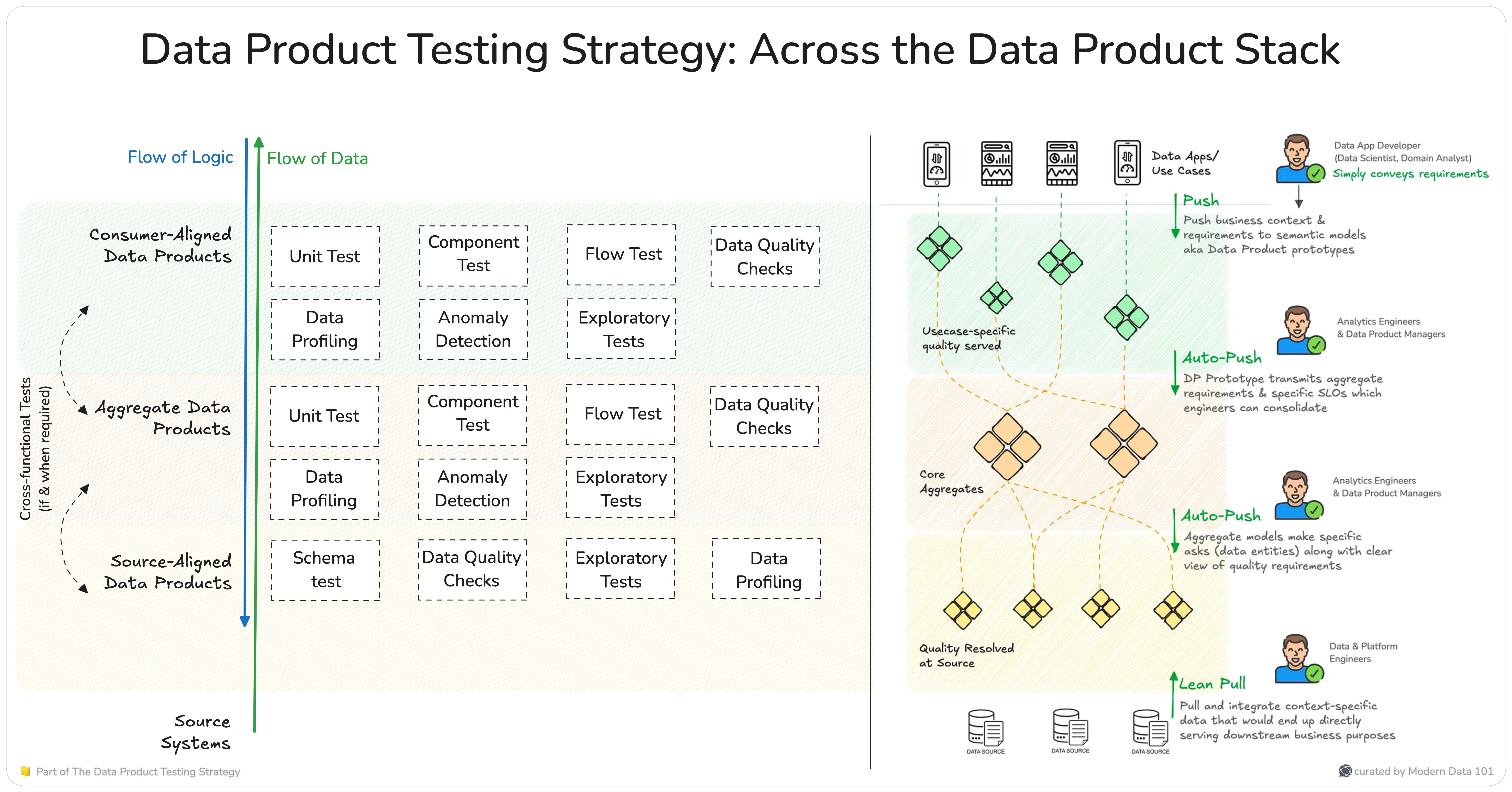
The platform doesn’t just enable templatised tests for stages in the Data Product Lifecycle but also facilitates tests across the three tiers of the Data Product Stack (Consumer-Aligned Data Products, Aggregate Data Products, Source-Aligned Data Products).
📝 Related Reads
Data Products: A Case Against Medallion Architecture
Source-aligned Data Products
Tests to ensure that raw data from source systems is correctly exposed and meets expected quality standards:
- Schema contract test (validate schema consistency)
- Data Quality checks (ensure integrity, completeness, and accuracy)
- Exploratory test (validate raw data anomalies)
- Data Profiling (analyze distributions and patterns)
Aggregate Data Products
Tests to validate that aggregated domain-level concepts are correctly derived and structured:
- Unit test (validate transformations and aggregations)
- Component test (test individual data processing components)
- Flow test (verify data flows and dependencies)
- Data Quality checks (ensure aggregation accuracy)
- Data Profiling (analyze patterns in aggregated data)
- Exploratory test (detect unexpected values or trends)
- Anomaly detection (identify outliers in derived data)
Consumer-Aligned Data Products
Tests to ensure that data products serve their intended use cases with performance and accuracy:
- Unit test (validate final data output logic)
- Component test (ensure transformations and calculations are correct)
- Flow test (validate end-to-end data movement)
- Data Quality checks (maintain completeness and consistency)
- Data Profiling (analyze data for consumer needs)
- Exploratory test (final validation before consumption)
- Anomaly detection (flag inconsistencies before end-user applications)
*Cross-functional tests could involve policy validations to proactively resolve policy conflicts, performance tests, and security tests (since data moves outside the bounds of origin data products)
Reference Samples of Monitoring and Quality Specs on Data Developer Platforms
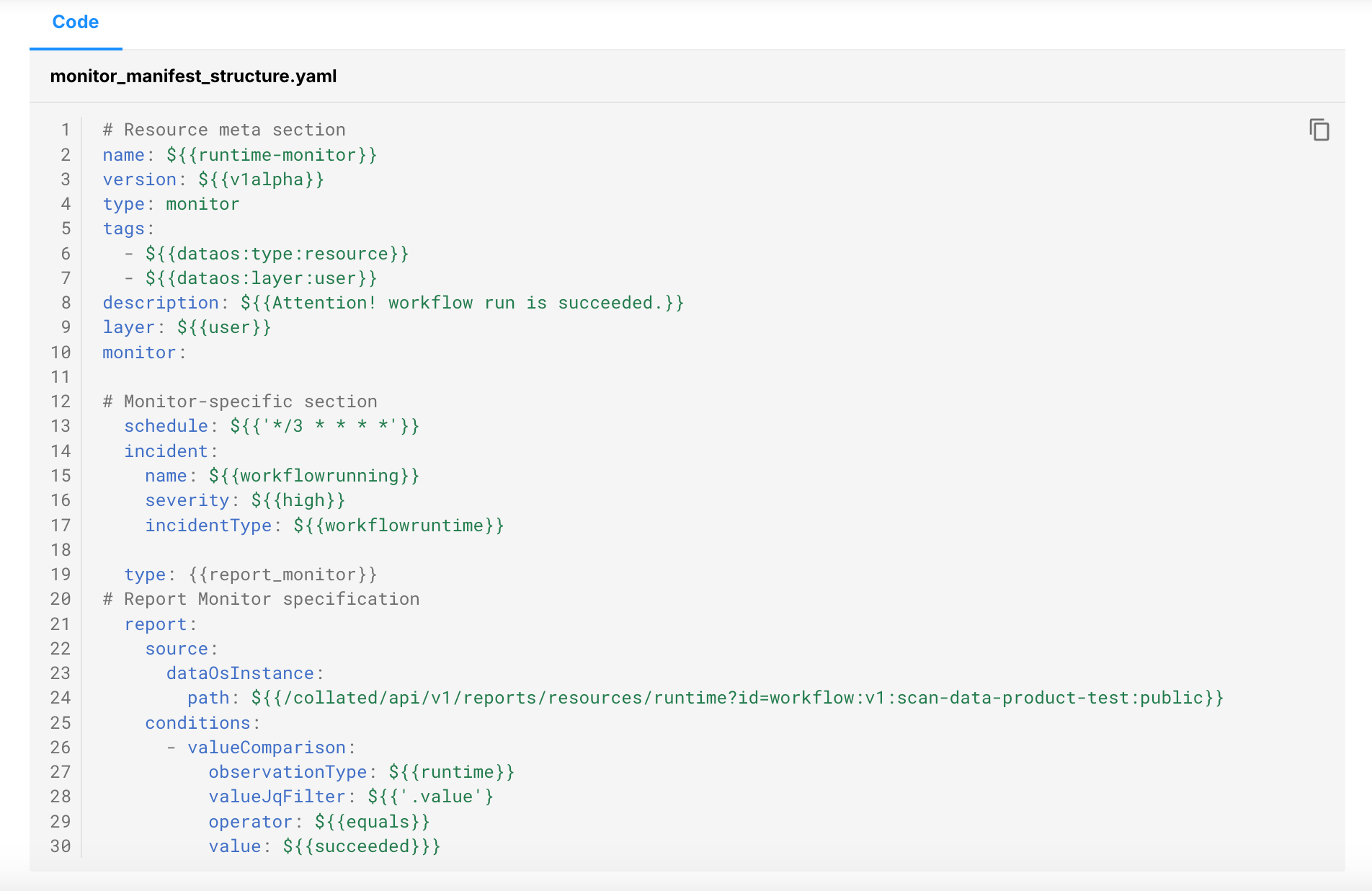
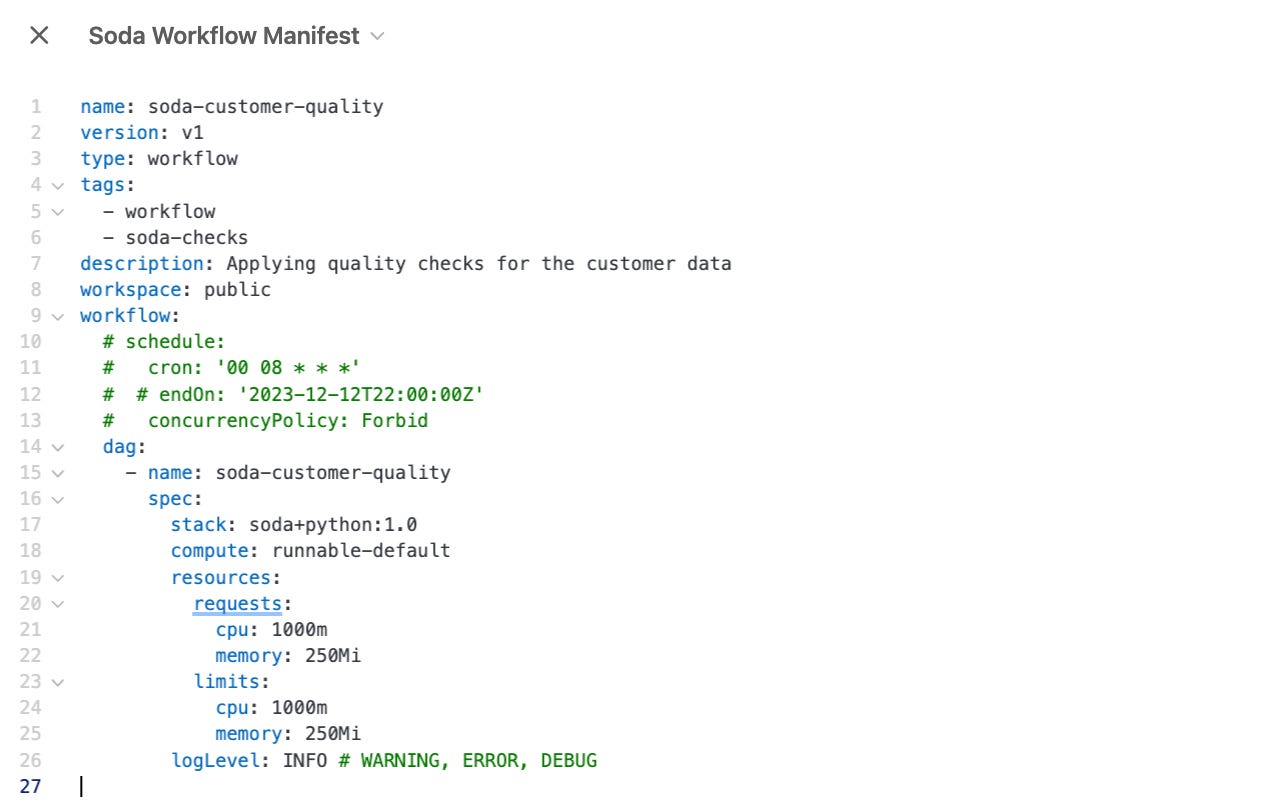
C: Testing Dashboards to Boost Adoption
If users question the quality, relevance, or reliability of the data, adoption stalls. Testing dashboards serve as an adoption accelerator—offering transparency into the health of the data product by exposing key trust signals. Instead of treating testing as an internal process, high-performing teams surface these trust indicators directly to users, fostering confidence and driving usage.
A well-designed testing dashboard should not just report errors—it should provide a comprehensive view of data quality, trustworthiness, and relevance. By integrating a data product hub or a data product marketplace, users gain visibility into:
- Quality Metrics: Completeness, consistency, freshness, and validation checks.
- Trust Indicators: Source lineage, transformation history, governance status, and compliance adherence.
- Relevance Scores: Fitness-for-use assessments based on business context, domain alignment, and downstream impact.
📝 Related Reads
The Data Product Marketplace: A Single Interface for Business
Inspired by Martin Fowler’s Architectural Fitness Functions, these dashboards can embed automated checks that continuously validate the data product’s fitness against pre-defined quality and trust criteria. This shifts testing from a static, pre-release exercise to a live, evolving assurance mechanism, where real-time evaluations ensure that data products remain optimized, compliant, and relevant over time.
Dashboards as Adoption Drivers
By transforming data product testing into a user-facing, decision-enabling tool, organizations don’t just improve quality—they accelerate trust and adoption. When users can see, understand, and verify the reliability of the data they consume, they move from skepticism to engagement, unlocking the full value of the data product.
VII. Future Trends in Data Product Testing
From Reactive to Autonomous Assurance
The next evolution of data product testing is not just about catching errors—it’s about predicting, preventing, and autonomously resolving them. As data ecosystems grow in complexity, traditional testing approaches fall short. The future is driven by AI, automation, and seamless governance integration, transforming testing from a checkpoint into a real-time, self-adaptive process.
AI-Driven Testing and Anomaly Detection
Manual rule-based validation is no match for the scale and dynamism of modern data products. AI-driven testing leverages machine learning models to detect anomalies, drifts, and inconsistencies before they impact decision-making. Instead of waiting for users to report issues, AI proactively flags outliers, learning from historical patterns to refine its detection accuracy. This shift enables predictive quality assurance, where failures are prevented rather than merely identified.
Self-Healing Pipelines: Automating Issue Resolution
The future of data engineering is self-healing infrastructure. When an issue is detected—whether a schema change, a pipeline failure, or an unexpected data shift—self-healing systems will automatically diagnose and implement corrective actions. This means:
- Dynamic schema evolution: Adapting to new data structures without breaking downstream workflows.
- Automated rollbacks: Reverting to the last known good state when anomalies are detected.
- Resilient transformations: Adjusting data logic in real time based on predefined governance rules.
By embedding auto-remediation mechanisms, self-healing pipelines significantly reduce downtime and free up engineering teams from firefighting mode.
Integration of Testing with Data Governance
Governance is no longer a separate function—it must be deeply embedded into the Data Product Testing framework. Future data product testing will surface live quality metrics, validate access policies, and enforce compliance controls in real time. This means:
- Continuous data validation: Ensuring that data products meet pre-defined trust and quality thresholds.
- Automated policy enforcement: Preventing unauthorized access and detecting non-compliant usage patterns.
- Real-time lineage tracking: Providing visibility into how data is transformed and consumed.
This convergence between testing and governance ensures that data is not just technically correct but also ethically and legally sound, making compliance a built-in feature rather than a reactive burden.
The Future: Autonomous, Trust-Centric Data Products
The next frontier of data product testing is autonomous quality assurance—where AI, automation, and governance seamlessly work together to deliver trustworthy, resilient, and compliant data products. As organizations scale their data ecosystems, the winners will be those who embrace intelligent, self-correcting (“healing”), and governance-aligned testing strategies.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 🖋️

Connect with me on LinkedIn 👋🏻

Connect with me on LinkedIn 🙌🏻

Find me on LinkedIn 🤜🏻🤛🏻

Find me on LinkedIn 🫶🏻








