





TABLE OF CONTENT
Just as Blake saw the universe in a grain of sand, great scientists have often looked for clues to vast and complex problems in the small, familiar phenomena of daily life. Newton drew insights about the heavens by juggling wooden balls. Einstein contemplated a boat paddling upriver. Von Neumann pondered the game of poker. ~ Sylvia Nasar
Just like that, the age-old observation that simplicity just works better applies up and down from our plane of observation, which is usually the daily life. Does it also work better for our work, aka the mammoth data industry and its many tracks and offerings?
Simplicity & Why It Works
Way back in the 1960s, Kolmogorov changed the way we understood ‘simplicity’ and ‘complexity’. They defined in concrete equations how exactly simplicity could be consciously created even for apparently complex solutions or outcomes unless the defined outcome is random.
Unabashedly, we’ll start with a geeky example.

Take a string S (a sequence of symbols), and then consider the length (in symbols) of the shortest computer program capable of generating S. For example, the loop “for i=1 to 1000: print '1'” prints a string of 1000 characters, but the program itself contains only 26; this string is highly compressible.
By contrast a “typical” random string of 1000 characters (e.g. “3938382…”) can’t be compressed in this way, although it can be expressed by a program that is itself about 1000 characters long (e.g. “Print '9486390348473969683…'”, which has 1008 characters).
More generally, a string that contains regularities or patterns—of any form that can be expressed in the computer language—can be faithfully reproduced by a short program that takes advantages of these patterns, while a relatively complex or “random” string cannot be similarly compressed (or de-complexified). ~ Extract from “The simplicity principle in perception and cognition”, published in NIH
In essence, the principle of simplicity calls for repeatable patterns.
What is another name for a repeatable pattern? Productisation.
What is productisation also? An approach/tool that helps to relatively delegate, dissipate, or redirect good amount of effort.
The loop “for i=1 to 1000: print '1'” is a product that helps the user to relatively delegate, dissipate, or redirect good amount of effort → the pattern is the product that the user codes in just 26 characters and also has the flexibility to tweak it only once to produce much larger and, therefore, “apparently” more complex strings or outcomes
A very interesting point to note so we can join the dots later → A more random string, on the other hand, cannot be condensed down to a set pattern, therefore carrying the same, in fact, higher complexity over to the production side (1000+8 characters).

Also note how the solution for the random string is ”fixed”, while the one for the product is embedded with variables that move along with the user’s requirements (fed into the “product” through xyz interface).
How does it all relate to the realm of data?

Let’s go back to our Projects vs. Products analysis.

The Product Approach brings down seemingly complex solutions and data stacks into:
- Complexity reduction 💡
- Repeatable patterns for scale ♻️
- Cleaner fits with the actual use case and changing user patterns (user-centric data solutions) 🎮
- Ergo, less waste and faster route to repeatable cash inflow 💰
A More Meaty View of the Product Way
A Product is anything that makes life a little easier for the user. And is naturally dictated by the user’s needs. In a single sentence, a product is for the user and by the user.
In the context of the above sections, a product is also something that identifies patterns and enables repeatability to make solutions simpler. Minimising randomness and fixedness to make the solutions more effectively aligned to users.
But how to build for the user and involve them in the production process?
In our case, the user is any business persona simply looking to make better decisions with data. For example, a sales representative wanting to quickly decide on a Monday morning which three customers he wants to target for upsells during the week.
Involving the user to productise data for high-quality, governed, and purpose-driven insights →
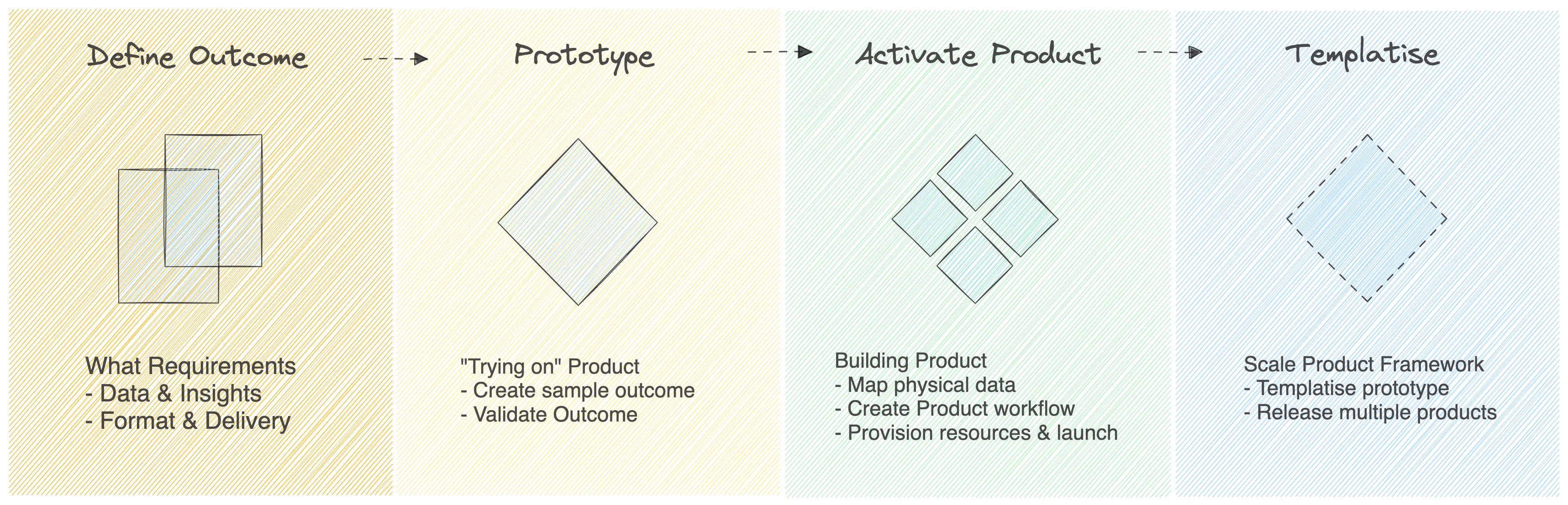
- Let the business define the desired Outcome
- What: Data and Insights required (can be loosely defined)
- How: Format & Delivery (quality, security) of the data & insights (consumption preferences)
—
- Build a Prototype for the user to “try on”
- Create a sample desired outcome (e.g.: a logical data model with industry-specific data mocks)
- Validate the ‘actionability’ of insights & consumption preferences
- Reiterate with feedback until the prototype is finalised
—
- Activate the Prototype → Live Data Product
- Discover relevant entities from the source ecosystem
- Map the nodes in the prototype to the physical data
- Write the workflow that runs the data product (e.g.: calls to transformation workflows, policies, quality checks, etc.)
- Test and debug in staging + Validate with User
- Deploy to available interfaces (catalogs, marketplaces, etc.)
—
- Scale the Data Product
- Use the prototype template to create products in other domains/use cases
- Establish a series of products that customers can “purchase” insights from
- Analyse usage patterns and decommission/update unused products/insights
—
This is the model-first approach to building data products, which amply takes in the user’s feedback through logical data modeling or prototyping data products, allowing users to even experience the value of the prototypes before the actual build effort kickstarts. Like an architect finalises the blueprint before laying eyes on a brick.

This approach also makes plenty of space to leverage repeatability through the prototype:
- Identifying key usage patterns and channels
- Identifying key entities/tables for a domain that users bank upon
- Identifying the frequent associations between these tables
- Identifying the measures against the tables that users tend to use the most
- Identifying the most sought-after SLOs against the data and insights
- Reproducing the same foundation for other use cases which draw from the same or similar data
In short, the Product Mantra for Data rolls out like this:

To Wrap Up, Simplicity Trickles Down to the Very Last Layer of Data Citizens. Not Just the User End.
When it becomes simple for users to integrate themselves into the production process, it also becomes simple for data developers to create a product that consistently aligns with the business. This roll-out is orchestrated through a self-serve platform on top of your existing infrastructure.
The Data Mesh Paradigm defines a self-serve platform along the following parameters:
…to make analytical data product development accessible to generalist developers, to the existing profile of developers that domains have, the self-serve platform needs to provide a new category of tools and interfaces in addition to simplifying provisioning.
A self-serve data platform must create tooling that supports a domain data product developer’s workflow of creating, maintaining and running data products with less specialized knowledge that existing technologies assume; self-serve infrastructure must include capabilities to lower the current cost and specialization needed to build data products.
The role of a Self-Serve Platform in rolling out simplicity in data across different planes of usage in the data stack:

Build vs. Buy
We don’t want to do a typical build vs. buy analysis here as the strategy of building vs. buying data solutions is completely dependent on organisational choices and core competencies. Instead, we’ll share how you could either build or buy based on your strategic pick.
Building a self-serve platform requires a dedicated platform engineering team with, give or take, at least a couple of years of development effort. But that could be the right choice for organizations that have high core competencies in platform engineering or have established something similar that needs enhancement.
The data mesh paradigm neatly lists the capabilities of a self-serve platform. To develop the same, you could refer to datadeveloperplatform.org, a community-driven initiative to standardise the capabilities, blueprint, and overall platform fundamentals of self-serve platforms. You can learn more about it here.
For buying a self-serve platform solution, it could be tricky to navigate the distinction between a repackaged stack of tools and the true self service capability. We’ll refrain from listing down vendor options to keep this piece truly unbiased, but feel free to email us community@tmdc.io to discuss potential options. We’ll be happy to share more on what we are building as well as other great options that fit the frame.
Still around? Look out for a special edition release this Friday featuring some of your favourite data leaders and practitioners! Follow MD101 on LinkedIn or Twitter to be the first ones here, or subscribe for free 🔔
📖 Related Reads
1. Building your Sausage Machine for Data Products 🌭: Less Tech, More Strategy
2. 🎯 End-to-End Guide to Building Data Products









