




TABLE OF CONTENT
Editorial 🤓
We found a very good summation of modern software principles on GeeksforGeeks, which undoubtedly hosts a rich basket of resources. We did a double-take on noticing a clean alignment with Data Product Development on Data Developer Platforms (DDPs).
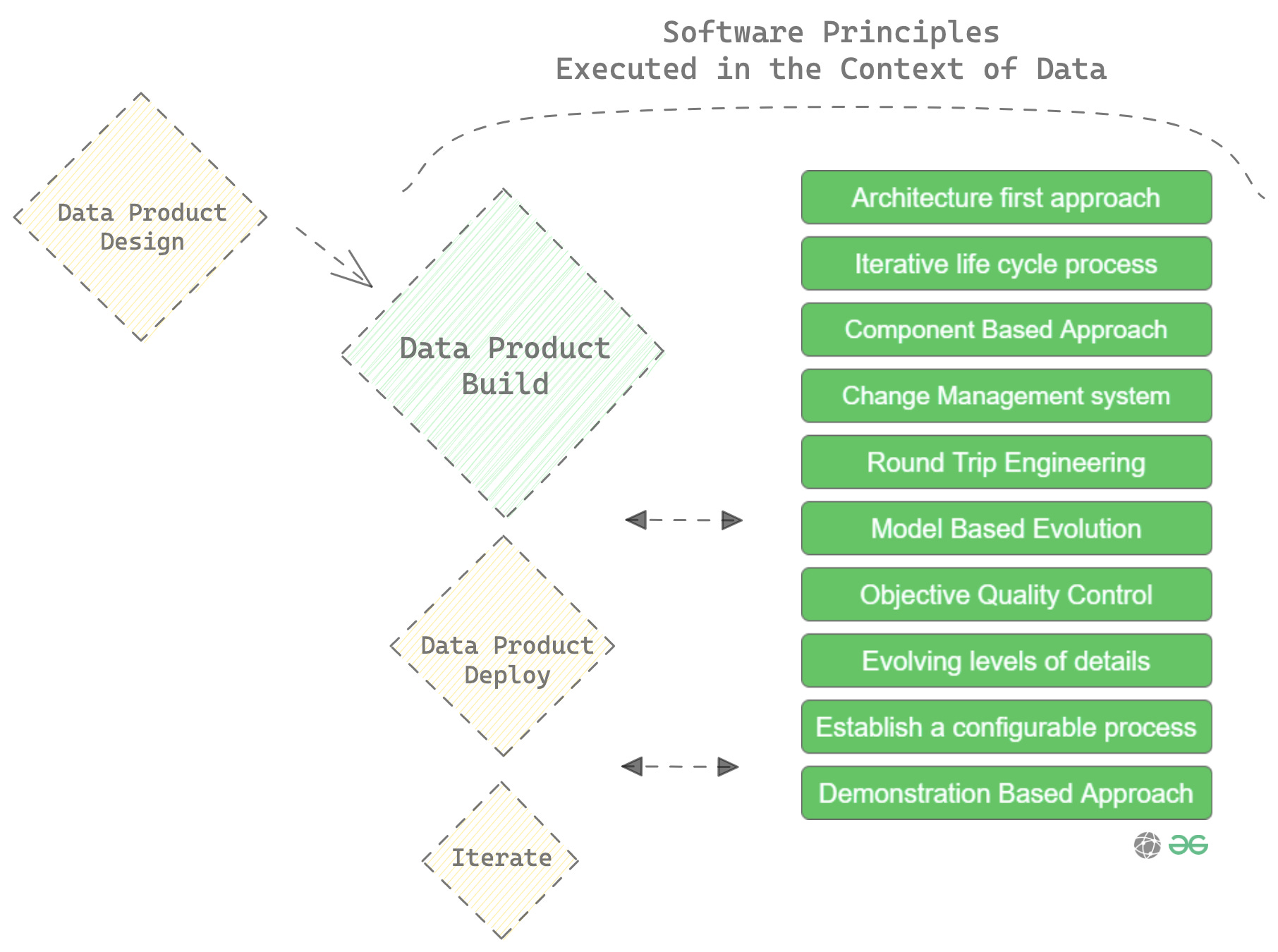
A view of these principles in the context of data
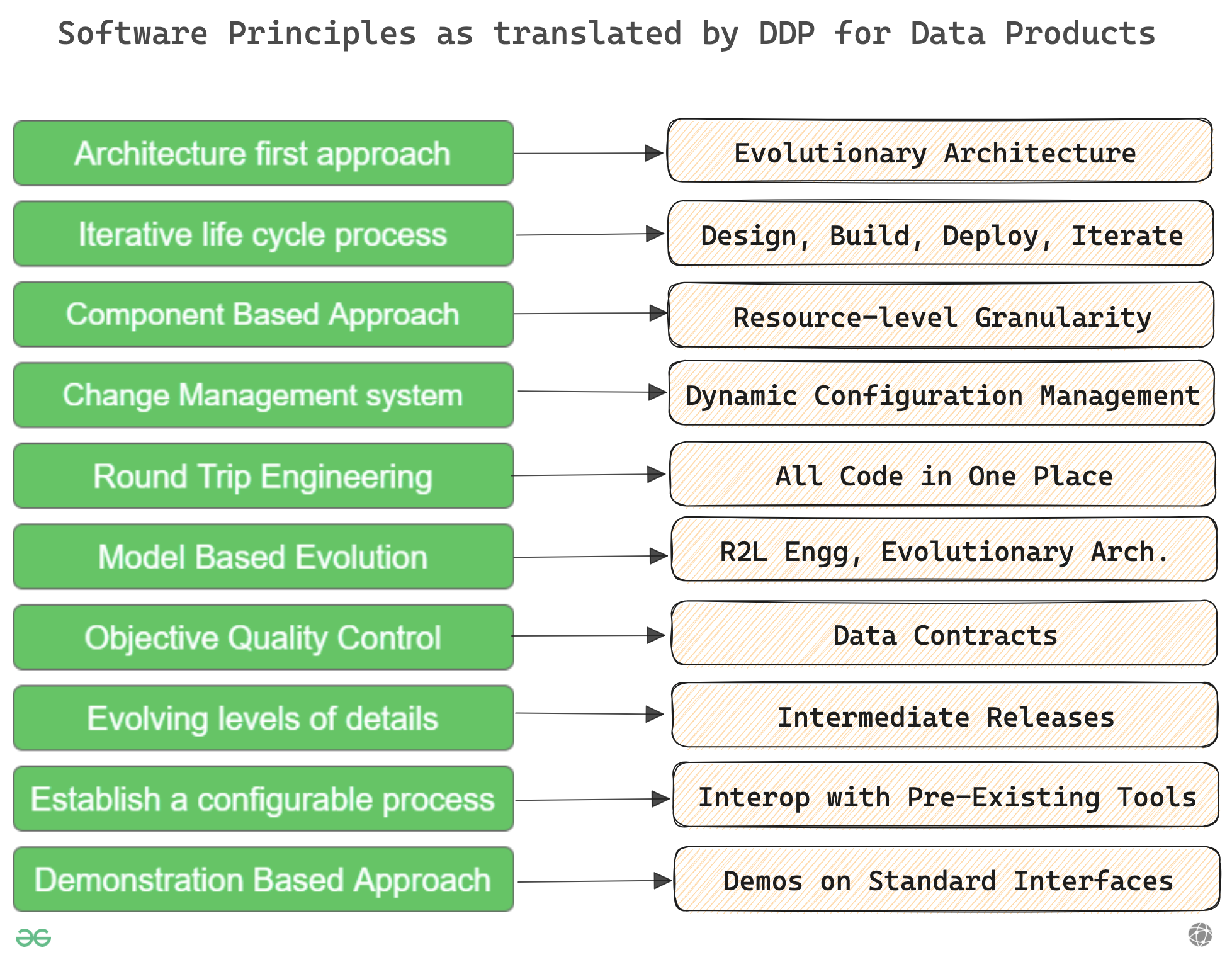
Architecture first approach
Develop a strong, reliable architecture for data, resilient to a high degree of change. This manifests in the form of emphasis on the Evolutionary Architecture for Data.
Iterative life cycle process
Agile yet risk-tolerant. In the Data Product context, this cycle is divided into four parts: Design, Build, Deploy, and Iterate, and it’s a consistent loop to ensure low cognitive load on data developers with respect to pipeline plumbing.
Component-Based Approach
Reuse of previously defined functions in the form of components is a widely used and successful s/w development approach. In the context of data, the same is true when it comes to DDP’s resource level granularity that allows data developers to define fundamental functions as resources and reuse pre-defined functions across different operations.
Change Management System
Every software management system inherently comes with a change management system. Data Developer Platforms go one step further to bring in advanced change management or Dynamic Configuration Management. In short, it means all dynamic changes, more frequently observed in the data space, can be managed through a single workload specification file instead of managing multiple files or dependencies.
Round Trip Engineering
Round trip engineering synchronises related artefacts such as resources, source code, models, config files, documentation, and more. In data, this is achieved through right-to-left engineering in DDPs, where an entire channel of artefacts is synchronized to common business objectives as defined by a semantic data model.
Essentially, a data product DAG that allows devs to interlink all associated artefacts in a manageable stream. In other words, all code in place. Every change across dependencies is reflected through single-hop parametric changes in config files due to intelligent synchronisation.
Model-Based Evolution
Model-based evolution is the ability to evolve the software model over time, and when it comes to data, this becomes even more pertinent given the high frequency of change due to the indefinite nature of data.
DDP for data products supports this through the same 1/ right-to-left engineering model and 2/ evolutionary architecture. R2L engg enables businesses to iteratively improvise with no centralised bottlenecks and evolutionary arch. helps all dependent teams to ease into new features and functions that data products introduce without disrupting legacy dependencies.
Objective Quality Control
One of the primary pillars of data products is data quality, enforced through data contracts at multiple endpoints, including output ports (most important), ingestion plane, and transformation writes.
Evolving Levels of Details
This boils down to intermediate and incremental releases over big bang releases, which forces data citizens to aggressively adapt to new technologies and processes. DDP’s Bundle artefact is built as versionable data products, where each version pushes a granular level of change that’s digestible by all dependencies in the domain.
Establish a Configurable Process
One bucket does not fit all. One process also doesn’t fit all and must be configurable. DDP is adaptable to the economic and political constraints of an organisation. For instance, an org may have invested millions in popular SaaS licenses, such as Snowflake, DBT, Atlan, or Immuta.
DDP doesn’t force devs to scrap all pre-existing efforts but instead enables these third-party tools to improve quality and governance and minimise time to data products with distributed orchestration of compact, boilerplated, and scalable pipelines.
Note: DDP best practices suggest gradual migration to unified capabilities instead of opting a fragmented data ecosystem indefinitely.
Demonstration Based Approach
Consistently demo and educate end-users when new features and capabilities are released to improve data software and also increase usage over time. This is even more easily achieved through common DDP interfaces, which end users are free to experiment with without the cognitive load of jumping across third-party interfaces.
Community Space 🫂
Michael J. Lever’s article “The data delivery checklist: principles to design data products” shows how to battle any overwhelm or cognitive overload of building data products. He suggests an effort vs. impact analysis to prioritise efforts, which is especially important during the design and build stage of the data product lifecycle.
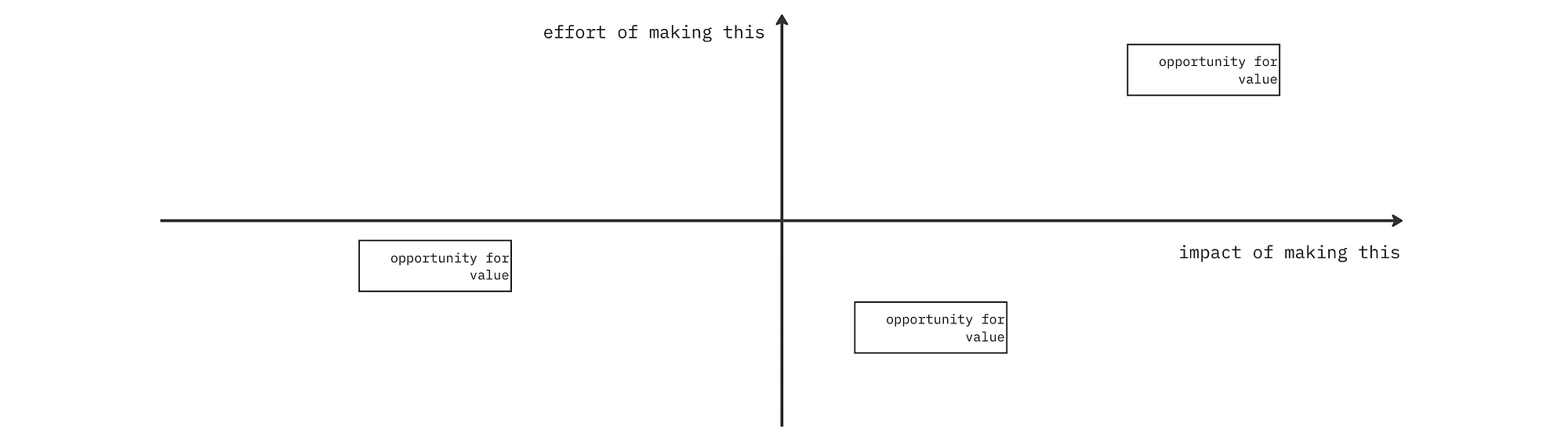
We recommend using the BCG matrix for such a prioritisation activity. We stress a lot on this activity and embed it directly into our Data Product Strategy.
While it may seem like a no-brainer, very few teams actually implement this exercise due to process and habitual constraints. The article is quite extensive and later delves into mapping user experiences, examples, error-prone paths to data products, and more.
Ergest Xheblati recently made quite a strong point on building systems. In summary: A fragmented approach to building holistic systems is a no-go. Instead, align all the relevant moving parts (dis-align the constraining bits) to unified goals.

Barr Moses and ThoughtWorks recently wrote a thorough perspective on Data Products: “Building An Amazon.com For Your Data Products”. A strong excerpt from the piece that we completely align with:
The two best ways to fail at creating valuable, reusable data products are to develop them without any sense of who they are for and to make them more complicated than they need to be.
One of the best ways to succeed is by involving business and product leadership and identifying the most valuable and shared use cases. Thoughtworks, for example, often identifies potential data products by working backwards from the use case using the Jobs to be done (JTBD) framework created by Clayton Christensen.
The article shares a bunch of more interesting angles, especially around SLOs, trustworthiness, and observability.
Upcoming Data Events 📢
CDAO Fall | Boston
The Premier In-Person Gathering for Data & Analytics Leaders in North America
Join your data & analytics peers from leading brands across North America as you discover the latest trends and challenges facing your role.
The event will present speakers from data domain including Joe Vellaiparambil (Chief Data & Analytics Officer - AXA), Prachi Priya(Chief Data & Analytics Officer - Publicis Groupe), Asha Saxena(Founder & CEO - Women Leaders In Data & AI), Kamal Distell(VP of Data, Analytics, & D.S. - Toyota), Tarun Sood(CDO - American Century), and many more such renowned folks.
Event Date: 4-5 Oct. 2023 | Mode: Offline | Register
DataNext Architecture | Europe
The Foundation of Data Driven Organisations
DataNext Architecture will deep dive into how organisations are using their architecture to create the foundation to become truly data driven. Showcasing how architecture underpins the value that an organisation derives from its data initiatives.
The summit will feature speakers from data domain including Dominik Schneider**(**Principal Architect: Data & Analytics - Merck Group), Mercedes Pantoja(Head of Applications and Data Architecture - E.ON), Daniel Suranyi(Lead Data Architect at European Central Bank),
Stuti Nigam (Solution Architect: Data &Analytics - Fello fresh), and many more.
Event Date: 5 Oct. 2023 | Mode: Online | Register
Thanks for Reading 💌
As usual, here’s a light breather for you for sticking till the end!

Follow for more on LinkedIn and Twitter to get the latest updates on what's buzzing in the modern data space.
Feel free to reach out to us to become a contributor or reply with your feedback/queries regarding modern data landscapes. We look forward to your much-valued input to the Editor.












{kind=link}