




TABLE OF CONTENT
TLDR:
A data infrastructure intending to support data products at scale should:
⚈ have a unified building-block approach to problem-solving
⚈ support interoperability with internal & external entities at different layers
⚈ enable ease of transition across contrasting planes in a data stack
⚈ be highly reactive to changes in data and requirements
⚈ be able to propagate capabilities and changes across the stack instead of. compartmentalizing the impact
⚈ surface atomic insights by identifying resonating patterns from across the data stack instead of restricting visibility within boundaries
If you’re sitting in an office building right now, try looking up. You’d either see a plain ceiling or a couple of pipes if your org is into that industrial design. Ever wondered what’s going on behind the scene?
These ceilings hide a whole world of wires and ventilation channels. But we are barely ever aware of them unless it’s that rare day in a year or two when the mechanic, electrician, or plumber comes in to fix or test these fittings. Often they work after or before office hours or during the holidays.
That’s exactly what the infrastructure piece of data products is supposed to be. You should never really have the need to know if it exists unless you’re the mechanic or the platform team. Data producers and consumers should sit relaxed under these ceilings and breathe in the clean, cool air under ample lighting while they strive to create value and impact with their day-to-day jobs.
Prevalent States: Wait in a queue to turn on the light
However, this isn’t what we are used to, right? Instead, we are used to toiling behind the scene and corresponding with the platform engineers on a regular basis to get the data going. Imagine having to iterate with your company’s mechanic daily to keep the light over your head running. That’s not all. You’d have to wait in a queue to talk to this super important personnel who is not just handling requests from you but working on almost every employee’s list of requests.
In such a situation, how can you expect to get the paperwork off your desk? What would’ve taken a day now takes several months.
That’s exactly what happens with the prevalent data stacks in organisations. Let’s understand that with a specific example of a data model.
Data Producers
Data producers are constantly stuck with rigid legacy models that reduce the flexibility of data production and hinder produce of high-quality composable data. Multiple iterations with data teams are often necessary to enable the required production schema and requirements.
Data Consumers
Data consumers suffer from slow metrics and KPIs, especially when the data and query load of warehouses or data stores increase over time. Expensive, complex, and time-taking joins to make the consumption process littered with stretched-out timelines, bugs, and unnecessary iterations with data teams. There is often no single source of truth that different consumers could reliably refer to, and thereafter, discrepancies are rampant across the outcome of BI tools. Consumers are the largest victim of broken dependencies, and sometimes they are not even aware of it.
Data Engineers
Data engineers are bogged down with countless requests from both producers and consumers. They are consistently stuck between the choices of creating a new data model or updating an old one. Every new model they generate based on unique requests adds to the plethora of data models they are required to maintain for as long as the dependencies last (lifetime). Updating models often means falling back on complex queries that are buggy and lead to broken pipelines and a bunch of new requests because of those broken pipelines. In short, data engineers suffer tremendously in the current data stack, which is not sustainable.
Infrastructure in a New Light: The Data Product Version
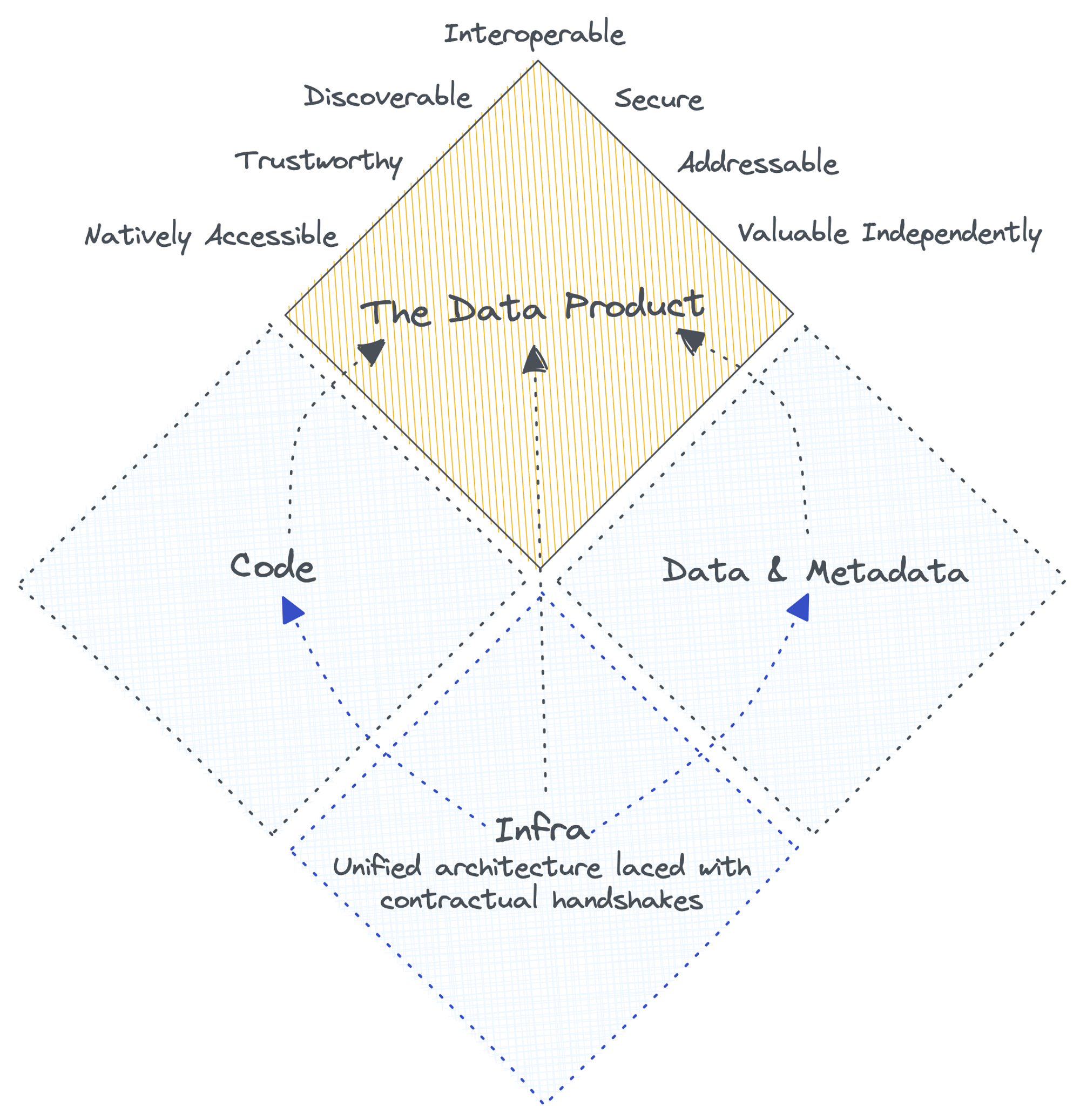
Data Product is not just about data. In technical terms, it is the containerised combination of data, metadata, code, and infrastructure. In business-y terms, it is a mechanism to provide readily consumable data that serves a specific purpose and establishes desired goals directly tied to business KPIs.
If you’re a data producer or consumer, you don’t need to care about the “mechanism”. Your jobs are way different from trying to turn on the light. So, ideally you should try and scroll over this article. It is the responsibility of the data engineering team or the CDO’s office to identify and set up such a mechanism that lets you work in peace.
However, if that’s something that you don’t see happening, it unfortunately comes down to you to evangelise this “mechanism” or bring the matter up to your building’s super, aka the CDO/CFO. Now that we have moved the “who” out of the way let’s get into what the data infrastructure from the perspective of a data product really is.
The infrastructure component of your data product is a cloud- and storage-agnostic architecture with unique building blocks or resources as its fundamental components. These building blocks are composed together and orchestrated through minimal configuration files to construct higher-order capabilities and solutions, omitting fat and redundant features across the stack and enabling change management at scale. The infrastructure has the ability to provision resources for isolated verticals, enabling containerisation or independence of data products or similar constructs.
The data infrastructure, from the perspective of data products, inherently supports a product-like experience. In other words, you can imagine that your data stack serves as a product instead of submitting to the chaos of complex pipelines and fragmented tooling ecosystems.
Objectives of the Infra Element in Data Products
The true and primary objective of the Infra Counterpart in Data Products is Unification. Unification of Purpose, Execution, and Experience. Why unification? Because it eliminates the overheads of fragmented tooling that comes with overly complex pipelines, messy overlaps in capabilities/features, and therefore, high cognitive overload for data developers.
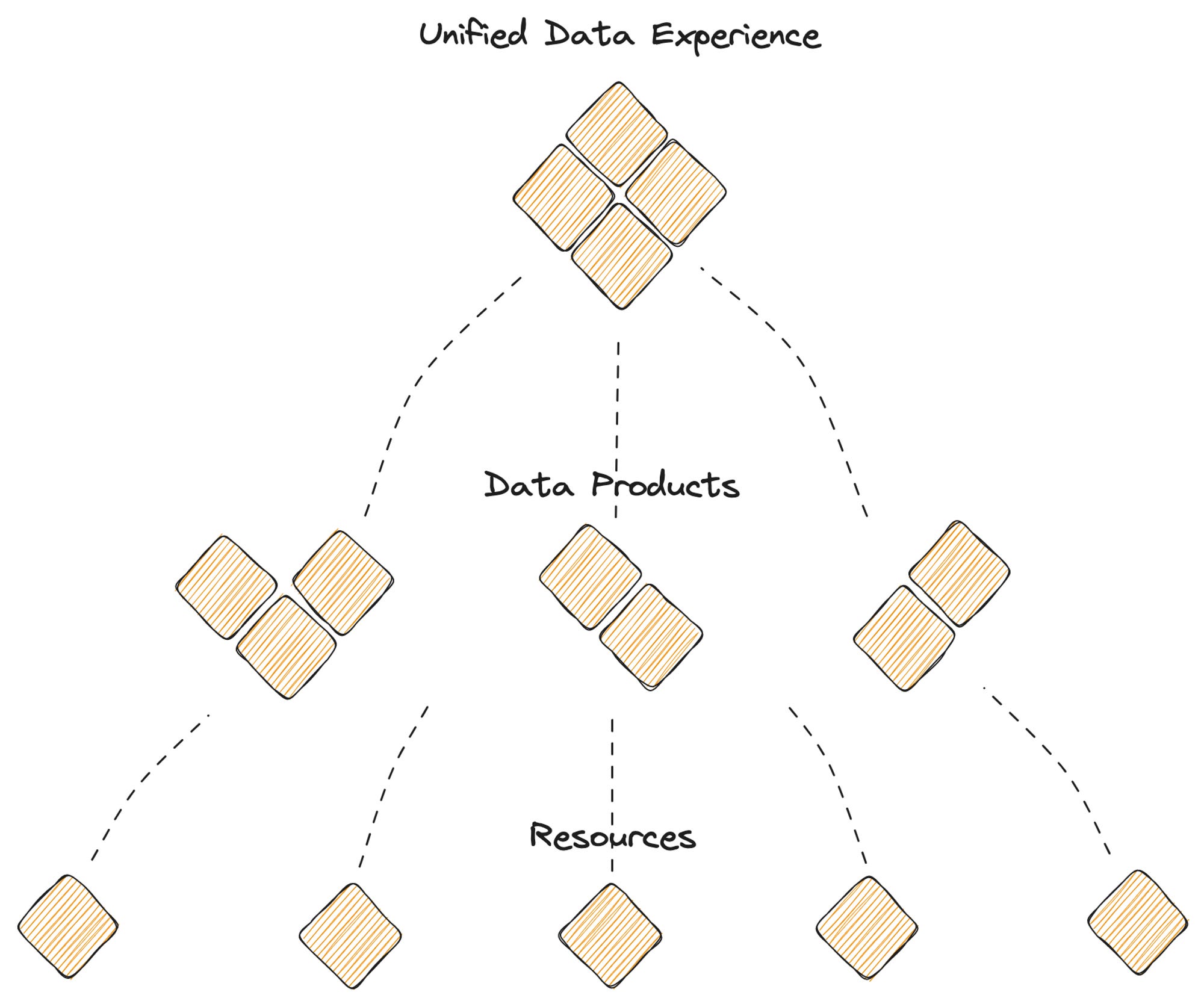
Unification is achieved through two design principles working in sync:
- Modularisation: Modularisation is established through the hierarchical model or the building-block-like approach. A unified infrastructure identifies unique atomic capabilities that cannot be compromised in a data stack and serves them as ready-to-implement resources. These resources can interoperate with each other and be composed together to form high-order solutions such as transformation and modeling. Examples of these fundamental resources include and are not limited to Storage, Compute, Cluster, Workflow, Service, Policy, Stack, and Secret.
- Dynamic Configuration Management: DCM is the ability to drive change at scale by trimming down points of change management to a single specification file. In prevalent data stacks, a single upstream change can lead to hundreds of tickets in downstream operations where the developers must manage multiple config files, dependencies, environment specs, and overall work against the tide of configuration drift. With DCM, which is also powered through the building-block-like design, all dependencies and configuration drifts can often be handled through a single specification file which abstracts underlying dependencies and complexities.
As more tools pop in to solve ad-hoc challenges, each tool increasingly develops the need to become independently operable (user feedback). For instance, two different point tools, say one for cataloguing and another for governance, are plugged into your data stack. This incites the need not just to learn the tools’ different patterns, integrate, and maintain each from scratch but eventually create parallel tracks. The governance tool starts requiring a native catalog, and the catalog tool requires policies manageable within its system.
You end up with two catalogs and two policy engines with different objectives. Now consider the same problem at scale, beyond just two tools.
While unified data stacks come with building blocks that can be put together to enable unique capabilities, it doesn’t restrict third-party integration. In fact, it facilitates them with an interface to propagate their capabilities. The objective is to omit capability overlaps.
In a duct tape data stack*, two different catalogs and policy engines would be created, operating in silos within the compatible boundaries of each tool. Whereas, in unified stacks, the catalog tool would gain visibility of policies and enable discoverability in the governance tool. The governance tool would be able to extend policies to the catalog items.
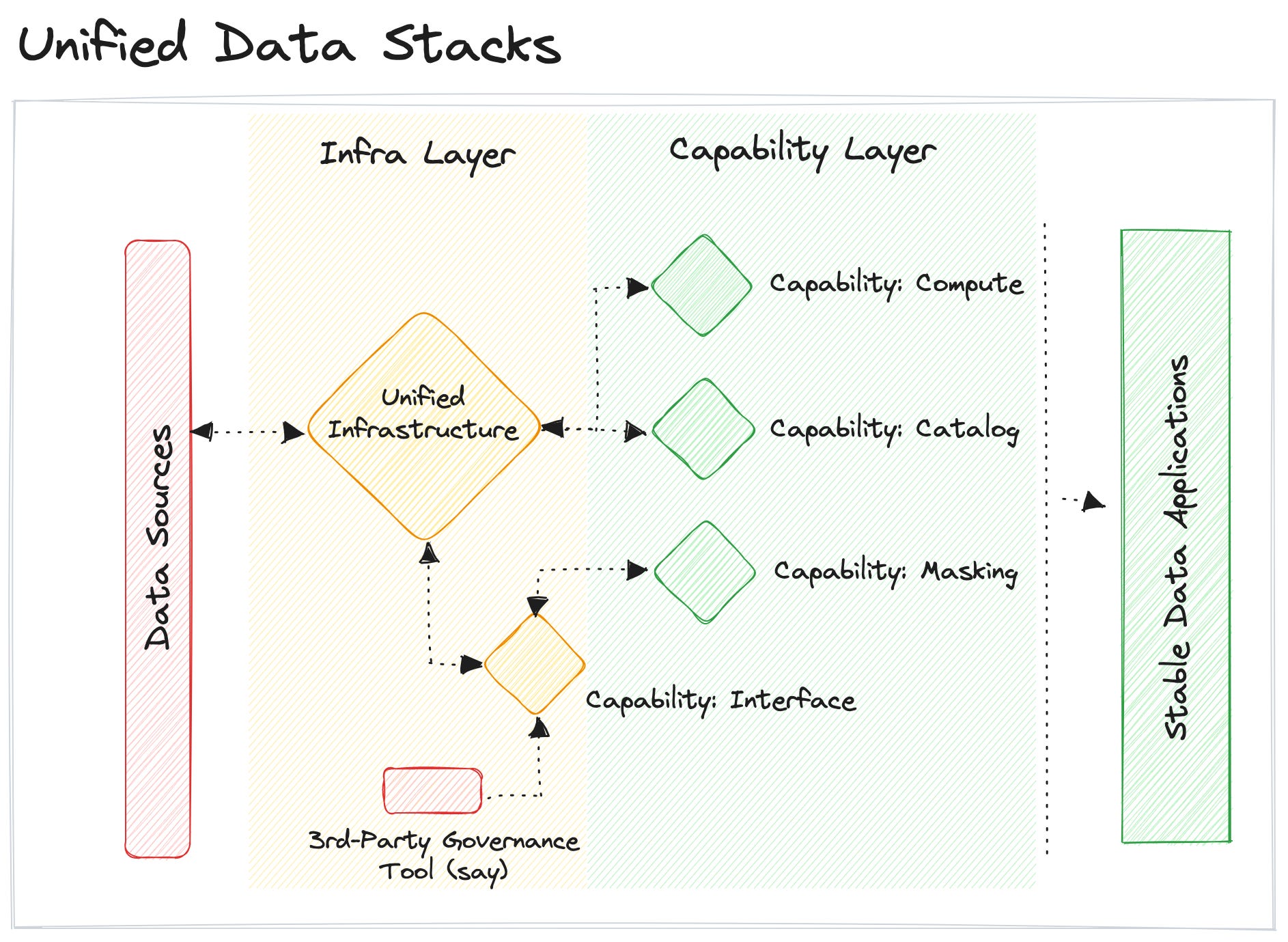
This becomes possible due to an interface on top of the unified architecture that allows tools to talk to each other and propagate their core capability. At scale, this cuts down pipeline complexities or fragility, enabling data developers to focus on what really matters for the business (Data & Data Applications) instead of getting stuck in maintenance loops.
Interoperability is the ability to communicate seamlessly with various components in the data stack, often declaratively. Declarative interoperability essentially means being requirements-oriented instead of process-oriented. You only worry about the ‘what’ instead of the ‘how’.
Interoperability is also largely achieved through modularisation as well. Modularisation at the fundamental level of resources enables modularisation at higher levels as well, including layers of data products and higher capability layers such as cataloguing and monitoring.
Interoperability at these higher layers also means seamless communication. For example, data products from the marketing domain, even though contained in their isolated verticals to avoid corruption of pipelines and data, should be able to communicate with, say, data products surfaced by the sales domain.
Or, in the context of capability layers, the catalog solution would be able to communicate seamlessly across elements in the end-to-end data stack for true discoverability (which is not the case in prevalent stacks. Catalogs are often restricted, compelling data teams to operate multiple catalogs across different localities. So is true for different tools).
Polarity is the innate nature of any ecosystem, including the data ecosystem. There are regions of high pressure and low pressure that induce movement, and so is the same with data. Polarity is incidentally a natural law and no different in the case of data.
How does this transform into infrastructure? Different planes of operations with various exchange points create a heavy contrast which is where the infrastructure stabilises the transfer. For instance, in a data ecosystem, you’ll typically have an operational plane, an analytical plane, and a utility plane. All three planes have distinct functions and talk to other planes to establish certain operations.
These planes could be starkly different in different ecosystems. Another example could be control, development, and activation planes. The notable point is the contrast between different points in the data ecosystem and the levers supplied by the infrastructure to journey between these points.
Every action should incite a reaction in the data ecosystem, which is not nearly the case in prevalent data stacks. While the sensory abilities to capture and record data have grown significantly, the abilities to process, manage and understand that data have not progressed at the same rate. So yes, we have the eyes, ears, skin, tongue, and nose, but we still lack a well-formed mind that can understand and operationalise the inputs from these channels.
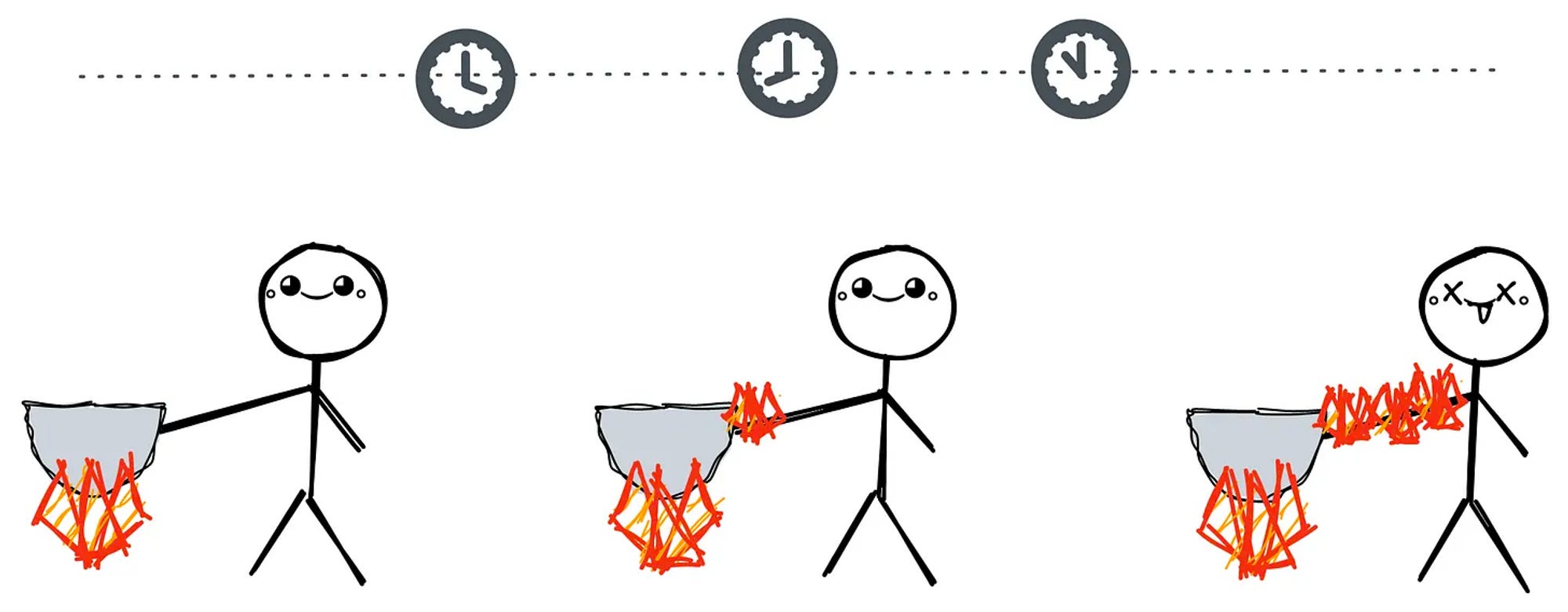
Customers are used to transactional experiences and consider them the bare minimum. Thus, their attention today is automatically drawn towards brands that provide more than the bare bones - Reactive systems or personalisation. In fact, most have started depending on data personalisation to guide even their purchase decisions. There’s a common joke among avid social media users on how they look for personalised ads instead of posts to decide what they need.
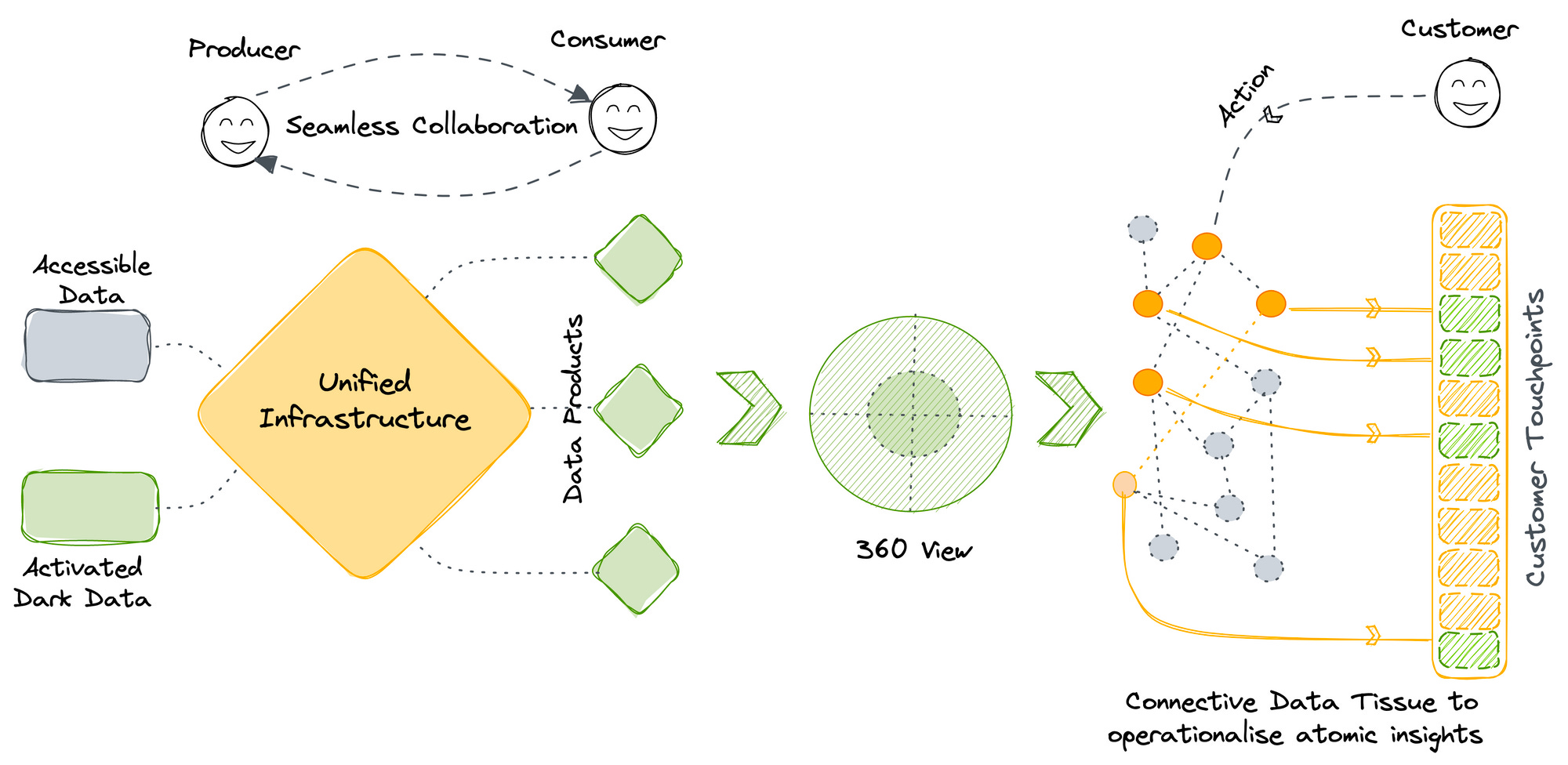
The infrastructure should be such that it enables a ripple effect across the data stack and across customer touchpoints. A unified storage paradigm bridges the gap between different capabilities essential to the data stack and helps users produce and consume data as if data were one big connective tissue. Users can access data through standardised access points, analyse it optimally without fretting about specific engines and drivers, and most essentially, rely on that data that arrives on their plate with embedded governance and quality essentials.
Any action or change in data would impact the larger connective tissue to hyper-personalise the customer’s experience. Forbes estimated that 86% of buyers would pay more for a great customer experience. That number is only expected to have gone up in the rapid transition we witnessed during the last two years. More recently, McKinsey estimated that the 25 top-performing retailers were digital leaders. They are 83% more profitable and took over 90% of the sector’s gains in market capitalisation.
Every customer or user action is a ripple. The infrastructure should be able to support the propagation of these ripples across the connective tissue and impact the customer journey in terms of diverging and converging actions on the pipeline. Most of the brands that are successfully thriving today have consistently focused on becoming experience-first. They have tapped into data at every touchpoint across the customer journey to truly graph out the customer’s behavioural patterns. Any new event gives them the advantage of tracking down the potential decisions of the customer so they can fork their operations accordingly.
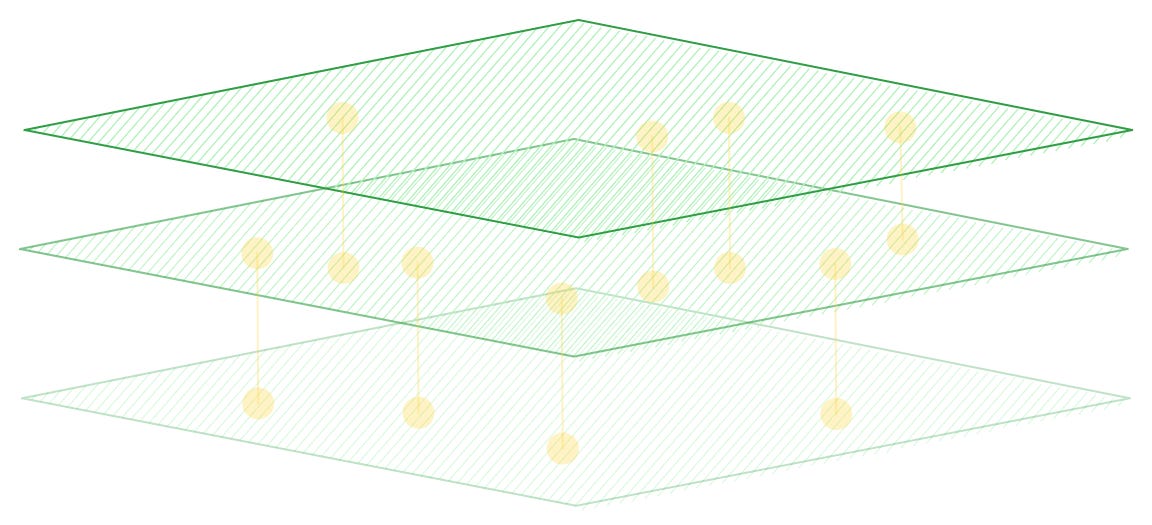
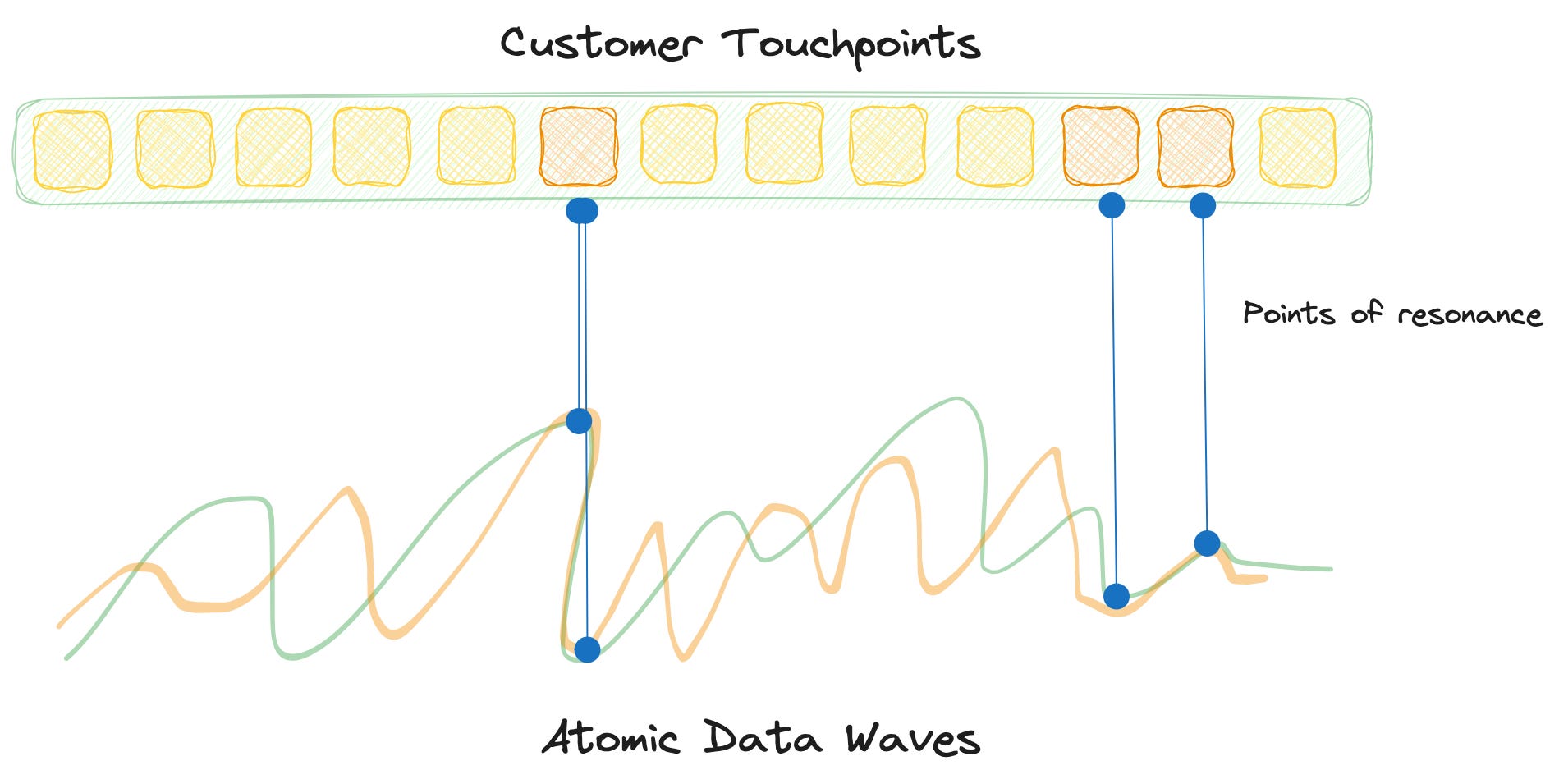
Like all things, data too has a wave-like nature. There are trends, cycles, seasons, and bursts of data naturally observed across all domains and industries. The resonance analogy comes into play when different atomic cycles or atomic trends in data sync into insights and decision enablers.
These atomic insights help to run a business with a data-first approach where every action is data-driven. The infrastructure should be able to identify these waves and spin up enough resources in coherence with such resonance to enable atomic insights on the fly.
Prevalent data stacks, on the other hand, are limited to big-bang insights on batch data arrived at after weeks and months of processing. They are not sensitive to atomic changes in data and limit experience-driven products and services.
Fun fact: These objectives have a notable resemblance with the seven hermetic principles.
Implementation of these Infrastructure Ideals
The first step to materialising any infrastructure is to create an infrastructure specification. A specification is like a PRD for an infrastructure. You need to define the purpose, the principles, the SLOs, architecture, personas, and so on before even building or adopting the infrastructure.
A data developer platform (DDP) infrastructure specification is designed in a similar flavour. It is not the infrastructure but rather a specification that any and every platform developer can adopt or enhance to develop the infrastructure from the bottom up.
The DDP specification provides data professionals with a set of building blocks that they can use to build data products and services more quickly and efficiently. By providing a unified and standardised platform for managing data, a data developer platform can help organizations make better use of their data assets and drive business value.
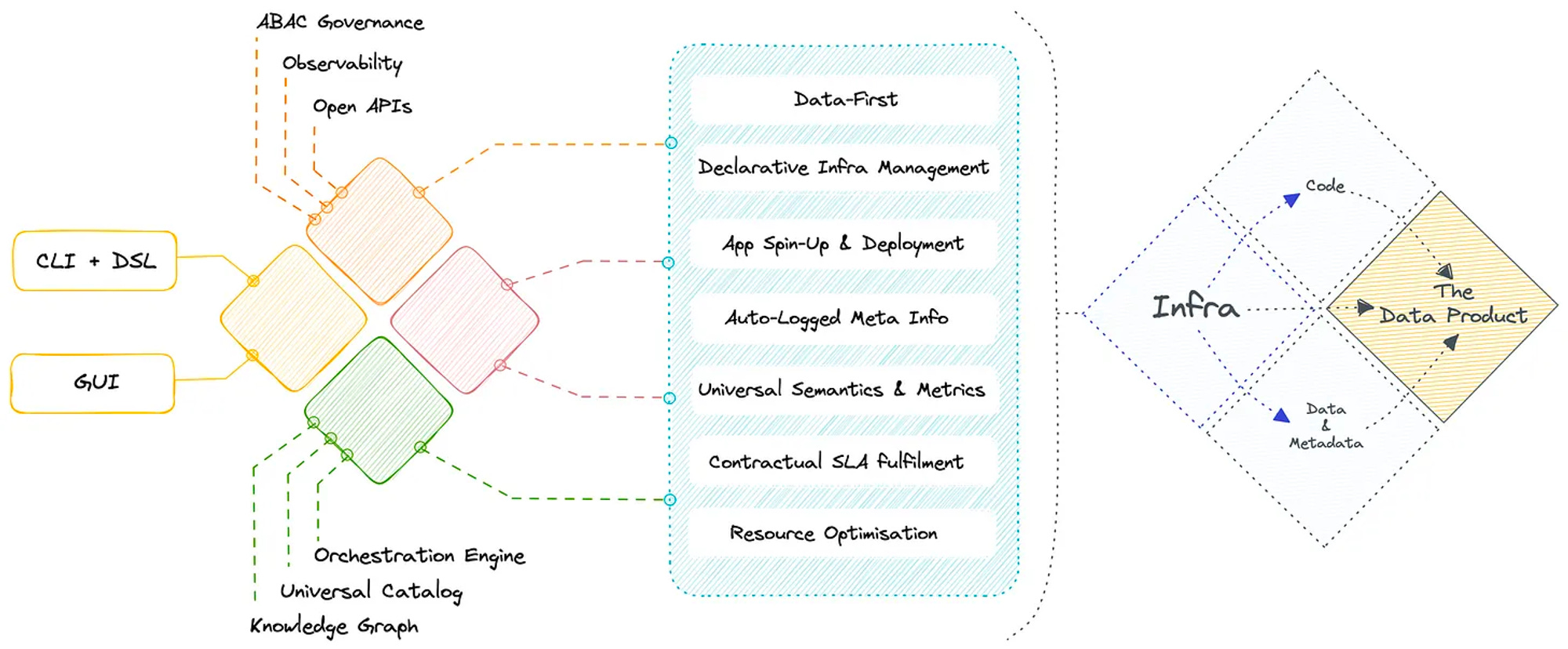
The entire DDP specification is aimed at being a community-driven spec and is open to modification, customisation, and enhancements. datadeveloperplatform.org can shed more light and provide more context around the same. Everything from purpose to architecture has been thoroughly outlined, with enough leeway for practitioners to enhance the spec for better or for their own unique use cases.
Follow for more on LinkedIn and Twitter to get the latest updates on what's buzzing in the modern data space.
Feel free to reach out to us on this email or reply with your feedback/queries regarding modern data landscapes. Don’t hesitate to share your much-valued input!
ModernData101 has garnered a select group of Data Leaders and Practitioners among its readership. We’d love to welcome more experts in the field to share their stories here and connect with more folks building for the better. If you have a story to tell, feel free to the Editor.











