




TABLE OF CONTENT
The past several years in data have seen vast quantities of investment and an enormous amount of different vendors, platforms and tools emerge. In parallel, half of Enterprise IT spending is forecasted to have moved to the cloud by 2025, and it goes without saying that we are now in the midst of an AI revolution.
As Data Engineers, one interesting sub-trend is the adoption of software best practices in data engineering. With this new territory come age-old debates in software development, and one of these is that of the microservice vs monolithic architecture.
The above piece approaches the debate from the perspective of many current, “Modern” Data stacks. In this, we’ll approach the same discussion from the monoliths of old.
Monolithic Application Basics in Data Engineering
What is a monolithic application in data engineering?
A monolithic application can be viewed as a single self-dependent unit that serves multiple use cases for the business or a team. The primary detail we need to note is that while this architecture may have multiple parts, this unit is logically executable as a single entity.
Monoliths are, by nature, strongly coupled systems in which each entity is heavily dependent on the functioning of other entities and cannot be independently accessed or scaled. Any updates or changes, however minor, require an update and deployment for the entire stack, testing all dependencies and handling all the dominoes in the chain.
In the context of data engineering, a monolith can constitute a tightly coupled and locked-in data platform or tool where each component is inflexible in terms of interoperating with foreign components. For example, a governance platform that only understands its native catalog and locks in the users to either use two catalogs (for policies and general purposes) or migrate to one. Or a catalog tool that only understands policies built within its own ecosystem.
Learn more about this dilemma here ⬇️
Progressive overlap in assembled systems
While monoliths are great for small-scale and MVP projects, they are cumbersome, inflexible, and costly for large and long-term projects. Typical monoliths usually end up with huge codebases, which are challenging to maintain and scale and ultimately pose a challenge for the owners to prove their ROI to stakeholders transparently.
How is this different from a “Microservices” approach or set of microservices applications?
Microservices are comparatively the opposite of monoliths. An ideal microservices architecture is a consolidation of multiple independent, self-sustained units, each serving a different use case—usually the smallest component of a solution. The most important feature of a microservices architecture is that each entity is highly interoperable with each other as well as new entities in the stack while being self-sustained.
With regard to a stark and slightly controversial real-world example, it’s easy to confuse the modern data stack (MDS) as a microservices architecture. Each component in an MDS is primarily a tool or a vendor aiming to gain user real estate with active strategies to interoperate selectively. On the other hand, a unified layer that opens up existing and new entities in your stack- almost like an interface for interoperability, brings the microservices approach to life.
Few primary pointers to look out for to differentiate a microservices architecture from monoliths:
- Each unit is self-dependent
- Each unit serves the smallest component of a demanded solution (ideally)
- Each unit is able to talk to any other entity
- Each unit is independently deployable, testable, modifiable, and scalable
- Changes in each unit do not impact other self-dependent units
Can a monolithic application have multiple repositories?
Yes, it can, but the entire application code is usually restricted within the bounds of a single code base in monoliths. However, for those fond of their monoliths while suffering the overwhelm of the single repo, they can split the code into multiple repos.
However, that adds to the suffering in a monolithic framework. Now developers need to manage the dependencies within multiple repos alongside the ones internal to the original repo. This is because all these repos ultimately form a single logical unit and are tightly coupled with each other at the end of the day. This is why if you have to stick to a monolith, it would be sort of a best practice to stick to a mono repo as well.
How are monolithic applications deployed?
Monolith applications are deployed in their entirety. For any update, minor or major, the entire application stack needs to be deployed as a whole- which includes the loops of integration testing, dependency testing, and functionality.
Imagine if the Pyramids were built in a way where the builders had to carry the entire piece at once to the site instead of deploying each fundamental building block at a time. We probably wouldn’t have one of the ancient wonders of the world.
The deployment phase is the most challenging phase in monolith structures for the same reason. One tiny diff means redeploying the entire workload. It’s no surprise that a good number of anonymous frustrated data engineers on Reddit hailed from the monolith overlords!
Historical Examples of Monolithic Data Architectures
The most obvious example of home-grown data engineering, popular in tech companies but even banks such as JPMorgan was leveraging Airflow for Extraction, Loading, Transformation, Data Orchestration and literally anything you could describe in plain English.
From an infrastructure perspective, this Airflow repository is essentially our monolithic ELT application. However, due to the spiky nature of ELT workloads and the vast number of services Airflow requires to run, deployment onto Kubernetes infrastructure is none-trivial.
A second breed of example would be the data platforms of old; think Talend, Informatica Power Centre, the Cloudera Data Platform and IBM Cloud - true, we do not comment on how their underlying infrastructure is deployed, but from the user perspective, it is essentially monolithic as you interact with a single, large, multi-facted application
The Rise of Distributed Computing and Microservices
Ten years ago, deploying Airflow or using all-in-one platforms like Informatica and Talend for data and analytics was the norm. Airflow, with its Python-based flexibility, quickly became a go-to for managing complex data workflows, even though it required significant expertise to handle its scaling challenges. Meanwhile, platforms like Informatica and Talend provided comprehensive solutions, offering tools for everything from ETL to data governance, albeit at a high cost and complexity.
Back then, on-premises data solutions were the norm, with organizations heavily investing in their own data centres. This setup provided complete control over data and infrastructure, crucial for industries with stringent regulatory requirements. However, maintaining these on-premises environments was expensive and resource-intensive, involving significant capital expenditure and ongoing operational costs. Scalability was another challenge; expanding on-premises infrastructure to meet growing data demands was often slow and cumbersome.
Fast forward to today, and the data and analytics landscape has transformed dramatically with the advent of cloud computing and modern data platforms. But has it solved our problems?
Airflow, Fivetran, Snowflake, dbt Cloud, and Kubernetes - A Common Anti-Pattern
Airflow should be used the right way which, as argued here, is using Airflow solely as an Orchestration Tool rather than a tool responsible for data processing.
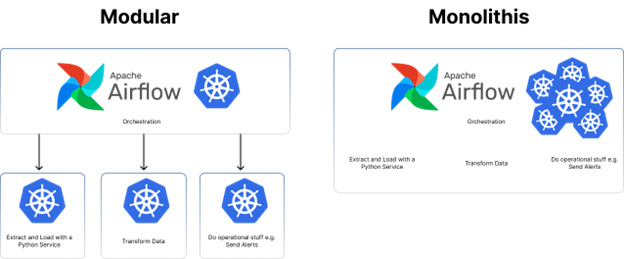
It does not really make sense to have a heavyweight piece of infrastructure for Orchestration and monitoring in a modular architecture because the services that handle computationally-intensive processes already exist.
This pattern is well recognised, especially in big data processing. For example, AWS does not bundle Orchestration with Spark execution (used for Big Data) - they recommend EMR which is a separate service.
Another example would be Databricks - whose main product is also managed spark execution. Its Orchestration product is serverless and therefore a Modular Architecture under-the-hood.
So let’s understand what happens when organisations buy a super common “Modern” data stack - Fivetran, dbt Cloud, Snowflake and Airflow.
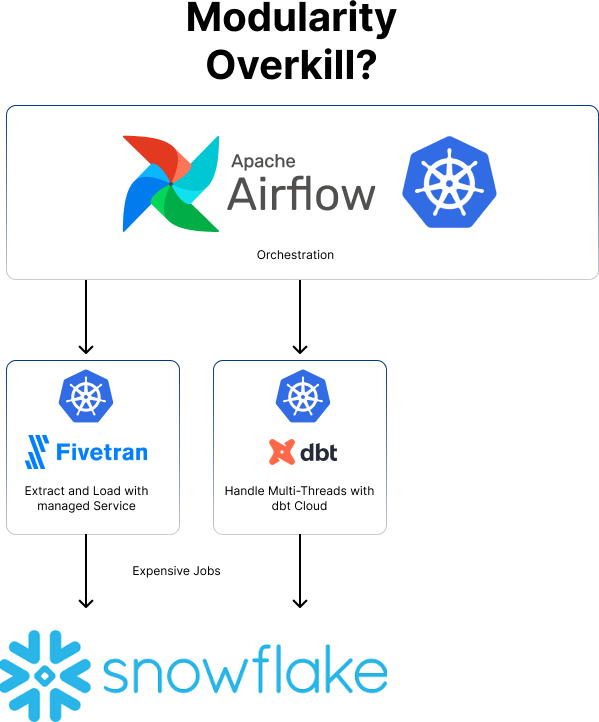
By investing in these technologies, you are implicitly going for quite a lot of Kubernetes. One cluster to manage Airflow, you will pay for Fivetran’s infrastructure, dbt Cloud’s infrastructure (even though all it is doing is sending queries) and Snowflake - which is a huge distributed computing engine that should be making up 80% of your bill here.
This is an anti-pattern, because as we saw before Airflow makes intuitive sense as a monolithic application (even though it was not designed for that). When 95% of the relevant compute is happening in heavy-duty microservices you just bought like Fivetran and Snowflake, why have you invested in another one in Airflow?
We won’t critique dbt cloud here, but you could make a similar argument.
📝 Related ReadsLeveraging existing stacks (part on dbt) for cost savings, efficiency, and monetisation: Link here
Leveraging existing stacks for cost optimisation: Snowflake + Utlity Layer
So, what are the alternatives, and how can they be implemented?
How to successfully scale a microservices Data Architecture
The first thing to be conscious of is where your compute is happening.
Cloud providers (Azure, AWS and GCP) and Data Cloud Providers like Snowflake and Databricks provide readily available sources of compute. Where possible, Data Teams should always prefer executing processing on their own infrastructure as it is simply cheaper.**
After doing this exercise, you should have an idea of how much compute is occurring and where. You should then be able to get a sense of which “Data Microservices” are bottlenecks in terms of cost and speed.
You should work on the assumption that Pipeline Management expenditure (Orchestration, Observability, alerting and monitoring, etc.) is 10 - 20% of the total cost of ownership (including headcount cost).
It is likely that if your organisation leverages Airflow for a significant amount of processing your total cost of ownership for Data Pipeline Management will be significantly higher. If you are an early stage start-up and thinking of hiring a data engineer to build out this infrastructure, you find a similar result.
📝 Related ReadsCheck out our Total Cost of Ownership deep-dive here
You will realise that if the salary is $100k and cloud Spend is $50k, even if the Data Engineer only spends a moderate amount of time Managing Data Pipelines with all the SaaS in the world, they spend too much time building boilerplate infrastructure instead of adding value.
Leveraging an all-in-one, serverless data pipeline management platform can be part of the answer. However, having a data strategy that aligns with tool selection is more crucial—a single competent engineer building everything from scratch could achieve the same thing as a competent analyst with effectively managed services.

📝 Related ReadsLearn more about the open standard for a utilty/management plane: Data Deveoper Platforms
Consultancy partners and training are also a great and affordable option in the early days as Series A to Series C companies get on their journey with data.
The key is to understand where the data function is spending resources, define goals, ensure anti-patterns aren’t followed, and start driving value from data quickly.
** For heavy-duty data processing platforms like Snowflake and Databricks process so much that they get discounts from cloud providers, which are, to an extent, passed on to end customers.
End price of compute = Raw Cost * (1-Discount + Premium)
You would think the Premium Vendors like Snowflake charge outweigh the discount they might receive.
Conclusion
Many large enterprises implemented open source workflow orchestration software in a monolithic way. While this was probably the most effective approach to data engineering for many years, the proliferation of tools in the Modern Data Stack but also the infrastructure capabilities offered by cloud providers present huge opportunities for streamlining efficiency and greater compute efficiency.
While enterprises and companies leveraging the managed monoliths of old like Informatica and Talend are now shifting to modular architectures, companies invested into Airflow appear more entrenched.
It is key to understand the architectural implications and the Total Cost of Ownership of using such systems. While it may seem obvious for many digital native companies to start with a Microservices Data Architecture, entrenched data teams in Large Enterprises may need more convincing.
📝Author Connect

Find me on LinkedIn | Explore Orchestra
Note from Editor: Orchestra curates a blog authored by the Orchestra team & guest writers. You’ll also find some cool whitepapers for more in-depth info; feel free to dig in!












