





TABLE OF CONTENT
This piece is part of an ongoing series. If you’re here for the first time, you can refer to part 1 to get more context on:
- Motivation for data products/Why repurpose existing stack?: Cost savings, Monetisation, Experience
- How Snowflake is realigned to support Data Products?
- Establishing cost efficiencies for Snowflake as a result of Data Products
- A step-wise breakdown with some YAML & SQL samples for Snowflake connectivity and Data Product Activation
Access Part 1 ⬇️
Build Data Products With Snowflake | Part 1: Leveraging Existing Stacks
Now, let’s dive into the two other forks of business ⬇️
Monetisation & Experience of Data Citizens
To understand how Snowflake & Data Products combined can achieve an impact on revenue, we need to understand what exactly data monetisation means.
Here’s a direct excerpt from The Data Strategy Show hosted by Samir Sharma, CEO at datazuum & featuring Saurabh Gupta, Chief Strategy Officer at Modern.
6-7 years ago, everybody was talking about monetisation, trying to get their data assets to be valued and put on the balanced sheet. But monetisation has a lot of different criteria for different people. So, are you suggesting that monetisation is increasingly more important because of the data product management equation? Is that where you think now we’ll be able to monetise our products and our data quicker and faster and show that somewhere on a balance sheet?
Data monetisation has been an interesting topic for almost a decade. Several years ago, a lot of organisations got on the bandwagon, saying this is another line of making revenue. I don’t know the exact numbers, but if there were companies like Walmart, they’d make a lot of money out of monetising their data.
Many companies had targeted efforts toward collecting and managing data, but there were also challenges with that, like data privacy, how it’s being used, and everything around data complexity. So there was a pushback, and monetisation became a little bit more difficult, but in the last couple of years, there’s been a much bigger shift in understanding how data monetisation should be seen.
Internal Data Monetisation
It’s not just the dollar return or the money you are investing or getting out of selling your data, but it is more about how you can use the data and make your processes more efficient, which can be quantified in dollar terms.
I call it internal data monetisation. If I am running the data ops and I can make your processes 10% cheaper, that’s the value I get out of it.
External Data Monetisation
The second part is external monetisation, where the story hasn’t changed much- closer to how we defined it half a decade ago. This involves verticals like data sharing, selling, and insight development. Hundreds of companies working on similar applications would be happy to buy your company’s curated data, given it comes with the right reliability SLOs for their data applications.
How Snowflake Approaches Data Monetisation
Alongside Marketplace capabilities, Snowflake offers a Snowflake Marketplace for data providers and consumers to leverage the benefits of data sharing. Providers can publish data that they believe could serve wider use cases for other third parties, and consumers can explore. In addition to these options, Snowflake also provides data share and data exchange options.
Limitations
The biggest limitation on all three options is getting restricted to Snowflake accounts and the Snowflake ecosystem on both the provider’s and consumer’s part. Moreover, there’s a heavy cost of massaging and prepping the data against Snowflake’s pre-defined standards which again, is useful within the bounds of Snowflake accounts and transfers.
However, there are several limitations to this process. Some of the most vivid ones include:
- Data sharing is largely restricted within account-to-account exchanges and additional operational and resource costs that tag along with it.
- Heavy restrictions on sharing data with consumers who do not have a Snowflake account: inability to access, time-travel, or manipulate data, or create objects in the database; only view or query the data. Moreover, a continued credit bill against the provider’s account.
- Data replication when sharing across different regions- while this is primarily put in place to ensure some form of governance (separate compliances for different regions), the implementation is messy, leading to higher resource (storage, transfer, compute) utilisation.
- Doesn’t support API culture and primarily restricts ops within the marketplace ecosystem, impacting overall flexibility of seemingly independent data stacks.
- Restricted Governance: While Snowflake offers governance, it is challenging to enforce governance across multiple sources and regions. Also, for data that is not in the Snowflake data warehouse, you cannot implement Snowflake’s governance.
- Multiple Transfers & Replications: Alongside data replication in multiple Snowflake instances, all data needs to be moved as-is for processing or compute. Post-sharing, there aren’t systems in place for consumers to move data only when explicitly demanded by the business use case.
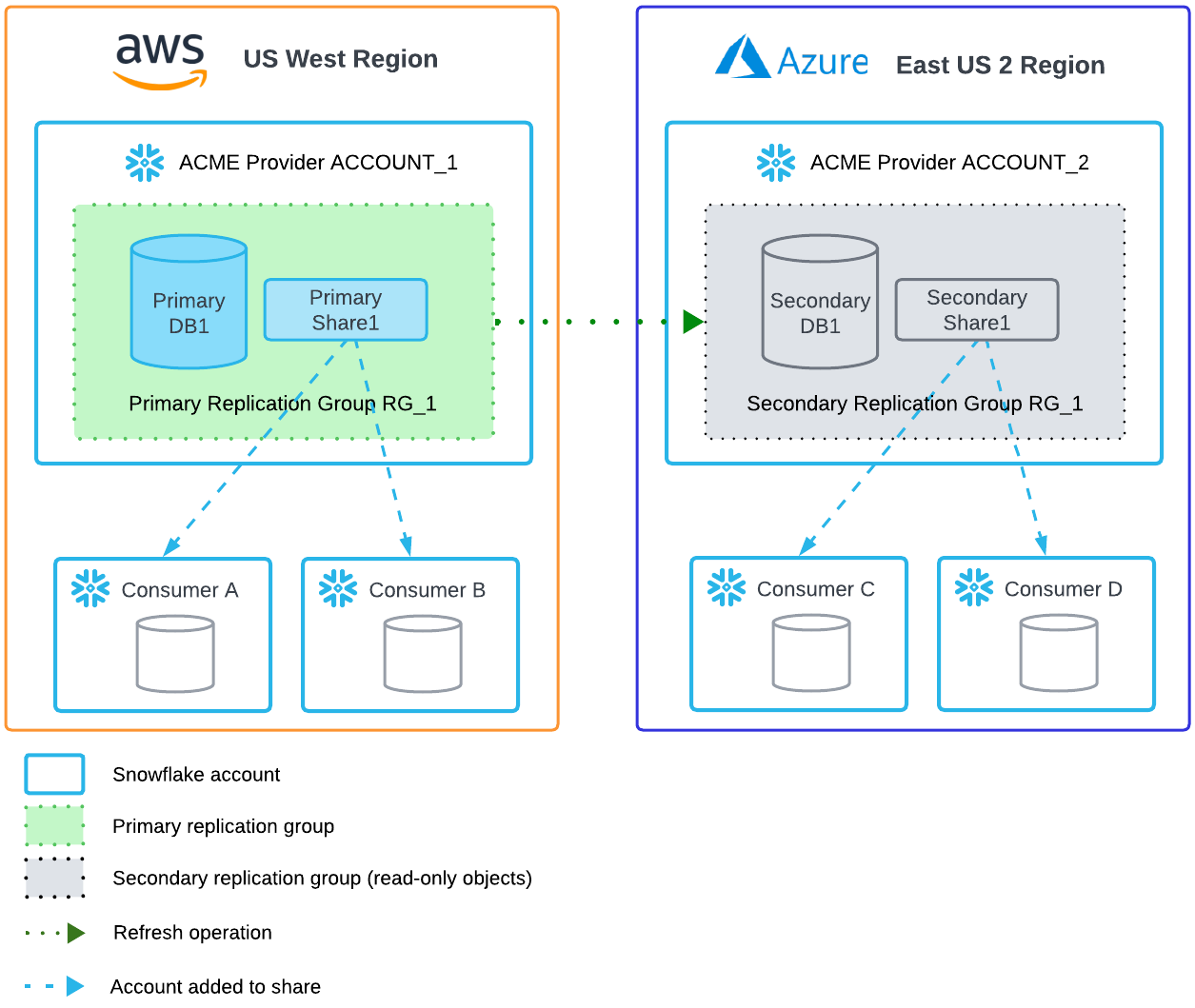
How Data Products on Top of Snowflake Takes Off Limitations on Data Sharing + Seamless XP
To understand the power of building genuine Data Products on top of Snowflake, we need to revisit the concept of output (o/p) ports - one of the four pieces of a data product construct (i/p ports, SLOs, transformations, o/p ports).
Data Products solve a wide range of data management issues, which include accessibility and interoperability. Output ports play a big role in enabling the above by ensuring diversity in terms of file formats, data-sharing protocols, and friendliness to native ecosystems of different business domains.
For instance, business domains such as HR would be much more savvy with simpler data access mechanisms like, let’s say, excel files. How would you enable that through account-to-account sharing without bringing additional ops or costs in between?
📝 To learn more on how to build data products with Snowflake, access this segment of Part 1.
Instant Data Sharing & Connectivity to Diverse Applications
Think instant connectivity to Excels, BI tools, Models, and more without the whole nine yards of Snowflake norms, which ultimately restricts you to account-to-account hops within the Snowflake ecosystem, with a billing counter running on the sidelines.
Depending on your sharing or consumption requirements, all you need to do is create a new output port on the same data product (paired with a port-specific data contract for governance and semantics) and activate your data applications.
Multiple File Formats and Data Sharing Protocols
Big players like the Snowflakes of the world aren’t friendly to API cultures and inherently restrict data to their own marketplace or exchange ecosystems. By building data products on top of Snowflake, we open up the data available on the Snowflake Warehouse to diverse file formats, transfer protocols such as FTP and SFTP, sharing protocols, and APIs such as JDBC and ODBC.
A Cheaper Layer for Data Sharing
One of the primary pillars of Data Products, as we have emphasized before, is a self-service layer. Data Developer Platforms (DDP) as a self-service layer essentially acts as a utility plane. DDPs allow you to self-serve purpose-built data products and deploy them for n number of use cases, inclusive of data-sharing applications.
By making purpose-built data (as demanded by business cases) accessible through multiple formats and access routes, you enable a much cheaper way for internal teams to reuse data products without driving up billing on multiple Snowflake instances or even data-moving costs (move only what you need). Essentially reducing the operational cost of different domains that are consuming data. This has a direct impact on Internal Data Monetisation that we referred to before.
Once different domains are ready to publish their own data to different customers, clients, or partners, the same diversity and direct data access are enabled through the DDP utility layer without any restrictions, such as the requirement of snowflake accounts on the consumer’s part, limitations that come with not having accounts, or additional operational costs behind compute and store post data sharing.
Explicit Reduction in Compute Costs
If you create data products in a DDP which consumes data from Snowflake and we have others who consume this data product, where is the compute done for those Snowflake datasets? Now in the DDP context (utility plane or self-serve layer), the advantage is to have that compute done in DDP so you don't pay a heavy snowflake bill for those who consume your Data Product.
Moreover, as we emphasised in the above callout (cheaper layer), just by the virtue of data products being purpose-driven, you reduce an overwhelming amount of data that needs to be processed and only pull up or move data that are explicitly demanded by the model-first data product (MDP).
📝 Learn how MDPs are built with purpose-driven approach on top of Snowflake combined with a self-serve layer.
End of Part 2 - Stay Tuned for Upcoming Segments!
Within the scope of this piece, we have covered the monetisation and experience angle. For a more dedicated view on cost-optimisation with Data Products on Snowflake, refer to Part 1.
Stay tuned and revisit this space for upcoming pieces where we cover how to build data products by leveraging common workplace tools such as Databricks, DBT, or Tableau!
Co-Author Connect 🖋️











