




TABLE OF CONTENT
The Contradiction of Vision & Reality
The Lakehouse was revolutionary in idea—a hybrid promise of lakes + warehouses. The objective was to unify the flexibility of data lakes with the reliability of data warehouses. No more data copies. One platform for analytics and AI. Simpler, cheaper, and more powerful. But it ended up relying on centralized control, proprietary compute, and tight vertical integration.
And instead of decentralization, it doubled down on vertical control.
The architecture tightly coupled compute, storage, and metadata. Delta table format, Spark compute, Unity catalog — all inside the same house, all behind the same walls. “Unified” became synonymous with “owned by one.”
- Data teams wanted modularity. They got locked in.
- BI teams wanted trusted metrics. They got SQL sprawl.
- ML teams wanted fast, flexible features. They got broken pipelines and storage APIs.
The vision was hybrid. The reality was centralized.
Lakehouse 1.0 solved a real problem — the disjoint between lakes and warehouses — but duplicated the problem it set out to solve inside a monolith.
What was Lakehouse 1.0?
Core idea: Store raw data like a lake, analyze it like a warehouse.
The motivation of the Lakehouse was to unify analytics and AI with one architecture. Most notably, it was a response to fragmentation. Analytics lived in the warehouse. Machine learning lived in the lake. Every use case meant another data copy, another platform, another team reinventing the logic of “revenue” or “churn” in their own language.
The stack was siloed, and truth was scattered along with the trust. Which source of truth to trust? More importantly, why are there two sources of “truth” exposing different metrics? So the Lakehouse 1.0 emerged with a powerful thesis:
One storage layer. One source of truth. One platform that could handle SQL dashboards and ML feature generation, with the same data, at the same time. It offered the elegance of convergence and promised the simplicity of one language, one format, one architecture.
A rejection of dualism (warehouse vs. lake) and a move toward something unified with the best of both worlds: a lake that behaves like a warehouse, and a warehouse that thinks like a lake.
At first glance, this architecture looked clean. Minimal. Efficient. One engine for querying, One layer for metadata and table management, One lake beneath it all — open formats like Parquet on S3. It looked like openness. It felt like simplicity.
But there was a catch beneath that elegance: The architecture was vertically aligned and tightly coupled.
Why the Lakehouse was Only “Open” on Paper But Not In Action
A few years ago, storing and analyzing data was doable but felt complex from inside-out and seemed messy outisde-in. Teams had data lakes—huge, unstructured collections of data, like a giant pile of books on the floor. Then a clever idea came along: why not organize all those books into a single, unified shelf?
That shelf was called the Lakehouse. It combined the scale of data lakes with the structure of data warehouses. You could keep all your books (data) in one place, label them properly (metadata), and let anyone use them for reading, learning, or research (analytics and AI). It was a new kind of library, and it solved real problems of fragmentation and complexity.
But the Shelf Had a Catch
There was one design flaw. The shelf worked best with the tools of the vendor who built it—their own book catalog, reading lamps, and study guides. If you brought your own tools into the library, they didn’t quite fit. The shelves were subtly shaped to favor the vendor’s ecosystem. So while the Lakehouse was marketed as open, in reality, it was vertically integrated. The shelf, the books, the labels, and the reading tools were all optimized for a single vendor.
Which implied that to organise your large heap of books, you don’t just buy into the storage shelves, but also need to buy into the ecosystem to manage and even use those books. The flexibility was limited, and teams often found themselves locked into a specific way of working.
The Rise of Truly Open Shelves
The Open Table Format revolution struck a chord: Apache Iceberg, Apache Hudi, and the open specification of Delta Lake. These were open bookshelves—standards that let anyone organize their books and still use whatever tools they preferred.
Want to read with DuckDB? You can. Need to scan with Trino, Spark, or even Snowflake? Yes, you can. The shelf no longer dictated the tools: you could mix and match. This was true power for data and analytics engineers, a breakthrough.
Libraries could now be built around a universal shelf, not a proprietary one. Once librarians could use open formats, they realized they didn’t need to pay for the full ecosystem.
They could assemble lighter, cheaper, more flexible stacks using best-of-breed tools.
Absolving the Core Design Sin, aka Centralisation: Becoming Modular, Open, and Decentralised
This is where we are now. The Lakehouse is not dead. It lives on. But the second generation is built differently. Instead of one vendor owning the shelf, metadata, and reading experience, we now have modular components working together. The architecture is open not just in storage, but in compute, governance, and access.
And that shift, from centralized control to true interoperability, is what defines Lakehouse 2.0.
Conflicts that Sparked the Need for a Second Generation of the Lakehouse Construct.
Checking out of the analogy, let’s take a closer look at some of the most defining challenges that the first generation of Lakehouses inflicted on long-term adopters.
The first and most noticeable problem was proprietary compute.
Despite the open storage layer, the execution engine was almost always Spark — and often deeply tied to one vendor’s distribution. Typically tied to Delta Lake, Hive tables (on HDFS/S3), or internal formats. This created a single point of dependency.
Workloads were expected to conform to the compute layer, not the other way around. Alternative engines like Trino, Presto, Flink, or even DuckDB could exist at the edges, but weren’t first-class citizens. The system was designed for vertical performance tuning, not horizontal composability.
Governance and catalogs were fragmented.
Most deployments defaulted to the Hive Metastore, which was never designed to handle the governance demands of modern data platforms: lineage, access control, change management, or multi-modal data access. As more tools entered the stack, definitions of “truth” drifted across teams and layers. There was no universal contract, no shared semantic layer, and no native way to manage trust in a decentralized environment.
The system also lacked true openness at the table format level.
Parquet was used for storage, but the actual table logic (transactions, schema evolution, data versioning) lived in proprietary formats. Even open formats like Delta Lake were initially tightly coupled to specific engines, limiting interoperability. This meant you couldn’t seamlessly move between engines, or easily integrate new ones, without deep rewrites and compatibility trade-offs.
Fundamentally, the architecture of Lakehouse 1.0 was tightly coupled.
Storage, metadata, catalog, and compute were all interdependent. Swap one, and you risk breaking the others. This violated a core principle of modern architecture: composability. Lakehouse 1.0 couldn’t support decentralized evolution. It couldn’t scale across domains or teams that wanted autonomy. It wasn’t modular enough to be future-proof.
In the end, Lakehouse 1.0 was open in name but not in spirit. It solved the fragmentation between data lakes and warehouses, but imposed a new kind of consolidation through vertical integration. Some other relatable limitations:
- Single-Engine Dependence
The query layer wasn’t truly open. It was optimized for a specific engine (often Spark). Try swapping it out? Good luck. You had to manually configure different engines to “see” the same data correctly. Cross-engine consistency (ACID, schema evolution, time travel) was fragile or missing. Portability was an illusion. Moreover, there was tight coupling of Metadata + Query Engine - Limited Interoperability
Notebooks and BI tools sat at the top — but the system didn’t treat ML and BI as equals. AI had to hack its way into the architecture — no native feature stores, no contract guarantees, no metrics layer. You couldn’t seamlessly switch engines (e.g., between Spark, Trino, Flink) without pain. Table formats and metadata often broke outside their native stack. - Governance & Contracts Were Afterthoughts
There was no semantic layer, no way to define “truth” once and reuse it everywhere. Everyone brought their own definitions. Governance and discovery were bolted-on, not native. Pipelines broke. Trust eroded. Limited observability and limited explainability (poor root cause analysis/difficult to debug red flags), no SLAs or data quality built-in.
📝 Reading References
Hugo Lu has done a splendid deep-dive on these aspects on his recent article ↗️
The OTF Revolution: “Legolising” the Data Stack
The turning point came with the emergence of open table formats — Apache Iceberg, Apache Hudi, and the open specification of Delta Lake. These formats introduced a standard way to define, track, and mutate data stored in cloud object storage. Crucially, they separated the logic of the table from the engine that queried it.
For the first time, compute and storage could evolve independently. Engines like Trino, DuckDB, Flink, Spark, and even cloud warehouses like BigQuery and Snowflake began to support these formats natively or through connectors. Instead of building custom integrations for every query engine, you could use a single table format across them all. That broke the lock-in pattern.
Now, data teams could plug in the right engine for the right job—without rewriting pipelines or duplicating datasets.
Batch, streaming, machine learning, and BI could all run on the same physical storage.
Suddenly, the compute layer became swappable. Storage no longer dictated engine choice. This decoupling of compute from storage wasn’t just a technical feature—it was a strategic unlock. And that’s where Lakehouse 1.0 began to show its cracks.
When open table formats became a practice, the reasoning for vertically integrated stacks weakened. Why be tied to one compute engine when you could build a modular stack with open interchangeable points?
This shift didn’t just improve performance or flexibility. It challenged the architectural assumptions of the first generation of lakehouses.
⚖️ “Lego-lising” the Data Stack = Freeing Data
What if we could modularise the components of the Lakehouse stack like Lego blocks? What if storage weren’t tied to a single vendor, and different processing engines could talk to the same data without endless duplication?
That’s exactly what Open Table Formats (OTFs) like Iceberg, Delta Lake, and Hudi enable. They sit on top of object storage (S3, GCS, Azure Blob), acting as a neutral metadata layer. Decoupling physical data storage through virtualised abstraction.
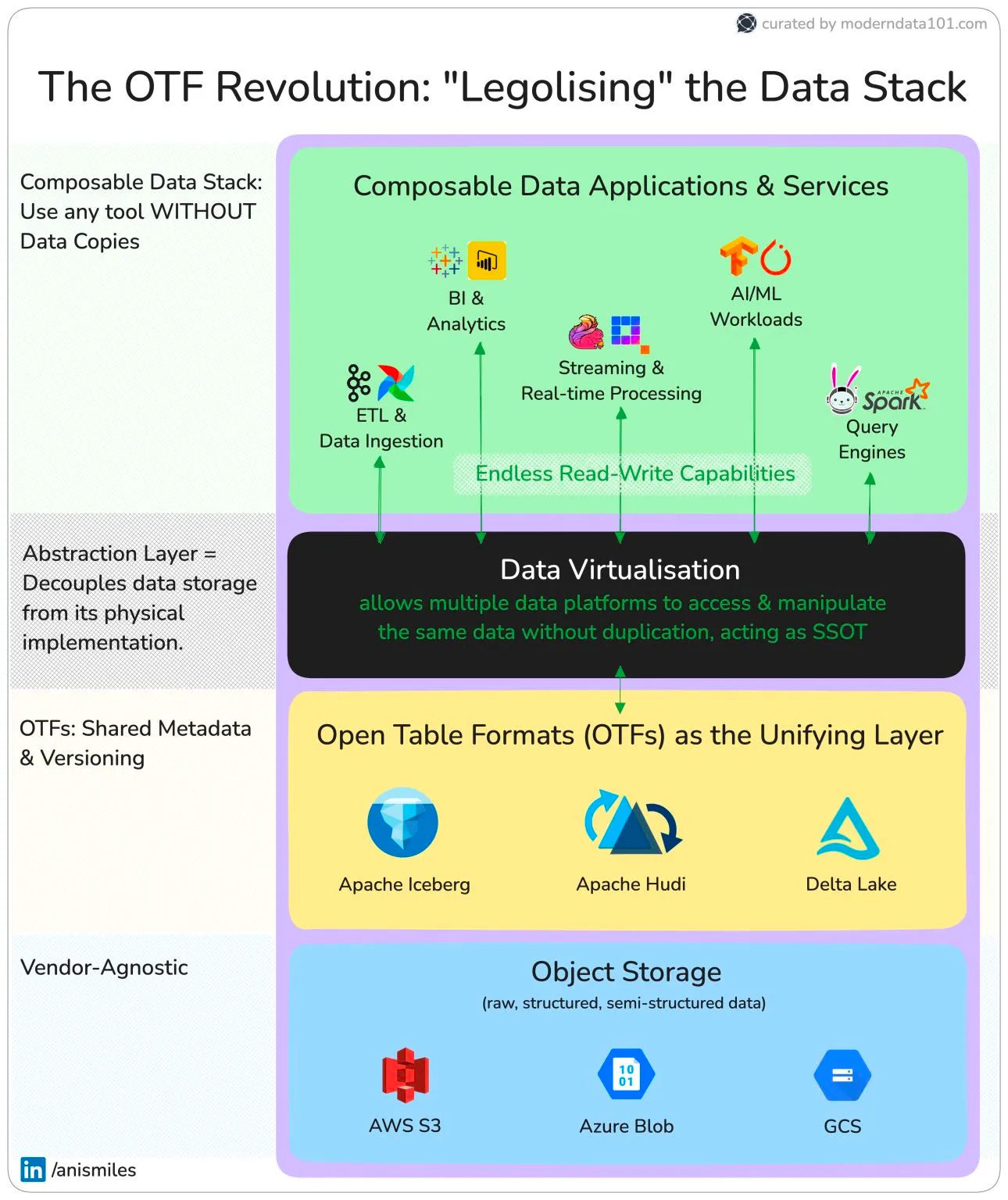
This implies:
✅ Use Trino, Spark, or Snowflake on the same dataset.
✅ Stream real-time events while running batch queries.
✅ Feed AI/ML pipelines without maintaining separate silos.
Instead of forcing all workloads into one stack, OTFs unlock true composability—one shared data layer with infinite stack possibilities.
Cannot control, another analogy coming up pronto…
Cue the Matrix. The Architect built the Matrix to be a perfectly controlled system, but the first versions failed because they didn’t account for human (data) unpredictability. The Oracle saw this flaw and introduced an essential element: Choice. More interestingly, the Illusion of Choice.
The same applies to traditional Lakehouse architectures, where a single table format (e.g., Iceberg, Delta, or Hudi) dictates the entire ecosystem.
In the Architect’s Vision of the Lakehouse, aka Lakehouse 1.0,
- Everything follows strict rules.
- You’re locked into one format, ensuring consistency.
- The system is optimized—but only for those willing to conform.
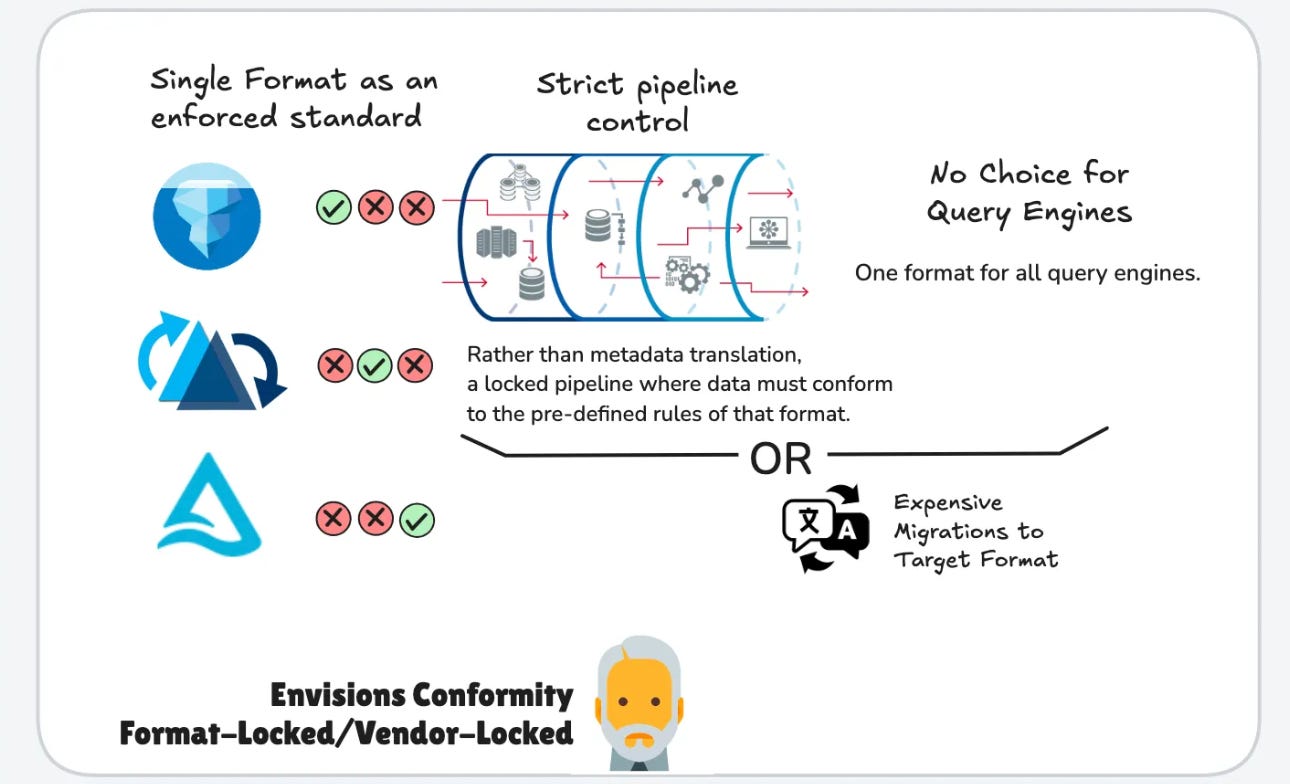
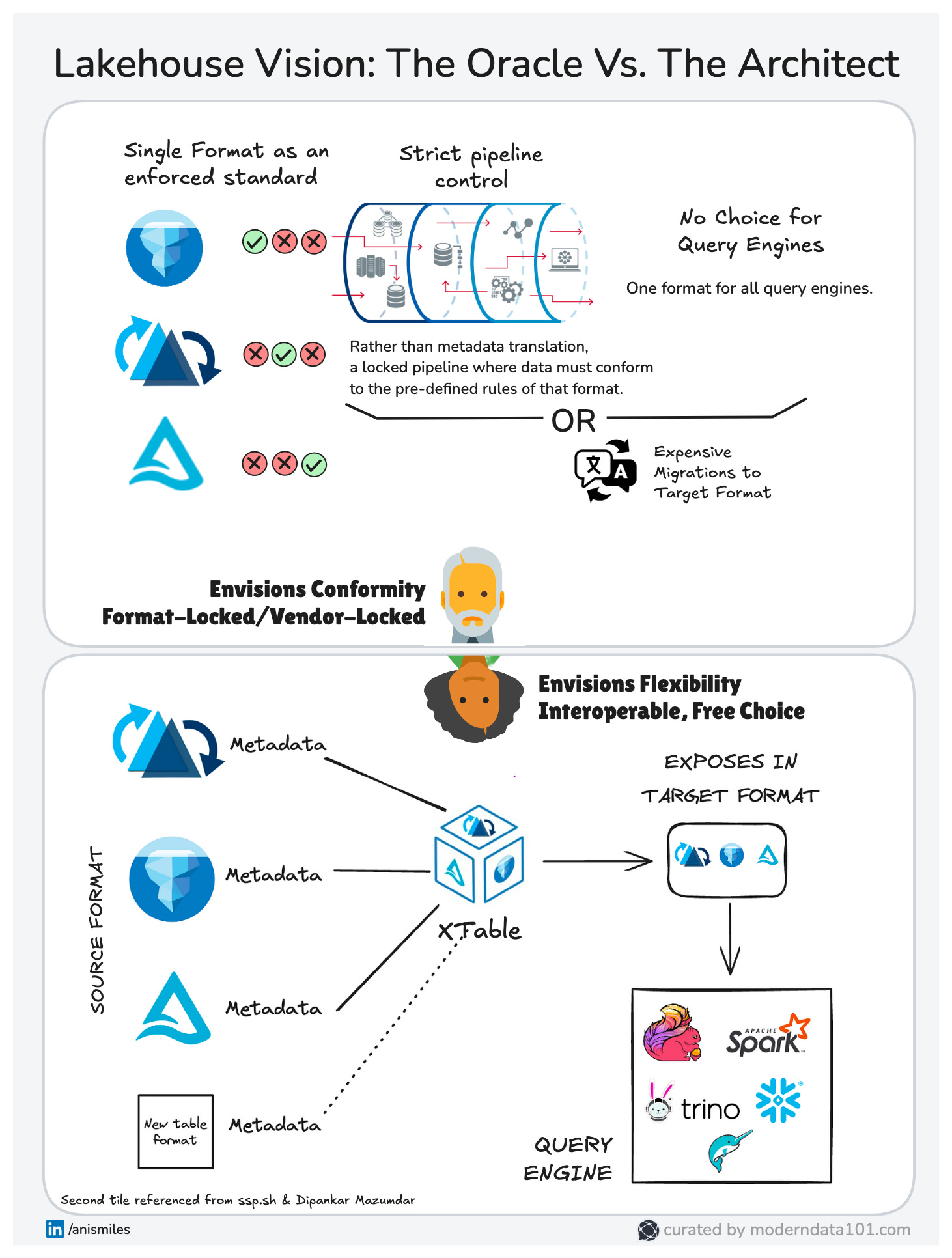
But what happens when business needs evolve? What if different teams need different tools that speak different table formats? Just like the first Matrix, this rigid system eventually fails because real-world use cases demand flexibility. The future of the Lakehouse is not about choosing one format, it’s about interoperability. The underlying data may be in a specific format, but end-users are able to manoeuvre it through their preferred formats (illusion of choice).
Where formats like Iceberg, Delta, and Hudi coexist, and Apache XTable acts as the Oracle, translating metadata across them. Instead of forcing teams to conform to a single format, XTable introduces interoperability without breaking transactional consistency.
In the Oracle’s Vision of the Lakehouse, aka Lakehouse 2.0,
- No format lock-in – Choose Iceberg, Delta, or Hudi without constraints.
- Seamless interoperability – Read/write across multiple engines without costly conversions.
- Evolvability – The lakehouse adapts to business needs, not the other way around.
Instead of forcing a single “perfect” format (the Architect’s mistake), the new design allows organizations to move fluidly between table formats.
- XTable detects the table format (Iceberg, Delta, or Hudi).
- Maps the metadata to an intermediate abstraction layer.
- Exposes the table in a compatible way to query engines and apps.
- Ensures transactional consistency across different formats.
- Enables format-specific optimizations (e.g., partition pruning, snapshot isolation).
Strong Validation for the Need of a Lakehouse 2.0 Paradigm
Amazon’s announcement that S3 now natively supports Apache Iceberg was more than just a feature release. It was validation for the open format architecture. It tells us that cloud vendors are no longer content being passive storage providers.
If Lakehouse 1.0 was about unifying lakes and warehouses, Lakehouse 2.0 is about disassembling that unification into composable parts. Open table formats. Multi-engine compatibility. Vendor neutrality. That’s the thesis—and AWS just validated it with this move.
This integration is proof that the industry is moving toward a data stack that’s open in structure and open in spirit. Where storage doesn’t dictate compute. Where data doesn’t live behind proprietary glass. Where infrastructure is built for interoperability, not lock-in.
The Control Is Moving Up the Stack
But when the base layers open up, the strategic control doesn’t disappear—it simply moves. If storage and table formats are now open and accessible, then the next battleground becomes the metadata and catalog layer. Governance, lineage, access control, semantic modeling—these are now the real differentiators.
Databricks has Unity Catalog. Snowflake is betting on Unistore. These aren’t just features; they’re attempts to regain influence over the stack now that compute is swappable and storage is universal. Because if the data itself is no longer locked down, then owning the interface to understand, trust, and secure that data becomes the new source of power.
But hold on. Our librarians didn’t want to be locked into another layer of shelf-istry. How to have THAT shelf that opens up all layers, not just storage? Enter the Second Generation of the Lakehouse Architecture.
Introducing Lakehouse 2.0: What Changes?
Lakehouse 2.0 is the realization of the original promise, finally fulfilled.
We’ll dive deep into the nuances in the next release, next week. Hope you’re following along.
Get notified & Subscribe to Support Our Work 🧡
Author Connect


Something New Brewing ♨
The Modern Data Survey Report is dropping soon; join the growing waitlist!

.jpg)





