




TABLE OF CONTENT
The first generation of computers with room-sized machines powered by vacuum tubes was revolutionary. For the first time, humans could automate complex calculations, simulate ballistic trajectories, and model weather patterns.
But they came at a cost: they were massive, fragile, expensive, and difficult to maintain. Still, institutions clung to them. Why? Because they had invested in the tools, trained people to keep the vacuum tubes from overheating, and built workflows around their constraints. The world was built around it. Governments spent millions. Universities trained entire departments to keep them running. Maintenance was a job, not a footnote. Punch cards were normal. People knew how to work the machine.
Then, the second generation arrived. Transistor-based machines. Smaller, faster, cheaper, dramatically more reliable. A technological leap that made the old way seem primitive almost overnight. And yet, the resistance was real. Organisations didn’t want to abandon their investments. Engineers skilled in vacuum tube maintenance felt their hard-won expertise slipping into obsolescence. Executives feared the risk of adopting a technology that, while promising, was still "new."
At the same time, a wave of support surged. Government agencies driven by the urgency of war-induced economies needed faster, more reliable machines. Universities seized the opportunity to advance computing. Businesses, once they saw the cost savings and performance gains, quickly followed.
The economics flipped. By the early 1960s, vacuum tubes were effectively obsolete. It wasn’t just technical superiority that won. It was the combination of better economics, broader support, and existential urgency that pushed the shift faster than anyone expected.
A Shift to the Second Generation of the Lakehouse Architecture
The first wave of the Lakehouse promised a unified platform for all data workloads: analytics, AI, and real-time. But the early implementations carried their own version of "vacuum tube constraints": centralised catalogues, proprietary compute engines, vendor lock-in, fragile integrations. Teams learned to work around them. They built pipelines, trained specialists, invested heavily. The world was built around those constraints.
But now, something has changed.
Open table formats like Apache Iceberg, Delta (open spec), and Hudi are redefining the foundation. Storage and compute are decoupled. Governance and metadata are moving toward open, unified standards. AI models, real-time apps, and business intelligence can now all share the same architecture, without being locked into one vendor’s stack.
The urgency is different, but just as real. This time, it’s the AI race driving acceleration. Every company needs (more than “wants”) to deliver faster insights, smarter applications, and real-time intelligence. And the old constraints are too heavy to carry forward.
📣 If you haven’t read Part 1 of this series, where we explore why Lakehouse 1.0 fell short and why the ground was ripe for disruption, start here first.
Lakehouse 2.0: The Open System That Lakehouse 1.0 Was Meant to Be | Part 1
Lakehouse 2.0 is not an iteration, but a realisation of the original promise. A second attempt at the Lakehouse vision, this time with the right primitives: open table formats, swappable engines, decoupled governance, and true data ownership.
The Lakehouse 2.0 Architecture: Composable by Design
So, what does this new architecture actually look like? Aside from a technical upgrade, it is a shift in structure, way of working, and mindset. Built around openness, modularity, and real-time interoperability, Lakehouse 2.0 sheds the vertical stacks of the past and embraces a composable design.
A Data Architect is entrusted with designing the invisible scaffolding upon which data flows, transforms, and ultimately creates value. This isn't only about systems design, but about aligning the structure of data with how an organisation thinks, acts, and evolves.
This means embedding semantic models, ontologies, and knowledge graphs as first-class citizens within the architecture, not as afterthoughts, but as foundational elements. These components give shape to raw data, helping it carry meaning, context, and structure as it moves across systems. A Data Architect ensures that data doesn’t just exist—it is interpretable, governable, and aligned to the mental models of the business.
Let’s break it down.
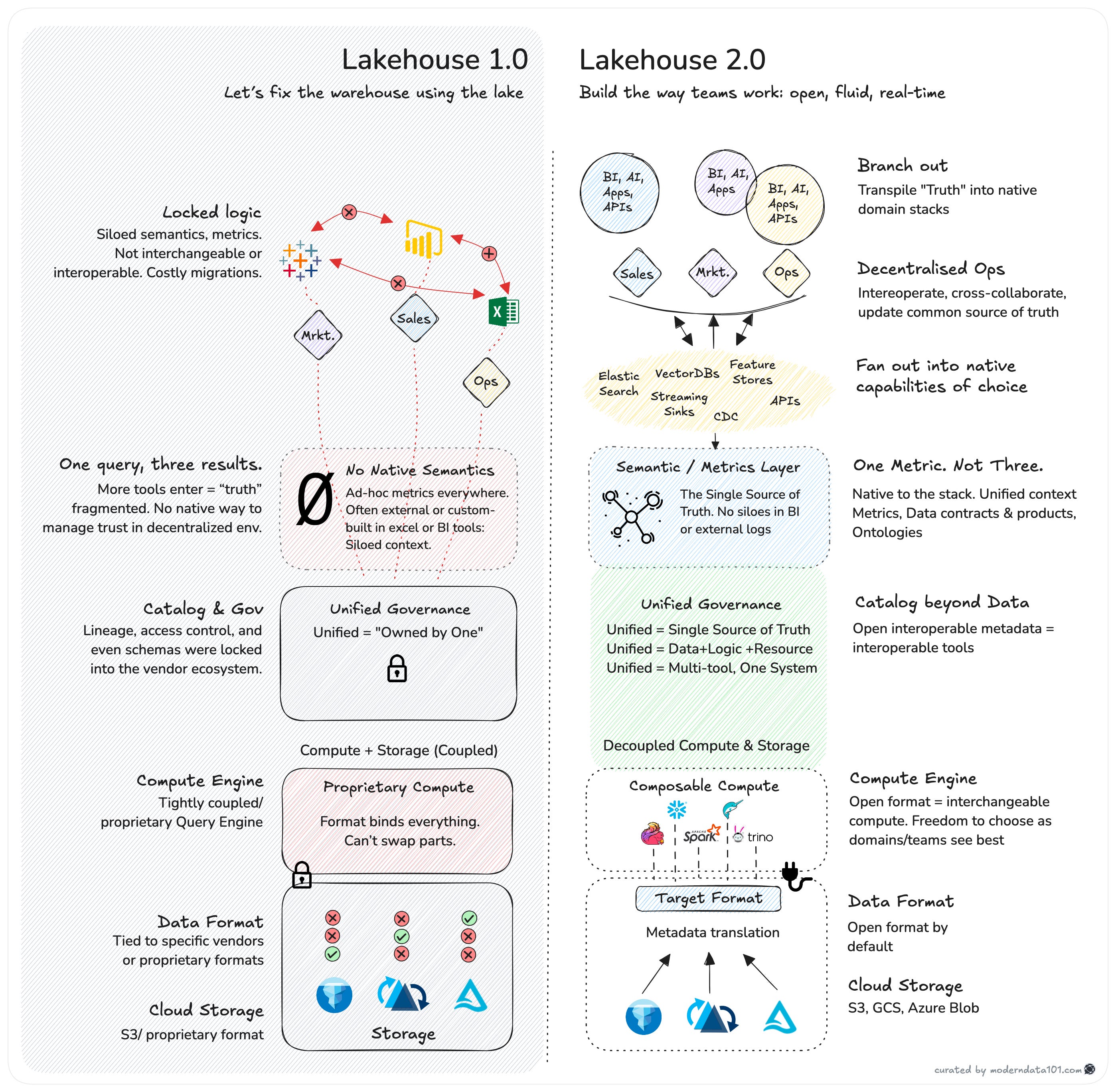
Consumption Layer
At the very top, this is where data becomes real, surfaced into BI dashboards, AI models, internal APIs, and user-facing apps. This layer is no longer limited to passive analytics.
You don’t need to manually recreate the same logic in five different BI tools anymore.
Let’s say your teams use both Power BI and Tableau, and five tables are being analysed by different teams in each. Today, they’re all modelling the same thing separately in each tool. They’re defining relationships, metrics, and dimensions inside these tools, which aren’t interoperable, versioned, or accessible to data scientists or other systems.
That’s broken.
Instead, with the new architecture, you define the semantic model once, declaratively, as part of the data product. And then we transpile that definition into native models for Power BI, Tableau, Superset, or even a Jupyter Notebook.
Think of it like writing Java. You don’t write for every operating system: you write once, compile to bytecode, and the JVM handles the rest. If you treat Power BI, Tableau, etc., like different JVMs, you write once, generate the bytecode, and the experience feels native everywhere.
Semantic / Metrics Layer
A critical new addition. The semantics of your data (metrics, definitions, rules) are now part of the architecture. This is the layer that brings trust and clarity. This layer standardises meaning across teams and tools. This is where data contracts begin to form: enforced not just by code, but by architecture.
In today’s fragmented data ecosystem, we have disparate tools, like Power BI and Tableau, often modelling the same underlying data. Let’s consider a retail shop that uses both platforms. There are five tables at play, each being modelled separately in Tableau and Power BI, with different teams working in different environments.
While both tools define relationships, formulas for metrics, and dimensions, they do so in isolation. This is problematic because end users, such as analysts and data scientists, are excluded from this process. They cannot access or modify the logic in these tools directly.
This is where the power of a unified semantics comes into play. Instead of having separate definitions for every tool, you are able to define the semantic model declaratively as part of the data product. Then automatically transpile this model into formats that can be consumed by Tableau, Power BI, Superset, and even Jupyter Notebooks.
By centralising the logic, you bring true decentralisation of domain operations. We eliminate complexity and ensure that the consumption of data remains independent of how the logic is applied. The model becomes the core of the product, making the logic easily accessible and version-controlled.
For example, you can connect Power BI to a read replica of your operational database today, whether it's PostgreSQL, DB2, or MySQL, but that’s not enough. The critical question remains: Where is the business logic? Where are the formulas for the metrics? Where is the semantic model itself?
Today, these elements live in two distinct places. One in the data tools and the other in the operational database. And managing and versioning them becomes a challenge. But with a unified semantics, you not only make the tools work together seamlessly, but you also create a single, auditable, and coherent source of truth for your entire data ecosystem. This is the essence of a true data product: intelligently designed, easily managed, and incredibly powerful in its simplicity.
Compute & Query Engines (Composable)
No more one-engine-to-rule-them-all. Snowflake, Trino, Flink, Duckdb, Spark—take your pick. Lakehouse 2.0 is built to support multiple engines instead of somehow tolerating them. Compute becomes composable. Swappable. Optional even. You bring the engine, and the architecture adapts.
The idea is to make the data queryable in the right way, for the right use case, with the right cost-performance tradeoff.
You can plug in BigQuery, for example, and spin up per-query pods per user session. It’s great when you want elastic scale, but don’t mind slower performance or latency, and you’re optimising for cost. Or, say you’re solving for a very specific business case, like powering dashboards via Power BI. You might assign a dedicated Trino cluster just for that. It's purpose-built, fast, and scoped.
If your dataset is small, you don’t need to bring in a heavyweight engine like BigQuery at all. You can run a lightweight service that consumes low memory and exposes a Postgres interface. It would be lightning fast and native to API-driven use cases.
The core idea is that we treat compute engines, interfaces, and query layers as building blocks, and we compose them based on the purpose of the data product. The system adapts to the need, not the other way around.
Governance (Unified APIs) + Metadata + Open Table Format
This is the new strategic battleground. With open table formats decoupling storage, the metadata network becomes the brain. It’s where access, lineage, roles, and policies live.
Here lies the heart of the shift. Apache Iceberg, Apache Hudi, and Delta Lake (open spec) are no longer add-ons but the baseline. Metadata is no longer buried or bespoke. It's structured, discoverable, and interoperable. This is what unlocks multi-engine access, time travel, and schema evolution. This is the connective tissue of the modern lakehouse.
Cloud Storage (Open, Decentralised)
At the base, nothing proprietary. Just object storage (S3, GCS, ADLS) backed by open formats. You own your data. You control your access. The lakehouse is no longer just a cheap store, but the bedrock of a programmable, decentralised data ecosystem.
More Architecture-Native Capabilities
Plug-and-play native capabilities. The flexible architecture enables you to fan out into specific architectural constructs that are suited to the nature of the business.
- Elasticsearch / OpenSearch: Direct fan-out for real-time search indexing
- Vector DBs: For RAG / LLM-driven search on embeddings
- Feature Stores: Streaming & batch features for ML systems
- Change Data Capture (CDC): Propagate changes across domains or systems
- Streaming Sinks: Native support for Kafka, Pulsar, EventBridge, etc.
- Graph engines: Overlay topologies or relationship models
- Data Contracts: Validate and publish schemas upstream/downstream
The Second Generation of the Lakehouse Inherently Supports Decentralisation
When we talk about using the Lakehouse as the central pivot for data management, we’re not advocating for a monolithic infrastructure. What we’re really suggesting is the centralisation of the way of working and the strategic choices around technology.
Say one domain chooses Databricks as the foundational technology and another picks Snowflake. That’s completely acceptable. Both technologies can expose APIs, and both can be interoperable through these interfaces.
However, when the work one domain does with its data intersects with the work another domain is doing, we encounter the issue of technology impedance mismatch.
So, it’s not about standardising on a single technology stack. Instead, we’re recommending a holistic, declarative framework to address these challenges. Think of it as an architecture that’s cloud-first, where the underlying infrastructure (managed by providers like Amazon) becomes irrelevant. The VMs are just VMs; what matters is that they're available via a Terraform interface, providing the flexibility to manage them in a consistent way. You don’t need to care whether it’s a GPU, CPU, or high-performance node; what matters is the uniformity of access and operation.
The new architectural paradigm of the lakehouse does not suggest that every domain should share the same instance of a lakehouse. Instead, each domain should solve its problems using the construct of a lakehouse or a similarly designed API framework.
The key idea is that, even if we have a large ETL pipeline exposing an API, we should be able to reuse portions of that work within different domains. The organisation, as a whole, becomes leaner and more efficient because the underlying technology is consistent. I can have my own lakehouse instance; you can have yours. Our systems expose APIs to each other, and if cross-correlation is needed, we can do so because the technology foundation is aligned.
Think of it as creating a shared guideline for the organisation, akin to a style guide for coding. Everyone who writes code in a company follows a set of documentation standards, naming conventions, and modularisation practices. This is the essence of a Data Developer Platform (DDP), closely aligned with the concept of an Internal Developer Platform (IDP). Just like how large engineering organisations establish standards around technology choices, library selection, and commenting style, the new architecture itself is advocating for the same level of consistency and discipline in data systems.
Ultimately, it’s not about standardising on a specific technology but standardising the way we think, the way we approach these challenges, and the way we structure our work. Making the way we think and operate as consistent and efficient as the technology itself. And this, at its core, is the fundamental shift.
Decentralised Ops & Domain Autonomy
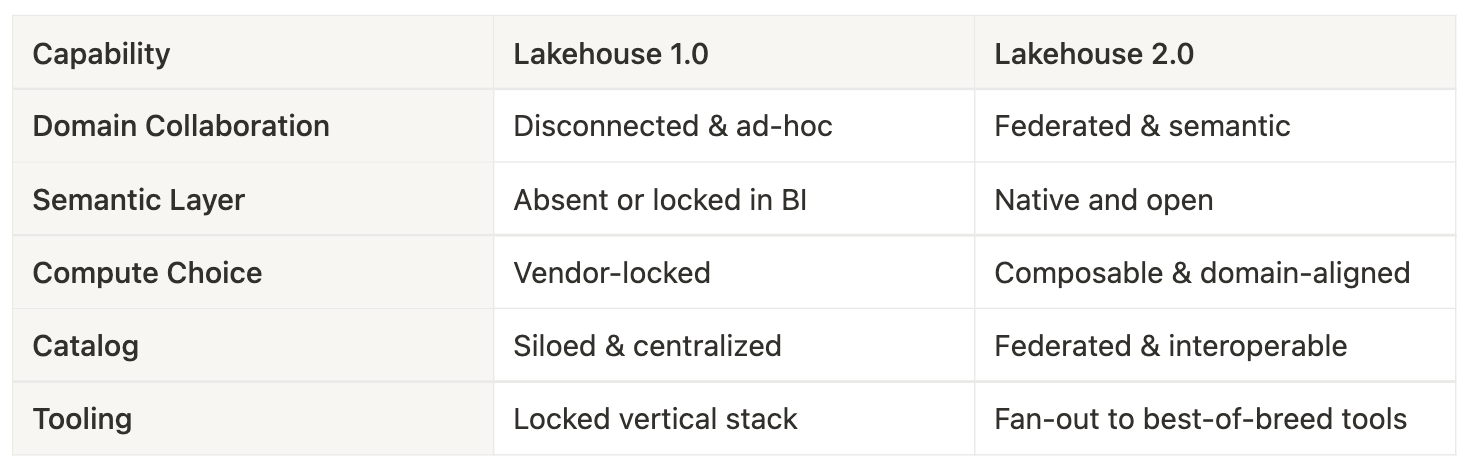
Lakehouse 1.0 kept logic and semantics siloed in BI tools or spreadsheets. Teams like Sales, Marketing, and Ops worked in disconnected bubbles, re-defining “truth” repeatedly.
The new architecture of the Lakehouse enables decentralised operations where domains (Sales, Marketing, Ops) can interoperate, cross-collaborate, and understand a shared context, aka source of truth. Teams are not blocked by central IT. Instead, they own and evolve their local models while contributing to the global truth.
Semantic & Metrics Layer as a Federated Source of Truth
Central to decentralisation is the Semantic Layer. It provides shared definitions for metrics, data contracts, and product ontologies. No more hardcoded metrics inside BI tools; now there’s a unified, governed layer all domains plug into. This layer ensures semantic interoperability.
Composable Compute & Interchangeable Engines
Compute is no longer tightly bound to storage or table formats. Domains can plug in Spark, Trino, Dremio, etc., whatever works best, to read/write the same open-format tables. This allows for domain-aligned architectures without platform lock-in.
Fan Out into Native Capabilities of Choice
As you continue to push and shove workloads, you eventually need to fan out to other tools, like Elasticsearch, to handle things like search capabilities. But now you’re hitting another challenge: the system can’t scale as efficiently as needed. As you push more data, you’re forced to deal with increased latency and costs, especially when you’re trying to index data quickly in Elasticsearch.
At this point, the solution becomes more complex. You’re adding layers of infrastructure just to manage the workload: bigger clusters, separate indexers, dedicated search processes—all of which increase operational complexity and cost. And what’s the end goal? To expose a data product somewhere outside the system.
This is where the elegance of the new lakehouse architecture takes over. Instead of cramming everything into one monolithic system, the lakehouse allows you to funnel your workload efficiently into native capabilities that scale seamlessly.
For example, you can fan out into a vector database or a feature store for machine learning. These capabilities are native to the lakehouse environment and don’t require additional spin ups of complex, disparate systems like Elasticsearch or processing clusters.
The beauty here lies in the simplicity and scalability of the architecture. The lakehouse serves as a single foundation, but from it, you can easily extend to other services, leveraging the full spectrum of modern data capabilities. You don’t need to worry about managing disparate technologies or worrying about bottlenecks. It’s all integrated, and the decision-making becomes much more straightforward:
Use the right tool for the right job, all within a cohesive, unified ecosystem.
Implications: Why Does the Lakehouse 2.0 Matter
The shift in architecture is a shift in how teams, companies, and the entire ecosystem operate. For data teams, composability means freedom. The freedom to pick the right tool for the job. Whether that’s DuckDB for local dev, Trino for federated queries, or Flink for streaming. No more being boxed into a single compute engine or platform.
You own your stack, and that changes how you build.
For businesses, it’s about control and efficiency. Lakehouse 2.0 severs the dependency on vertically integrated vendors. You’re not paying for compute you don’t need, or locked into DBUs and usage ceilings. Your costs become predictable. Your leverage improves. You negotiate from strength.
And for the broader ecosystem, this is the unlock. A composable architecture enables real interoperability, which means startups can build better tools, and clouds can focus on infrastructure, not control planes. Innovation expands, not contracts. A thousand tools can bloom, and they’ll all speak the same language.
Thanks for reading Modern Data 101. Subscribe for free to receive new posts and support our work.
Author Connect


Insights from the Experts, Leaders, & Practitioners ♨
The Modern Data Survey Report is dropping soon; join the waitlist here.







