
.avif "Charlotte Ledoux")




TABLE OF CONTENT
The rise of the Data Products Approach is empowering some early adopters (business teams) and is about to empower a much wider band of businesses with growing credibility. For now, we see many data product owners/managers being appointed. They usually manage a small interdisciplinary team delivering data products.
This promising pivot is precisely why we should update the way we do Data Governance. Reap some benefits to ease our lives as governance stewards and enjoy a better experience as data consumers!
Impact of Data Governance 🎯
Data Governance is a data management strategy developed to protect not just data consumers and customers but also to protect the business.
Outcomes can't just be good governance. Outcomes have to be running better businesses.
~ Eric Hirschhorn | Chief Data Officer at The Bank of New York Mellon Corp.
As the name suggests, data governance boils down to governing data throughout its journey—from generation or acquisition to data activation and application.
With dedicated tracks popping up around discovery, observability, and semantics, sometimes Governance tends to get sidelined as a much narrower vertical than it actually is. In fact, all the above and more fall under the umbrella of data governance.
Essentially, a solid governance strategy ensures accessibility, security, privacy, accuracy, and usability for the data owned by the organisation. This is implemented through governance policies laid out at all critical touchpoints in the data roadmap, addressing questions like how to collect the data, how to organise it for consumption, who or what can access the data, and how to even dispose it.
Consequently, the governance strategy the organisation chooses to adopt impacts all data citizens with the organization and even external parties associated with the data.
If you really think about it, data products are essentially a superset of data governance, tackling similar problems (discoverability, addressability, understandability, accessibility, trustworthiness, & security) with the additional product counterpart of purpose-driven data, value, interoperability, and reproducibility. This makes data governance one of the key pieces for establishing any reedeemable effort in the data product arena.
~ Animesh Kumar | Chief Technology Officer, DataOS (by Modern)
Data governance has especially become critical today, with authorities placing increasing regulations on data and AI to protect user data and businesses, such as the GDPR, CCPA, HIPAA, and the latest: EU’s AI Act.
The Problem 👾: Centralised Governance
Let’s address how centralised governance is burdening data and governance teams.
Many companies started with centralised data governance, and that’s perfectly understandable. Remember that data centralization in data warehouses has been THE topic for the last 10-15 years.
How centralised governance came up
Data warehousing provides indeed a way to store and organize large amounts of data in a structured and easily accessible manner. It has enabled better data analytics for lower storage costs.
As a result, data governance was mostly organized centrally around the data warehouse. The centralizing data access created a less complex environment for data, making it easier to monitor and control the use and protection of data.
The ecosystem has changed
But right now, we see a bottleneck for the central data governance team, which is receiving demands from all business teams, such as :
- Data quality alerts from various dashboards
- Data mapping between sources issues
- Policies documentation requests, especially on data privacy with upcoming generative AI initiatives
Why is it happening?
Because the ownership is on the central data governance team → leading to delays in addressing these critical issues. This bottleneck hinders the overall efficiency and responsiveness of the organization, as business teams are dependent on timely resolutions to continue their operations smoothly.
Another drawback is that this central team only has a partial view of each domain’s context. At this stage, it’s practically impossible for one central authority to own deep-seated knowledge of multiple business verticals. Just this inability fails the centralised system since governance, as we saw in the impact segment, is positioned to make data understandable and usable as well.
Say you’re selling clothes through an e-commerce business, and you receive a request to define a new category called Hoodies. Many questions are targeted towards the central team: Is it in the Jackets or Sweaters segment? What reference code should be assigned to this category? Which items can be defined as Hoodies? What’s the acceptable pricing range? What’s the forecasted volume of this new category?
All these data questions can be answered by business experts in the “Fashion” domain.
Overall, there is an urgent need to either expand the capacity of the central data governance team or to decentralize some of these responsibilities to specialized sub-teams within the data domains.
A Tangible Solution 🕹️
Let’s find out how the data product approach impacts Data Governance initiatives.
Domain Ownership: Own & Implement Deep Business Knowledge
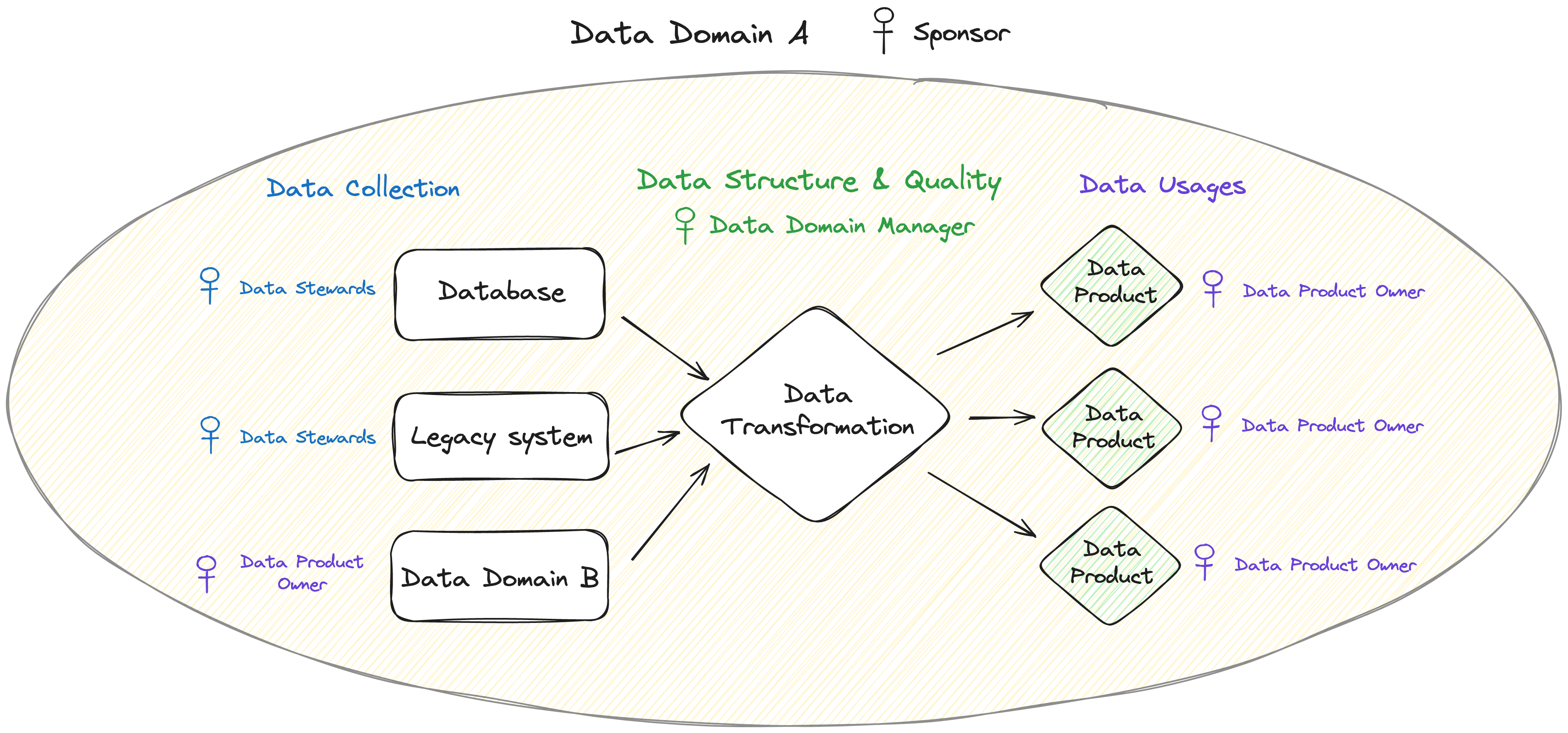
By establishing specific roles within data domains, data governance becomes collaborative and more effective. This clear ownership fosters accountability and ensures that data is managed and maintained properly.
Let’s have a look at these roles :

📝 Editor’s Notes
For organisations with limited resources, we recommend a hybrid decentralisation strategy. Here’s an overview of the same: A hybrid approach for transitioning to de-centralisation.
Consequently, Build Reliable Semantics
Let’s review our previous example.
Does the new category stand in the Jackets or Sweaters segment? What reference code should be assigned to this category? Which items can be defined as Hoodies? → All of this falls under validation of the Data Product Specification.
What’s the acceptable pricing range? → Pricing monitoring (monitoring an SLO on semantics)
What’s the next month’s forecasted volume for this new category? → Volume forecast (Data Product Measures & Metrics)
All these data products require :
- Easy-to-use collaborative interfaces with updated and consistent fashion data & semantics → That’s the job of the Data Product Owner
- Structured fashion data with a common denomination of categories, reference codes and characteristics (fabric, cut, size, etc.) for all data products → that’s the job of the Data Domain Manager
- Trusted sources as inputs for complete and reliable fashion data → that’s the job of the Data Steward
A data product ecosystem promotes a culture where everyone in the organization understands the importance of data stewardship. Don’t limit your efforts to building a data stewardship program!
But… are there technologies to support a decentralized organization?
Yes, a “Data Product as a Stack” approach integrates both localized and global data governance through a centralized setup.
A unified platform layer is provided to manage all data products. Key tech elements must indeed be common to all data domains to ensure consistency in data handling, governance policies, and security measures across the organization.
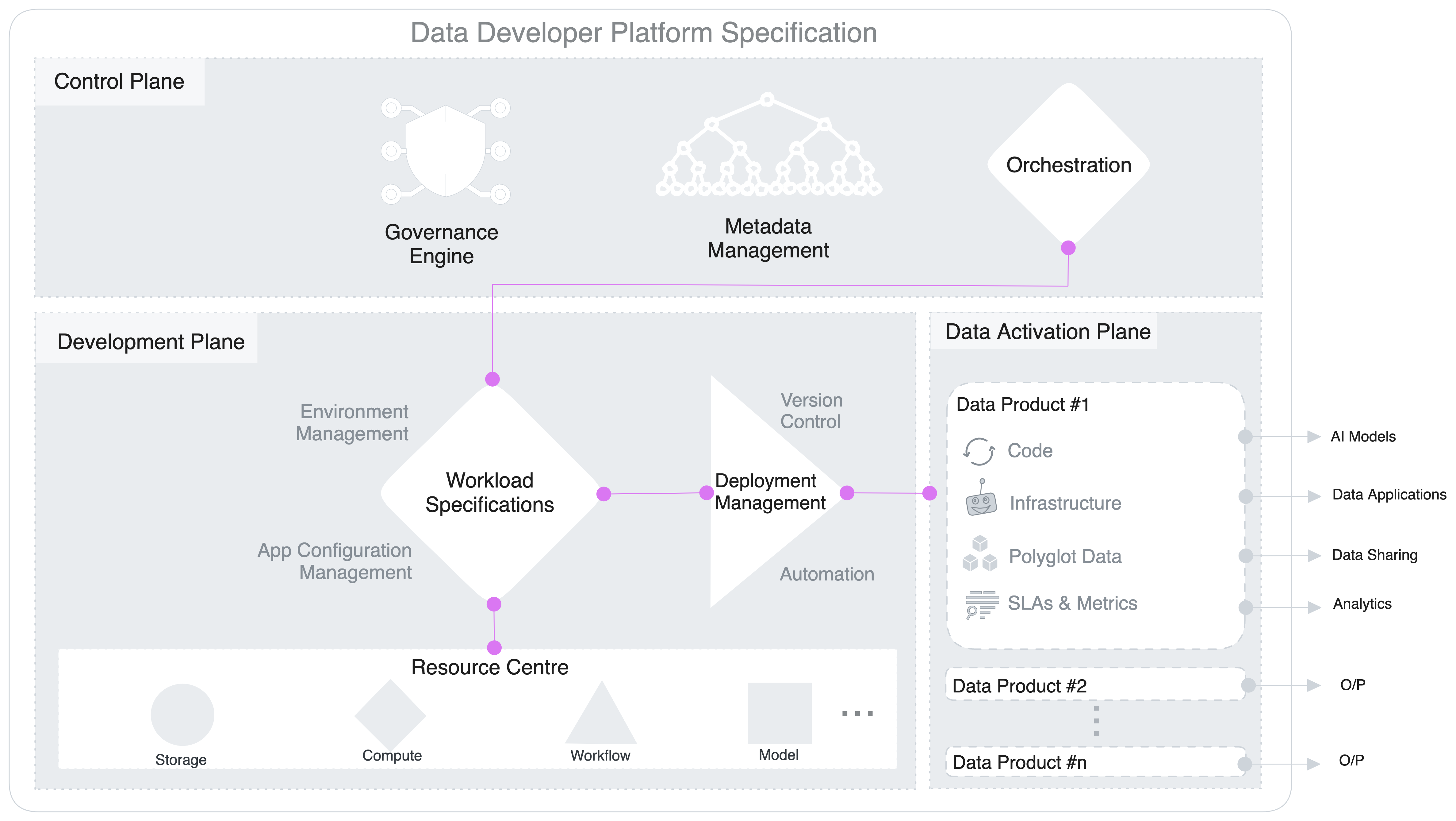
Below is a one-level deeper tech dive into the architecture of a unified platform (borrowed from the standard data developer platform standard). Note how the governance engine sits in the control plane, but enables federated (distributed) governance for localised as well as global policies for different data products running in the data activation plane (for multiple domains). The policies are
- controlled by the individual domains
- and are only enabled through central engine (which also helps in e2e policy visibility and conflict resolution without compromising domain control)
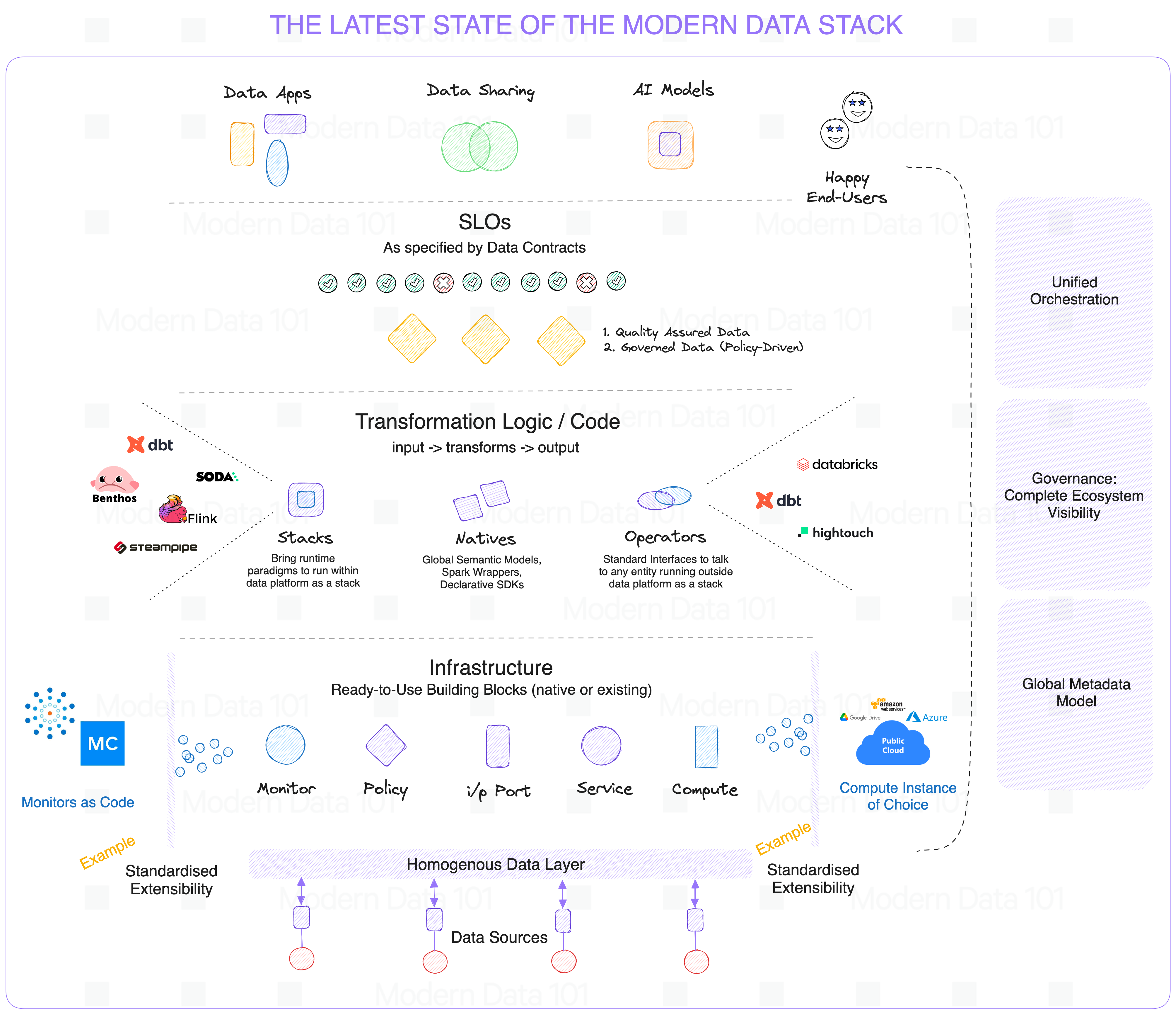
What is mandatory on this unified platform is:
- A centralized data catalog (or data marketplace, depends which fancy word you prefer) to maintain metadata of all data products. This catalog ensures discovery and accessibility of data products but also transparent data lineage, quality metrics, and usage policies.
- Data quality tools to help identify and resolve anomalies and inconsistencies
- A master data management solution to ensure a trusted view of business-critical data by managing and integrating master data across domains
- Automation tools to reduce manual intervention on data cleaning, data preparation and monitoring through alerts
📝 Editor’s Note
Learn more about some core technical capabilities of unified platforms here
Where Governance as a Point Solution Falls Short
In summary, the primary reason most existing governance solutions fall short is that they are point solutions devoid of the capacity to fully interoperate with all other data entities.
For instance, two different point tools, say one for cataloguing and another for governance, are plugged into your data stack. This incites the need not just to learn the tools’ different philosophies, integrate, and maintain each one from scratch but eventually pops up completely parallel tracks.
The governance tool starts requiring a native catalog, and the cataloguing tool requires policies manageable within its system. Now consider the same problem at scale, beyond just two point solutions. Even if we consider the cost of these parallel tracks secondary, it is essentially a significantly disruptive design flaw that keeps splitting the topology of one unique capability into unmanageable duplicates.
Whereas, in unified systems, we gain a common platform layer → the cataloguing tool would gain visibility of policies for discoverability in the governance tool, and the governance tool would be able to extend policies to the catalog items. This becomes possible due to an interoperable interface developed on top of the unified architecture, essentially eliminating dual catalogs and governance engines.
📝 Editor’s Note: Learn how interoperability in the context of governance is enabled via unified systems here ⬇️
Related Read 📖 : Role of Interoperability in End-to-End Data Governance | Issue #43
Author Connect













