



TABLE OF CONTENT
Organized, structured, and semi-structured semantic knowledge systems are quickly emerging as a requirement for achieving highly performant LLMs and AI systems. Often overlooked, many technologists consider a semantic knowledge system overly simplistic, consisting of text labels or annotations.
In contrast, others believe it is too labor-intensive and unworthy of investment. The natural response to this confusion has amounted to over-utilizing out-of-the-box public taxonomies. One of them is the Google Product Taxonomy, leading to homogenous knowledge ecosystems, a cookie-cutter approach that does not meet the needs of a domain or business.
Failures in AI implementations and challenges evidence failure to model and represent an organization's unique aspects and attributes in deriving context and meaning from knowledge management systems such as knowledge graphs.
The Need for a Structured Approach
Indeed, a semantic knowledge system requires investment in humans and tools but does not have to be relegated to simple annotations or laborious human efforts. Due to the lack of existing frameworks and workflows, the construction and maintenance of semantic knowledge management systems exist as a black box, making it difficult for businesses to determine the exact scale of investment, both long-term and short-term.
In addition, direct returns on investments can be difficult to measure as the benefits of a semantic knowledge system tend to be secondary and mostly derived from successes measured in RAG implementations, entity management systems, and information retrieval metrics.
By structuring knowledge management stages and phases substantiated by logical sequences and workflows, a formal semantic knowledge management program can be scoped, scaled, and positioned as a product and unique domain of expertise.
With the formal establishment of a robust and dynamic knowledge management program, organizations can have more confidence in this infrastructure investment, hiring humans and leveraging machines to refine data and information infrastructures to guide the construction and maintenance of semantically rich ecosystems.
📝 Related Reads
The Semantic Layer Movement: The Rise & Current State
Semantics and Data Product Enablement - A Practitioner's Secret | Frances O'Rafferty
Enter The Librarians—Lessons from Library Science
The Library and Information Science domain offers principled, logical methods and frameworks to organize and structure data to become information, which, in turn, becomes knowledge when made available to all users, humans, or machines.
Librarians have codified these methodologies and strategies to organize complex information ecosystems to drive accuracy and reliability in information retrieval tasks.
Because librarians have successfully leveraged machine learning (ML) and artificial intelligence (AI) as workflow and cataloging tools for more than ten years, the library science domain offers repeatable methodologies for building scalable and extensible semantic knowledge management systems that drive accuracy and reliability with AI systems.
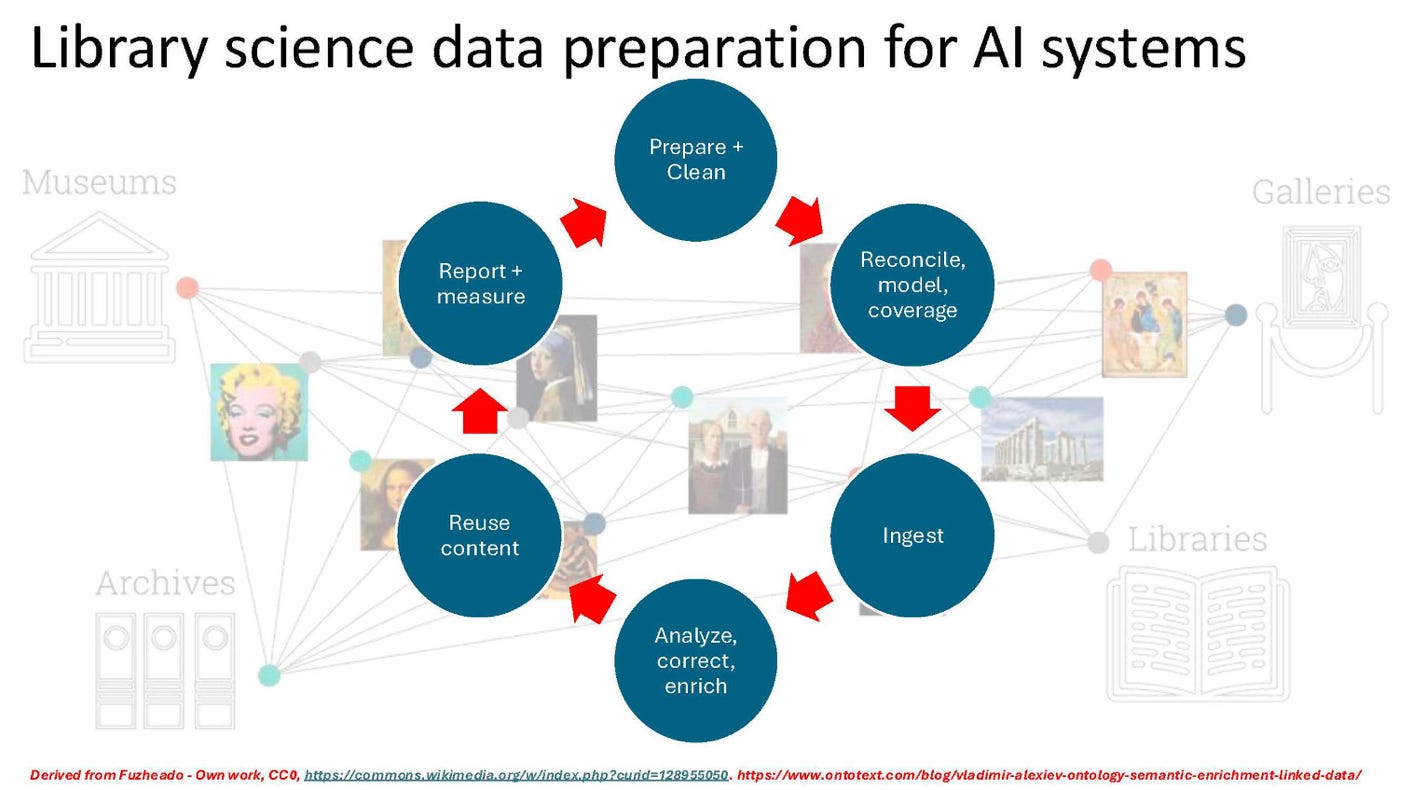
Taking a lesson from librarians, technology domains must prioritize knowledge management workflows and processes to support reliable and resilient semantic knowledge management systems and position these systems as worthy of investment from the business.
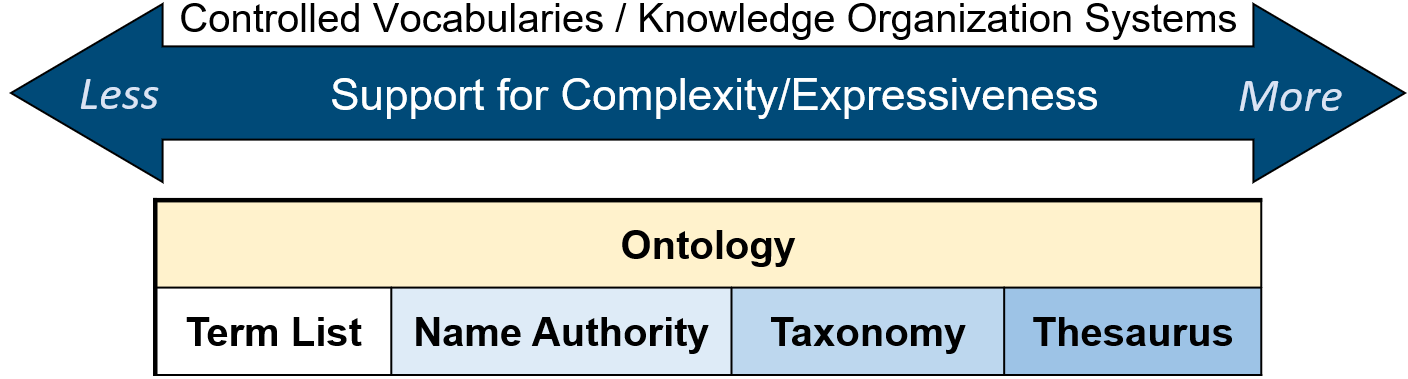
The Ontology Pipeline: A Systematic Approach
🔑 Derived from the workflows of librarians, the Ontology Pipeline offers a systematic methodology for constructing semantic knowledge management systems. The Ontology Pipeline consists of iterative building blocks, each phase preparing for the next building stage.
The iterative build process is broken into building blocks to integrate data cleaning and preparation tasks into the semantic engineering workflow. Beginning with the controlled vocabulary, data, and information being cleaned, structured, and defined, supported by metadata standards, normalizing entity value pairs within a data ecosystem, data, and information are then prepared to be structured as a taxonomy, a hierarchy defined by parent-child relations.
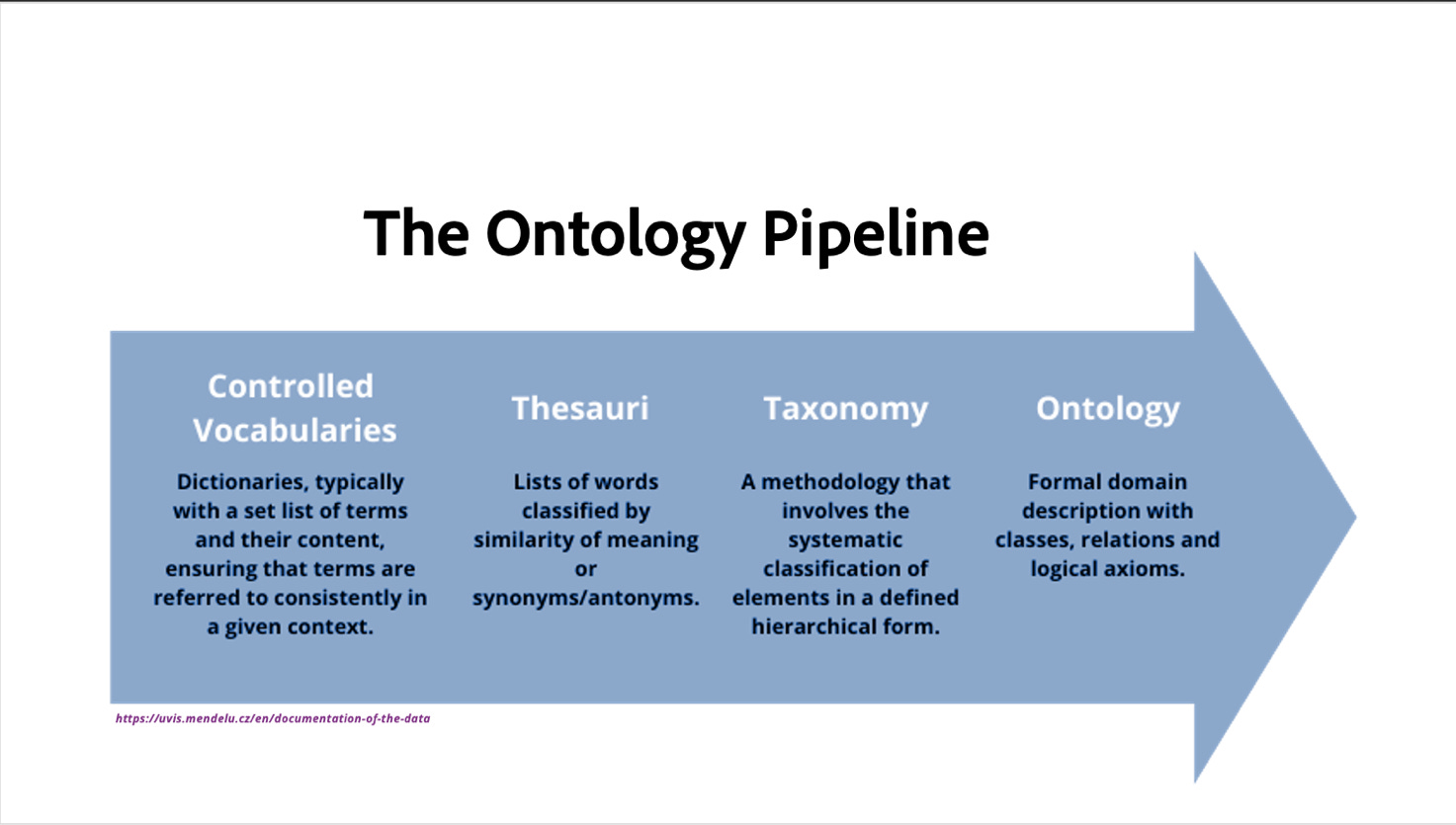
The taxonomy serves as the foundation for the construction of thesaurus, where equivalent, transverse, and matching relations are encoded using a lightweight, upper ontology. The thesaurus prepares the base, ontology structure, necessary to model a more complex and dynamic ontology designed to support descriptive context and semantic reasoning.
Finally, with all the building blocks in place, the combined effort results in a semantic, RDF knowledge graph, consisting of the required, semantic elements or layers of the graph.
The Ontology Pipeline is designed to codify a framework for the architecture and construction of semantic knowledge management systems. This tangible workflow and process enables better estimation of investment requirements, human and machine.
⚠️ Without the Ontology Pipeline, organizations struggle to understand levels of effort and investments, let alone how to derive metrics, to measure benefits, system performance, and returns on investments.
When the business understands the composite of a semantic system, leaders and stakeholders have more visibility into the requirements of a semantic knowledge management system. With clear goals and outcomes in sight, organizations can build and maintain semantic knowledge management systems with confidence, knowing that these investments are essential to support data infrastructure, data transformation, and AI initiatives.
Controlled Vocabulary
A controlled vocabulary is the first building block in building semantic knowledge systems. A controlled vocabulary is synchronistic with data cleaning and preparation tasks. As part of the process and workflow of vocabulary construction and refinement, data must be de-duplicated, merged, and defined to arrive at a clean, disambiguated vocabulary fit for purpose.
De-duplication includes reconciling synonymous terms to clarify vocabulary. Best practices include creating definitions for each term or concept in a controlled vocabulary list so that all users and stakeholders arrive at the same meaning for the chosen vocabulary.
In this example from NASA’s controlled vocabulary index, Mission to Planet Earth has a definition. An indicator, UF, means “Use For” MTPE, which is the abbreviated acronym for Mission to Planet Earth.
This is an example of how duplicates, near duplicates, and synonyms can be resolved when architecting a controlled vocabulary. A controlled vocabulary is the first step towards creating unified domain vocabularies, building alignment across people and machine systems while supporting a shared and common understanding.

Metadata Standards
Now that we have controlled vocabularies, we develop metadata standards to encode the common understanding or “aboutness” of data and information. Metadata standards provide a schema-based control for databases and information systems.
Metadata elements provide the detailed fields necessary to describe data and information assets. Metadata elements are broken into their characteristics: STRUCTURAL (for machine readability), DESCRIPTIVE (for context), and ADMINISTRATIVE (asset maintenance and lineage).
While these are the most common types of metadata elements, practitioners and stakeholders have expanded these element types to extend the coverage of metadata types to include subject areas such as social or provenance. No matter the types of metadata elements, each metadata element type must be well defined, with clear direction as to what the element type is designed to handle.
With well-defined metadata standards, each metadata element is prepared to accept the controlled vocabulary as values. A metadata standard can support various workflows and data streams, often serving as the foundational architecture for entity value systems and concept models.
The controlled vocabulary serves to provide the controlled values or allowable values to pair with metadata elements. By implementing a metadata standard, a natural framework emerges for entity reconciliation, vocabulary management, and schema-based validation matrices, to enforce vocabulary control and semantics. In addition, metadata standards lend valuable insight into extended vocabulary needs, helping to scope future requirements in successive Ontology Pipeline steps.

In this example, the metadata element TITLE has the value of Mad Men Season 5, plot predictions. The metadata element TYPE says the article, indicating a content type. By normalizing the metadata element and the expected, allowable values, the metadata standard and controlled vocabulary work together to describe the asset, to deliver context and meaning.
Taxonomy
Often, the creation of controlled vocabularies and metadata schemas is overlooked in a rush to build taxonomies. Without the necessary data hygiene, where we resolve synonyms and duplicate concepts, as we do when building controlled vocabularies and metadata schemas, a taxonomy can be very difficult to build and quickly becomes unwieldy.
A taxonomy takes the controlled vocabulary and transforms it into a hierarchical structure. This is the beginning of creating relationships between concepts, broad to narrow or parent-child relations, on our way to a more mature, ontology-rich system.
These relations are helpful classification structures for machine learning algorithms that can be used for front-end navigation and for simply organizing assets. In addition, taxonomies are often utilized for tagging and annotation systems.

Often, taxonomies are built and maintained in spreadsheets. However, maintaining and building a taxonomy in a spreadsheet format can become unwieldy when managing and implementing at scale. Not to mention, a spreadsheet taxonomy often lacks the machine-readable semantic encoding structure necessary to support a full-fledged semantic knowledge management system.
To build a resilient taxonomy that is both human and machine-readable and optimized for AI systems, it is best to invest in semantic middleware tools, so that an emerging taxonomy can be structured using an upper ontology such as SKOS and aligned to standards that inform the middleware validation matrices, which checks for structural integrity and helps resolve issues such as recursive loops and relationship clashes.
While seemingly innocuous, the introduction of faulty logic, even within a base structure such as a taxonomy, can cause the proliferation of faulty logic throughout semantic knowledge systems. Therefore, it is recommended that a taxonomy be constructed according to ISOs and ontology logic, with validation matrices in place, to ensure the soundness of any taxonomic structure.
Taxonomy guidelines and validation usually include basic ontological reasoning based on standards. These guidelines and standards include:
- ISO 25964-1, Information and documentation — Thesauri and interoperability with other vocabularies
- ISO 25964-2, Information and documentation — Thesauri and interoperability with other vocabularies — Part 2: Interoperability with other vocabularies
- RDF (ontology) validation
- ANSI/NISO Z39.19-2005 (R2010) Guidelines for the Construction, Format, and Management of Monolingual Controlled Vocabularies
In kind, these standards and guidelines align with The Ontology Pipeline, documenting similar architectures and frameworks to support semantic logical reasoning, ontology construction, and validation matrices. Ultimately, when at the taxonomy build and management phase of the pipeline, it is critical to understand the impact of design decisions. These decisions include:
- How many levels should be represented by the taxonomy
- What is the determined level of granularity
- Will localization be enabled alongside the taxonomy
- Will the controlled vocabulary be deprecated or in play when the taxonomy is deployed
- How will new concepts and terms be integrated into the taxonomy
By building and structuring the taxonomy with ontological reasoning and according to standards and guidelines will ensure the taxonomy is prepared for the next phase of the Ontology Pipeline workflow.
Thesaurus
While the thesaurus can often be interchangeable in order of operations with a taxonomy, I prefer to mature a taxonomy to evolve into a thesaurus by extending ontologies used to structure the taxonomy. I always structure taxonomies to become thesauri because it is the baby step towards a semantic, ontology-based knowledge management system. A thesaurus handles ambiguity by forming associative relationships between terms beyond the relationships within a hierarchy: the parent-child relations.
A thesaurus further encodes these structures, often with a lightweight and mid-level ontology like SKOS-XL or Simple Knowledge Ontology System. Much like a thesaurus used to discover near terms or synonymous concepts in vocabulary management, an ontologically encoded thesaurus matures a controlled vocabulary, metadata standard, and taxonomy to support entity resolution at scale while enforcing the logical reasoning embedded within ontologies.

In this example, you will see BT, which means the broader term, SYN, which is a synonym, and NT as the narrower term. A thesaurus architected with ontologies and machine-readable encoding structure supports interoperability and is quite useful for helping machines and humans understand context and meaning. With context and meaning, a thesaurus marks the establishment of semantic reasoning and primitive knowledge management, now prepared for the next step in the Ontology Pipeline.
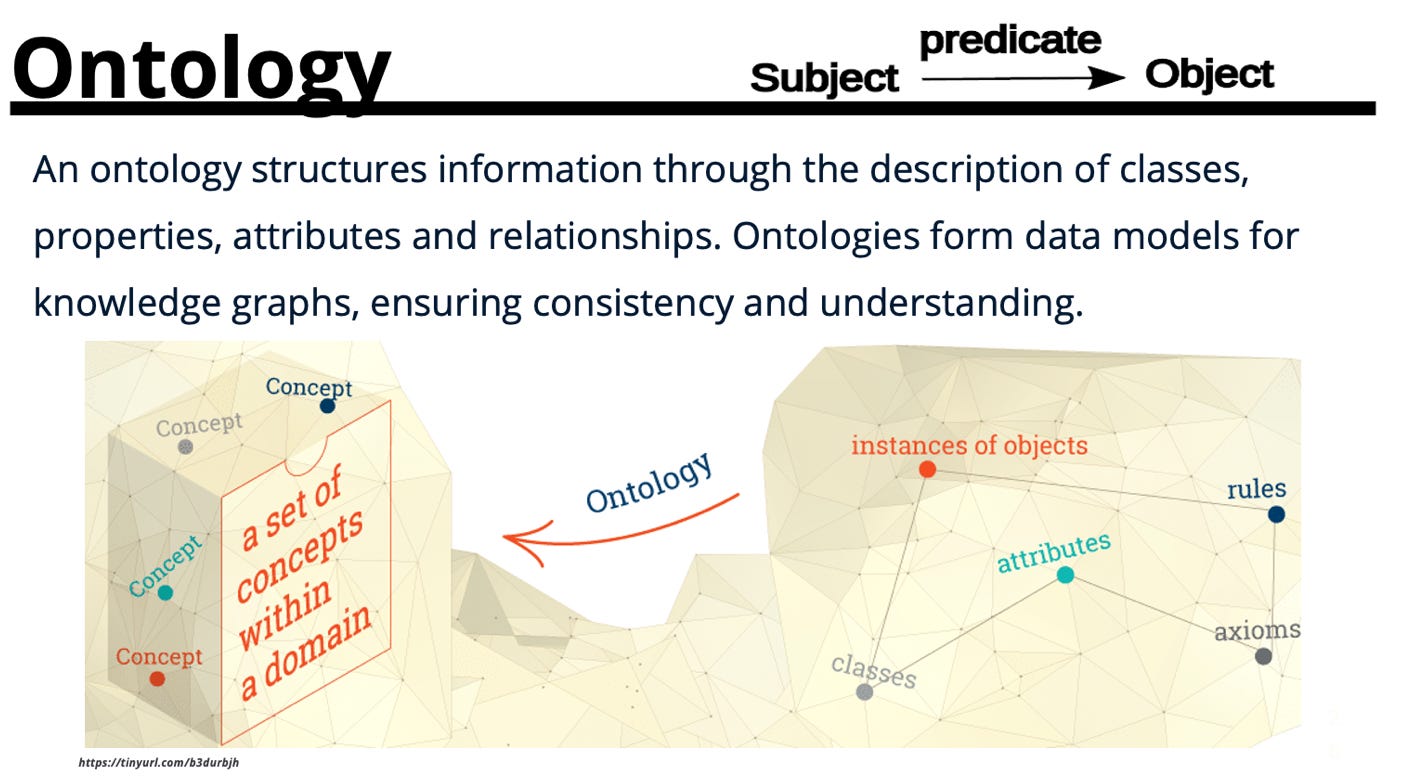
Ontology
Having followed the logical steps and by completing the specific stages of the Ontology Pipeline, data and information are now primed for the ontology build. Since we now have a basic ontological structure to describe vocabulary control, the taxonomy hierarchy, and the thesaurus, we can add domain ontologies and standard, open ontologies to further expose direct and indirect relations, nuanced context, and descriptive context.
Ontologies work to add context and meaning to vocabularies by describing relationships between concepts and with the introduction of logical reasoning. By assigning classes, properties, relations, and attributes, ontologies establish rule bases that define how concepts can behave in the wild to maintain a level of coherence within complex information systems.
Machines LOVE ontologies because of high-fidelity disambiguation and description, bringing clarity to machine understanding for tasks such as information retrieval, entity management, concept discovery, and RAG implementations for AI systems.
If built without established controlled vocabularies, metadata standards, taxonomies, and thesauri, ontology construction can be very difficult as the underlying data and information structures lack integrity and may suffer from data quality issues.
It is nearly impossible to build an ontology with messy, undefined vocabularies because it is difficult to introduce logic when the underlying data itself is not logically structured. Building ontologies is like writing a story that defines domains, complex systems, and relationships between all the characters, places, things, and concepts.
📝 Related Reads
Lost in Translation: Data without Context is a Body Without a Brain
Knowledge Graph
And finally, we have arrived at knowledge graphs, the current Rosetta Stone of a semantic knowledge management system, and the Ontology Pipeline visualization layer. The last step in the Ontology Pipeline involves the synthesis of the four building blocks to culminate as a knowledge graph, which is simply a knowledge management tool.
Because knowledge graphs are an assemblage of controlled vocabularies, metadata schemas, taxonomies, thesauri, and ontologies. The Ontology Pipeline naturally presents a layered knowledge graph, making it easier to troubleshoot broken logic while providing control planes necessary to scale and extend a knowledge graph.
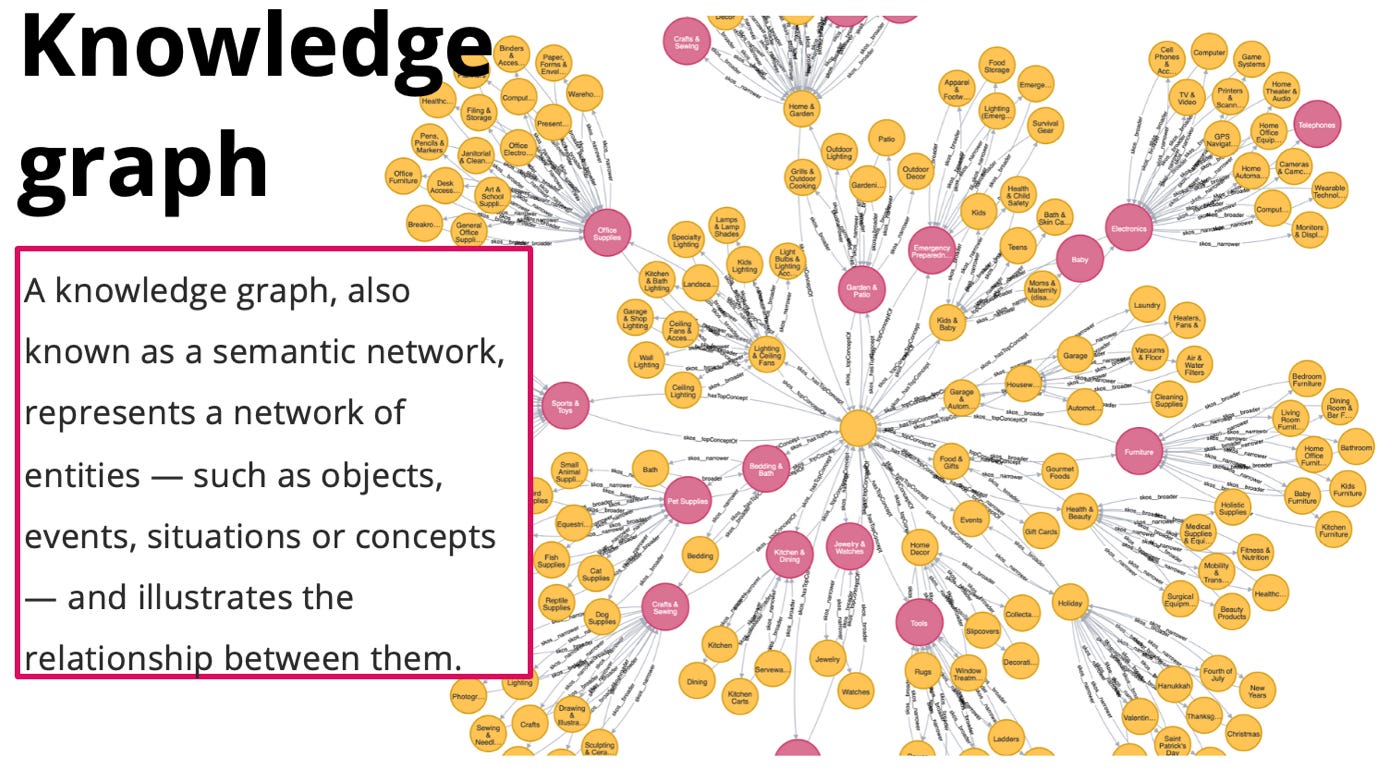
Knowledge graphs represent the synthesis of all stages of the knowledge modelling process, which can now be visualized with pretty, graphical pictures. And because knowledge management is seemingly complex, the visualization becomes an organizational language and communication interface, primed for opportunities to teach and learn across a domain and organization.
Knowledge graphs allow stakeholders, users, and contributors to interact and query a semantic knowledge management system, demystifying the value proposition of semantics and surfacing knowledge as a first-class citizen. Knowledge graphs use the query languages SPARQL and SHACL, providing ways to query the whole graph and discover data and information with a high level of precision.
The only dependencies are the logical reasoning rules introduced by the encoded system. In other words, a knowledge graph is very flexible and only limited by the complexity of the rules and data encoded within.
📝 Related Reads
Back to Basics of Knowledge Management
The Ontology Pipeline as a Framework For Semantic Knowledge Management Systems
After building a semantic knowledge management system by following the logical steps outlined by the Ontology Pipeline framework, time, effort, and cost estimates can be documented to solidify funding and organizational support for further iterations and maintenance. Because organizations struggle to justify investment in semantic knowledge management systems, a proven and repeatable framework enables organizations to project costs and develop metrics to prove value.
When setting up a semantic system, it is important to note the ancillary and integrated benefits of a semantic build by following the logical steps of the Ontology Pipeline, rigorous, iterative process for cleaning, preparing, reconciling, modeling, testing, enriching, enforcing, reporting and measuring data are naturally incorporated. And because LLMs need clean, well-structured, semantically enriched data to provide accurate and reliable results, who better care for data quality than semantic engineers?
📝 Related Reads
Does your LLMs speak the Truth: Ensure Optimal Reliability of LLMs with the Semantic Layer
Final Thoughts
By following the Ontology Pipeline, organizations can:
- Establish a structured, scalable approach to semantic knowledge management.
- Justify investments with well-defined ROI metrics.
- Improve data quality and governance, essential for AI success.
As AI continues to advance, the demand for structured, semantically enriched data will only grow. The Ontology Pipeline offers a repeatable, proven framework to ensure organizations build the necessary foundation for reliable, high-performing AI systems.
Special Announcement From Jessica 🧡
This article will be featured in Jessica’s upcoming book, Intentional Arrangement, set to be published in early 2026. Follow her on LinkedIn for updates and the official launch!
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 🖋️

From The MD101 Team 🧡
Bonus for Sticking with Us to the End!
The quarterly edition of The State of Data Products captures the evolving state of data products in the industry. The latest release—a 2024 roundup, received a great response from the community and sparked some thoughtful conversations.
We’re coming soon with Q1-2025 Edition which captures the state of Data Products in this first quarter. To really get the essence of how the Data Product landscape is shifting, feel free to study the last release before the next one drops!












