




TABLE OF CONTENT
We’ve had one amazing observation, especially during the last couple of years. In every conference, leadership community discussion, or core data event we’ve been to, Governance has surfaced every time. Unmistakably. Usually NOT as a theme of the said event, which usually runs on trend cycles.
Instead, Governance always took the spotlight when leaders and practitioners among the attendees started asking questions around their challenges or demonstrated their pain points to seek plausible solutions.
Governance has become increasingly important for data leaders, given how data teams have outgrown the small back office and developed into massive human networks interoperating between analysts, engineers, client-side data personnel, domains, CXOs, and so many more entities.
We are strong believers and doers of the product way of engineering data. And when we started putting the pieces together in 2018 (over six years ago), it weaved into a solid solution for not just data-for-business but also for the real hard stuff: underlying ops such as manageable governance, plumbing, and cost-optimised golden paths.
Here’s our approach to Data Governance, inclusive of recommendations, optimised states, and more. The Product way through and through.
What do we consider as Governance for Data?
Governance is a broad topic, and we’ve observed that different organisations and experts define it differently. To each his own, but as an enterprise platform team, we are required to empathise with a broader and more end-to-end landscape.
For us, Governance is, therefore, an Umbrella term. Many small facets need to interact with each other and come together for any data citizen to say, “Yes, I can trust this data”.
To be governed means to oversee or preside over healthy bodily functions of the data stack.
This would include some obvious elements, such as Security and Access management. Which are often categorised as “Governance”. But more interestingly, each of these broad verticals is constituted of multiple elements which, more often than not, get excluded from Governance conversations:
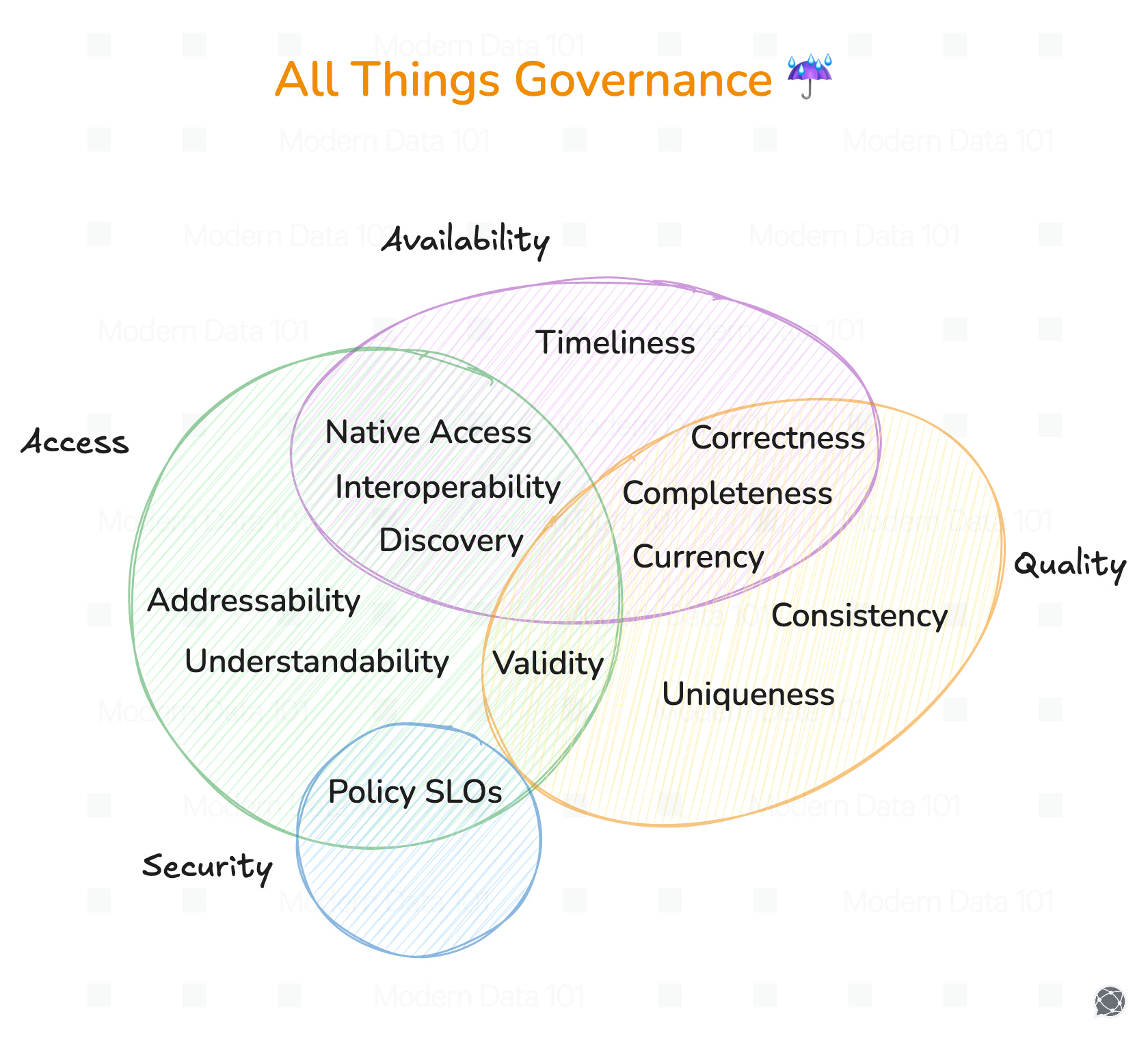
Access & Availability
Access, interestingly, is not just about security or user tag management. If a delivery agent cannot figure out a poorly addressed location, they’ll never be able to access or find your house.
Ensuring Access as one of the pillars of Data Governance, therefore, includes ensuring all of the below counterparts:
- Discovery: Are my data citizens able to find or navigate to what they need?
- Addressability: Discovering is not enough for usability. You’re technically barred from access unless you can use the data. Are my data citizens able to easily address assets to use them?
- Understandability: Same as above. Without understanding the data, you cannot use (access) it.
- Natively Accessible: Are my data citizens able to leverage the data through the means available to them?
- Interoperable: Are my data citizens able to access data assets across the integrated data ecosystem?
Access & Security
- Policy-based access: Do the right data citizens have the right access and the right constraints?
- Security compliances: Is the data stack secure from unsolicited access to potential threats?
Quality & Availability
- Correctness: Is the data accurate enough for use?
- Completeness: Are all the required data points available?
- Currency: Is the data up-to-date?
- Timeliness: Is the data timely available for use?
- Consistency: Is the data uniformly recorded and used across touchpoints?
- Uniqueness: Is the data existing as duplicates or has overlaps?
- Validity: Is the data available as per business-friendly formats or requirements?
To Govern or Not to Govern Data?
The trick to governing data is not to govern data. Yes. You heard that right. Let’s disassemble the crazy to make sense of things.
Every data source has its own governance (access policies and other SLOs). Governance largely becomes a problem when there’s a need to unify governance by resolving conflicts on the same data (when data is brought under the same buckets for processing or delivery requirements).
When the source data falls into a common bucket for processing, it becomes the responsibility of both data developers and governance stewards to ensure the right access and conditional quality post-transformation. This, of course, means conflicting SLOs.
Each domain often ends up having its own priorities and requirements on similar data. For example, Sales may need Marketing’s Leads data updated on a daily basis, whereas marketing has set up monthly frequencies for updates.
Marketing may not be willing to set granularity to “daily” from “monthly”, given it incurs higher costs on marketing’s end (for a sales strategy). This conflict resolution has to be meted at a business level where strategic roles are required to iterate = longer resolution cycles, and built-up frustration points.
Now, consider if both the domains had different consumption end-points over the same qualified data and if the cost of demanded SLOs could be charged directly to the demanding party.
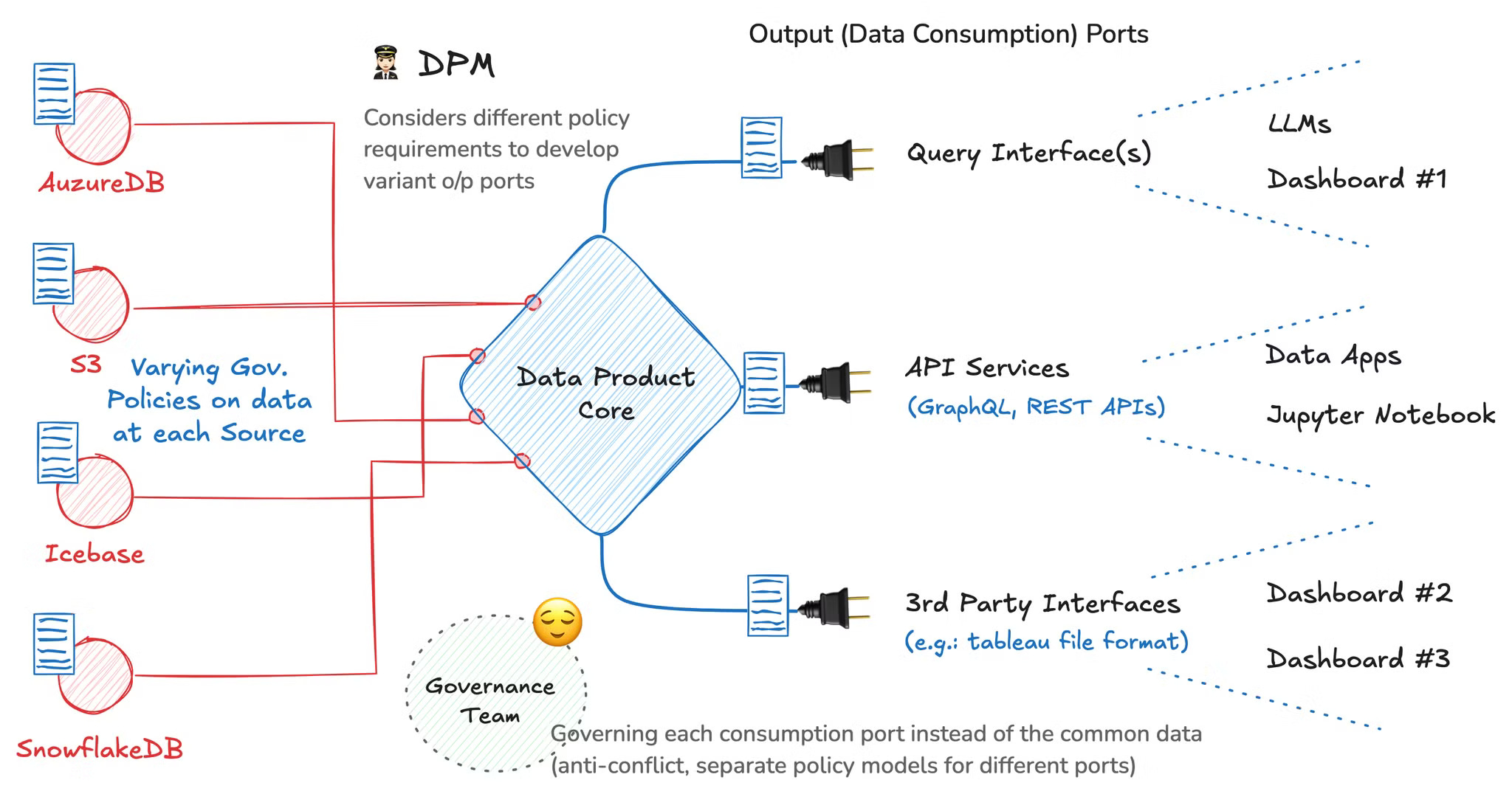
Strategy: Do not govern data; Govern data delivery at consumption ports.
Here’s summarising why this approach has worked in data product stacks:
Conflict Resolution
When conflicts arise (e.g., data access or quality issues), resolving them closer to the point of consumption ensures faster mitigation without impacting upstream data sources. This localised approach allows for the balancing of different stakeholder needs, maintaining flexibility while minimising delays caused by overarching, centralized policies.
Distributed Policy Execution from a Central Policy Decision Point
A central policy decision point creates a unified set of governance rules, but those rules are enforced at various consumption points based on the specific needs of the data consumer. This structure ensures consistency in policy application while allowing for context-specific adjustments, end-to-end visibility, and the optimisation of data governance to meet both local and global requirements.
📝 Related Reads
More about Policy decision and execution points: Role of Interoperability in End-to-End Data Governance | Issue #43
This is why, in a data developer platform, the governance engine is placed at a central point for policy-based and purpose-driven access control of various touchpoints in cloud-native environments, with precedence to local ownership.
Flexibility
Port governance allows for faster adaptation to changing business needs, as data consumers can access what they need without being constrained by rigid governance policies applied across all data sources.
Focus on Value
Governing data at the point of consumption ensures that resources are directed towards delivering high-quality data where it has the most business impact, optimising the user experience and decision-making. Target-driven processing also helps massively with governance-related FinOps, as we saw in the sales-marketing example above.
Efficiency
Reduces the overhead of managing governance policies across vast amounts of raw data, instead focusing efforts on ensuring that only relevant, curated data reaches its intended audience with the required quality and compliance.
Improved Data Consumption
By tailoring governance to consumption points, organizations enhance data usability, making it more aligned with business goals, analytical needs, and regulatory compliance at the time of use.
To Govern or Not to Govern Metadata?
For a long time, largely, there was consensus on how metadata didn’t need access constraints. Metadata needed to be open for all for basic functions such as data discovery and usage decisions. Access and governance protocols came after - on the data itself.
However, enterprises have realised that, over time, this could have fatal consequences. For example, a bad agent with access to the metadata of a seemingly harmless asset may also know it’s in the same region as a more confidential asset. The agent can ask permission to access the path of the harmless file and, in doing so, might inherit access to intermediate paths or easier access to the confidential elements.
This puts assets such as HR employee data, sales customer data, and finance data at risk.
Therefore, metadata governance is critical alongside data governance. However, metadata governance needs to be conducted differently from data governance.
Metadata acts as an access interface: Enabling users to determine if they need access to a data asset and to what degree.
Strategy: Keep metadata as open as feasible and restrict wherever necessary.
AI-Agent to Make Governance More Operable.
Before we dive in, here are some important notes:
- Do NOT Delegate Strategy to AI
- Do NOT allow AI any access to modify (for example, for adaptive data governance where AI agents modify access controls or data quality checks in real-time)
- ONLY use AI for governance as a suggestive accessory
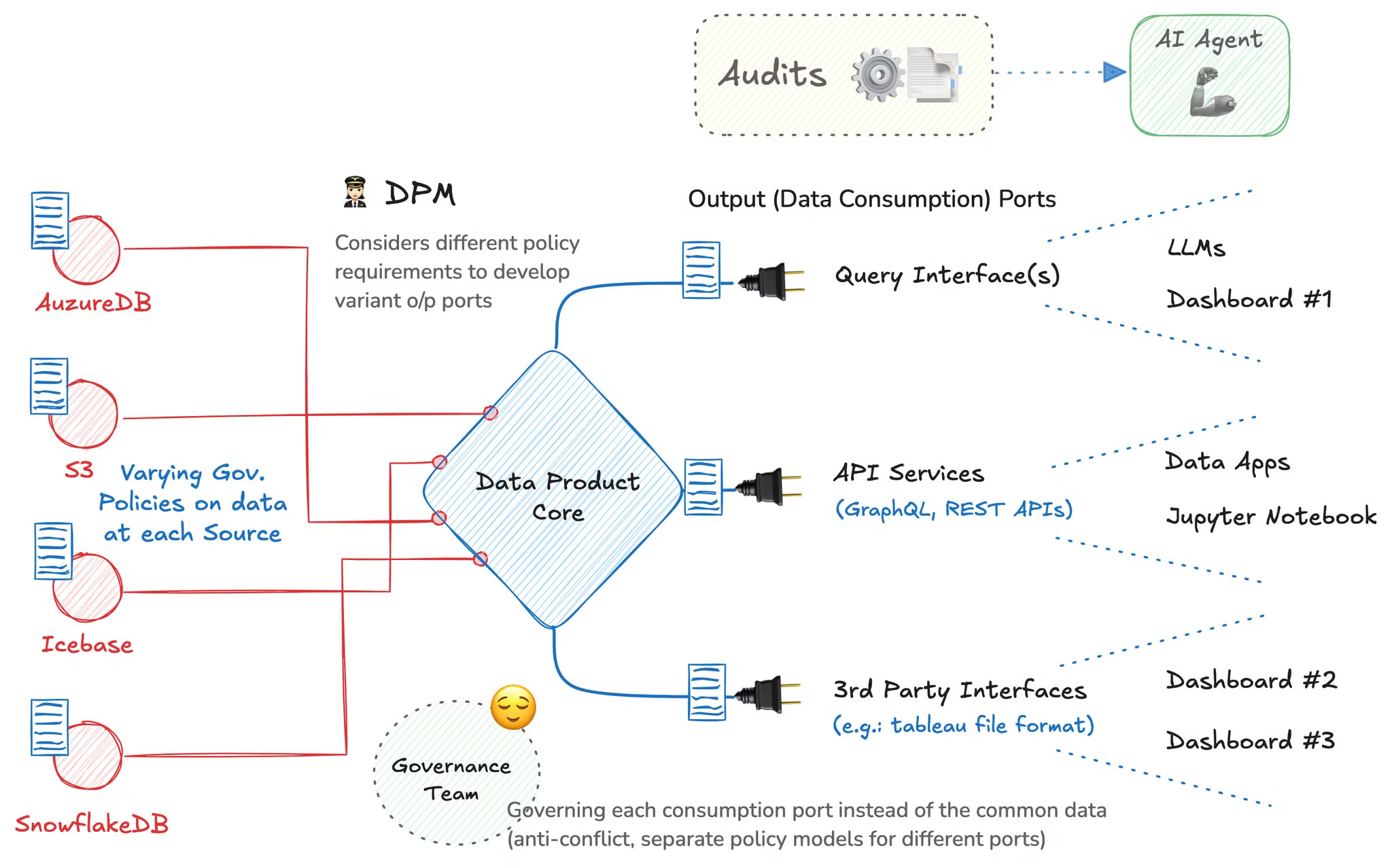
While different policy models are applied at data consumption ports, the audits are recorded centrally and fed to an AI agent that enables the following to ease governance monitoring and management.
Automated Compliance Monitoring
AI agents analyse governance audits to ensure data usage at consumption points adheres to organizational policies and regulatory requirements (e.g., GDPR, HIPAA). By continuously scanning audit logs, AI detects violations or deviations from standards and alerts data stewards or automatically applies corrective actions.
Anomaly Detection
AI agents use audit logs to detect anomalies in data access patterns, flagging unusual activities such as unauthorised access attempts, data exfiltration, or inconsistent usage behaviours. This real-time detection enhances data security and helps prevent potential data breaches.
Optimizing Data Delivery or Usage Patterns for Data Products
By analysing consumption patterns from audits, AI agents predict which data sets are most frequently accessed and optimise data pipelines for better performance. They discover patterns in how different stakeholders use data products. This helps allocate resources more efficiently, reduce latency, and improve data delivery to end users.
Root Cause Analysis for Governance Issues
AI agents can correlate governance audit data with other system logs to perform root cause analysis on governance issues, such as data integrity problems or recurring compliance violations.
Automated Reporting
AI agents generate regular reports on data governance status and key metrics like compliance, access requests, and data quality incidents. These reports help governance teams and executives stay informed without needing to review logs manually.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
MD101 Support 📞
If you have any queries about the piece, feel free to connect with any of the authors (details in Author Connect below). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 🖋️

Connect with me on LinkedIn 🙌🏻

Find me on LinkedIn 🤜🏻🤛🏻







