



TABLE OF CONTENT
Data cut off from its meaning is like speaking your own language in a foreign land: you can talk, but no one understands you - or worse, they might misunderstand you. The disconnect leads to precision without purpose, generating information that looks accurate but offers no real insight. In the end, it's just noise, trapped with no clear meaning to guide decision-making.
Shape and Meaning
When we interact with information, two fundamental forces are always at play.
One is the shape - the physical structure, the way data is stored and organized. The other is the meaning - the functional layer, the part that actually makes sense of that structure.
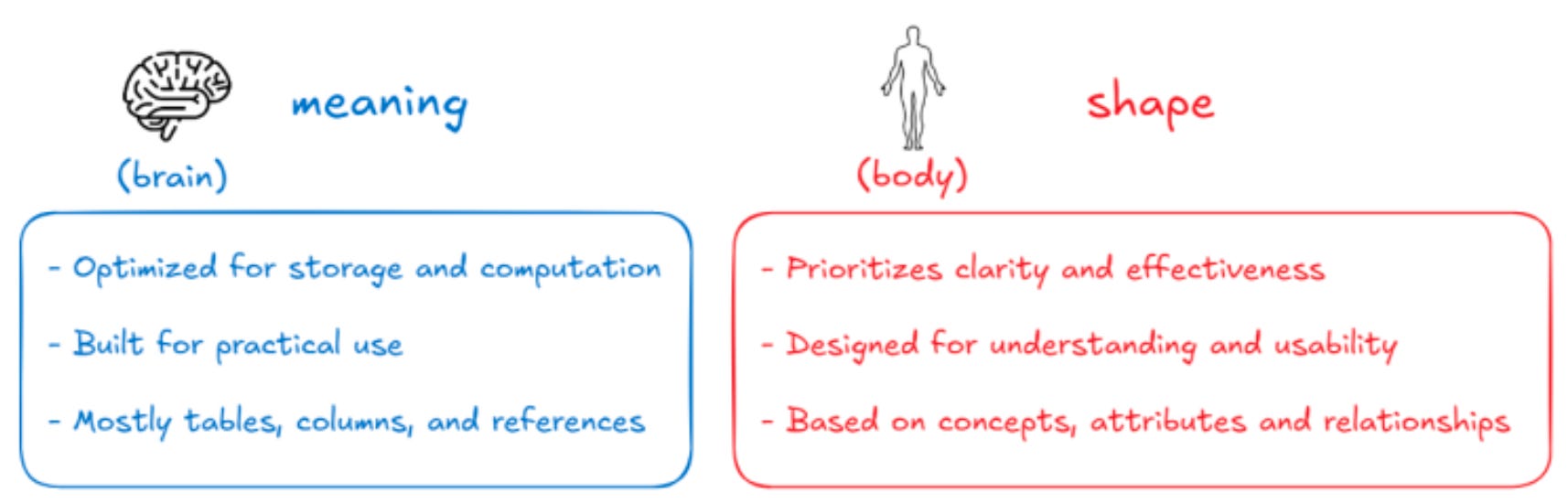
The problem? These two often live separate lives. Shape is locked away in databases. Meaning is scattered across documentation, tribal knowledge, or buried in someone's head. More advanced setups exist, but the reality is that, in general, most organizations keep them apart.
And that’s where things get painful. When shape and meaning aren’t connected, extracting value from data becomes slow, expensive and frustrating. If you've ever stared at a dataset trying to decode cryptic column names or make sense of an undocumented schema, you know exactly what I mean.
The challenge isn’t just about storing data efficiently or making it readable - it’s about bridging these two worlds without forcing them into a rigid system that limits one at the expense of the other.
The goal is a setup where shape and meaning stay connected but flexible. Because data without structure is chaos and structure without meaning is useless. Two things are worth serious thought:
1. Shape is Not Meaning
A database doesn’t “understand” the data it holds. It organizes, stores, and retrieves it efficiently - but has no clue what any of it actually represents. A perfectly structured table can still be meaningless without context. It's fine for each to serve its purpose.
2. Meaning Often Takes a Backseat
We prioritize storage, performance, and structure - until meaning becomes urgent. Then, right when decisions depend on clarity, we scramble. We dig through documentation (if it exists), track down the person who “might know,” or worse, just guess. By the time we realize meaning was undervalued, we’re already in trouble.
We need to focus intentionally and proactively on meaning.
The Connection
𝐒𝐞𝐦𝐚𝐧𝐭𝐢𝐜 𝐥𝐢𝐧𝐤𝐢𝐧𝐠 is what connects one world to the other as the nervous system does by managing the communication between the brain and the body.
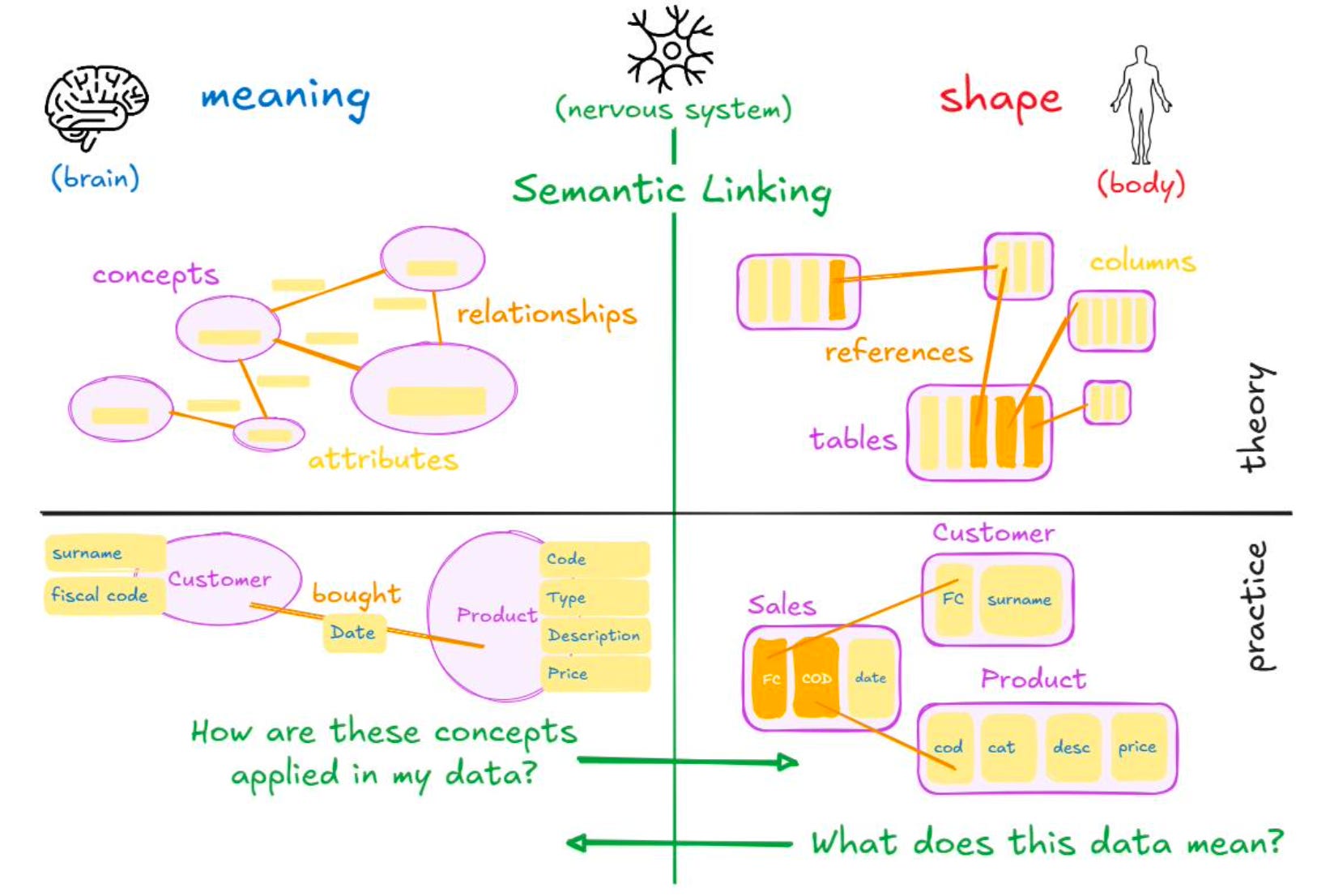
It bridges the gap, connecting the physical form of data to its real-world meaning and answers two critical questions:
- For those with the data: 𝐖𝐡𝐚𝐭 𝐝𝐨𝐞𝐬 𝐭𝐡𝐢𝐬 𝐝𝐚𝐭𝐚 𝐦𝐞𝐚𝐧?
- For those with the semantics: 𝐇𝐨𝐰 𝐚𝐫𝐞 𝐭𝐡𝐞𝐬𝐞 𝐜𝐨𝐧𝐜𝐞𝐩𝐭𝐬 𝐚𝐩𝐩𝐥𝐢𝐞𝐝 𝐢𝐧 𝐦𝐲 𝐝𝐚𝐭𝐚?
Without this connection, we risk working with beautifully designed nonsense.
📝 Related Reads
Semantics and Data Product Enablement - A Practitioner's Secret | Frances O'Rafferty
How to Put it in Practice Within a Data Contract
Let’s step into a scenario where we want to implement semantic linking using an approach based on data product.
Some questions immediately come up:
- Where does semantic linking actually live in a data product?
- How do we make it work without turning data engineering into a philosophical debate?
The answer lies in metadata. Embedding semantic linking within a data product’s metadata ensures that data isn’t just stored - it’s immediately interpretable by both machines and humans. Context is always accessible, right where and when it’s needed.
This isn’t just about making data easier to use. It’s about eliminating the endless back-and-forth of “What does this column mean?” and “Where can I find the definition of this entity?”. It means building data products that are self-describing and connected to knowledge, reducing friction and unlocking value faster.
A data product is defined by a descriptor that formally represents all its components. Among them, interfaces are crucial for external data exchange, and that’s where semantic linking happens. Alongside all the other elements, each interface includes:
- The 𝐩𝐡𝐲𝐬𝐢𝐜𝐚𝐥 𝐞𝐱𝐩𝐫𝐞𝐬𝐬𝐢𝐨𝐧, enabling direct use via APIs or automation
- The 𝐦𝐞𝐚𝐧𝐢𝐧𝐠, by referencing ontologies and mapping the physical schema to their elements
While we are talking about ontologies the same could be done by referencing a business glossary. The benefits would be similar but with fewer opportunities for automated tools to "navigate" the semantic elements. In fact, a business glossary is usually just a collection of terms and definitions without the broader set of information given from connections in an ontology.
We could also use natural language to express semantics without bothering ontologies, and a language model could then analyze the definition to provide an interpretation. But we don’t want AN interpretation, we want THE interpretation, the correct one, i.e. relatively to the product team: what they had in mind when building it, in reference to the specific knowledge of their domain, not the neutral and generic interpretation of a language model.
One effective way to implement this is through 𝘋𝘗𝘋𝘚 (𝘋𝘢𝘵𝘢 𝘗𝘳𝘰𝘥𝘶𝘤𝘵 𝘋𝘦𝘴𝘤𝘳𝘪𝘱𝘵𝘰𝘳 𝘚𝘱𝘦𝘤𝘪𝘧𝘪𝘤𝘢𝘵𝘪𝘰𝘯), a formal way to describe clearly all components of a data product.
When designing the data contract, you define the semantic linking at a high level, referencing broad concepts or with more detail by looking at specific attributes. This is done by establishing a binding between each element of the data product's schema and its corresponding element in the ontology. The binding can reference multiple ontologies and is organized through namespaces, ensuring a clear, structured connection between data and its meaning.

This ensures data consumers get both 𝐬𝐡𝐚𝐩𝐞 (physical schema) and 𝐦𝐞𝐚𝐧𝐢𝐧𝐠 (semantic model) upfront without playing detective and activating metadata, allowing them to navigate across different contexts seamlessly through platform services.
📝 Related Reads
Role of Contracts in a Unified Data Infrastructure | Issue #11
Integration with Data Governance Suite
The Data Product approach isn’t just another way to organize data—it’s a foundation for sustainable, long-term data management. It shifts the focus from isolated datasets to well-defined, self-contained products that are easier to understand, use, and maintain.
At the heart of every Data Product are Data Contracts. These define everything necessary for both interpretation and consumption, acting as a shared agreement between producers and consumers. They clarify structure, expectations and meaning.
This is where Semantic Linking comes in. It bridges the gap between the raw, physical data and its actual business meaning, ensuring that data isn’t just technically accessible but also intellectually usable.
But how does this work in practice?
- Where does it fit within a Data Governance suite?
- How should users interact with the Data Catalog, Business Glossary, and Ontology in a way that feels natural and efficient?
A practical solution must do two things seamlessly:
- Ensure that the physical data schema is fully accessible within the Data Catalog
- Guarantee that what experts define in the enterprise ontology is exactly what Data Contracts reference and use
Without this alignment, governance becomes just another bureaucratic layer instead of a real enabler for clarity and trust in data.
This is where the XOps platform comes in. Sitting between data products and infrastructure, it streamlines asset lifecycle management and automates communication with underlying systems. Think of it as a developer’s ally, reducing complexity through dedicated services so teams can focus on building rather than managing operational overhead.
While the XOps platform serves many purposes, one key role is ensuring seamless consistency between Data Contracts and the Data Governance suite - a critical step in making governance practical, not just theoretical.
The XOps platform connects with various underlying technologies through a set of adapters, ensuring that the flow of data between systems remains efficient and transparent for developers. Specifically, two key adapters come into play here:
- One writes the physical schema to the Data Catalog, ensuring it stays aligned with the active Data Contracts. This guarantees consistency and eliminates the risk of outdated or inaccurate references.
- The other retrieves ontology definitions, making them available for Data Products and users who need to understand the underlying concepts and relationships.
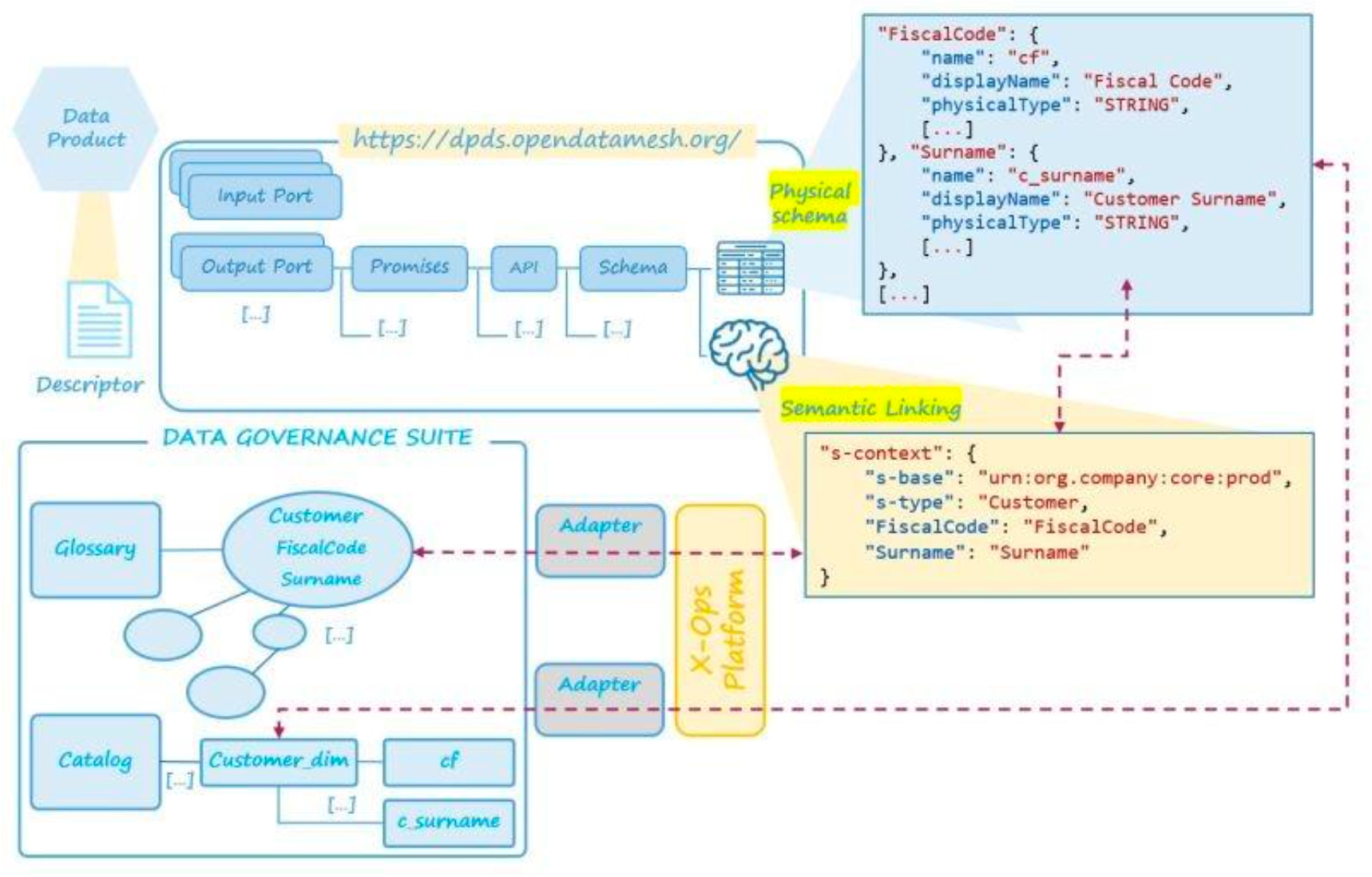
This setup creates a clear, governed structure for managing data:
- The Data Catalog becomes a reliable, read-only reference. Users can explore the data, but any updates are managed exclusively through the XOps platform, ensuring that no inconsistencies creep in.
- Ontology definitions work in reverse. While users enrich them, Data Products consume but never modify them, maintaining a clean separation between governance and operations.
The XOps platform is more than just a layer in the system. It ensures that Data Contracts aren’t merely formal agreements - they become the driving force behind a governed, discoverable and consistent data ecosystem.
📝 Related Reads
Solve Governance Debt with Data Products
Final Thoughts
For all the talk about data-driven decision-making we still spend an absurd amount of time just trying to understand data in the first place.
Why?
Because shape and meaning are treated as separate problems: one for engineers, the other for business users. And when these two worlds don’t talk, we get beautifully structured nonsense.
We prioritize efficiency over clarity, assuming meaning can be patched in later. But by the time we realize context is missing, it’s already a bottleneck. Scrambling through documentation (if it exists), tracking down the one person who "might know" or, worse, making assumptions: this isn’t a strategy; it’s survival.
Data should speak, not whisper.
Semantic linking isn’t just about better documentation, it’s about giving data a voice. When meaning is embedded, decisions aren’t just faster, they’re smarter.
The real question isn’t whether we need it but why we’re still working without it.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 🖋️

Find me on LinkedIn 🤝🏻







