.avif "Brij Mohan Singh")



TABLE OF CONTENT
Today, businesses are mostly drowning in data, but the quest for context and data-driven actionable insights remains a meandering loop with no destination in sight. Despite having access to vast amounts of data and cutting-edge language model technologies, many organizations struggle to make meaningful use of them that transparently and measurably affect the KPIs.
But what’s really holding them back?
Today’s LLMs are very impressive! They can whip up content, translate languages, answer questions, and more.
But here’s the thing—LLMs on their own are adolescents who mostly appear smart but need immediate guidance and much more knowledge before they can jump to conclusions. LLMs are essentially advanced text processors and struggle with basic math and logic. While they’re incredible, they’re not flawless.
Issues like hallucinations, contradictions, and an inability to handle complex logic still linger.


So, while improving LLM accuracy and minimizing hallucinations is important, that's not the crux of the problem.

The Gaps
The real challenge lies in how these LLMs struggle to capture context around cross-functional workflows. They don’t natively connect the dots between data silos and multiple processes, which leaves a huge gap in delivering cross-domain insights—the true essence of business.
There are 2 primary problems that limit the penetration of AI accurately across cross-domain functions and decisions.
Problem 1: Transforming cross-domain questions to accurate queries
LLMs typically struggle with understanding domain-specific semantics (like jargons), correctly mapping user intent to structured data queries, and reconciling inconsistent terminology across domains. The models built on general datasets often fall short when it comes to the precision required for each industry-specific domain.
Moreover, siloed context—for example, where different apps in the domain have their own vector DBs, or where each domain has its own separate knowledge graph, context gets divided and isolated from other domains/apps—developing into branches that don’t understand the data/events beyond its purview.
This creates an echo chamber for the domain—the domain’s self-induced knowledge gap!
Why self-induced? Because of the choice to dissociate context with separate tools and technologies—the output of which cannot converse with each other.
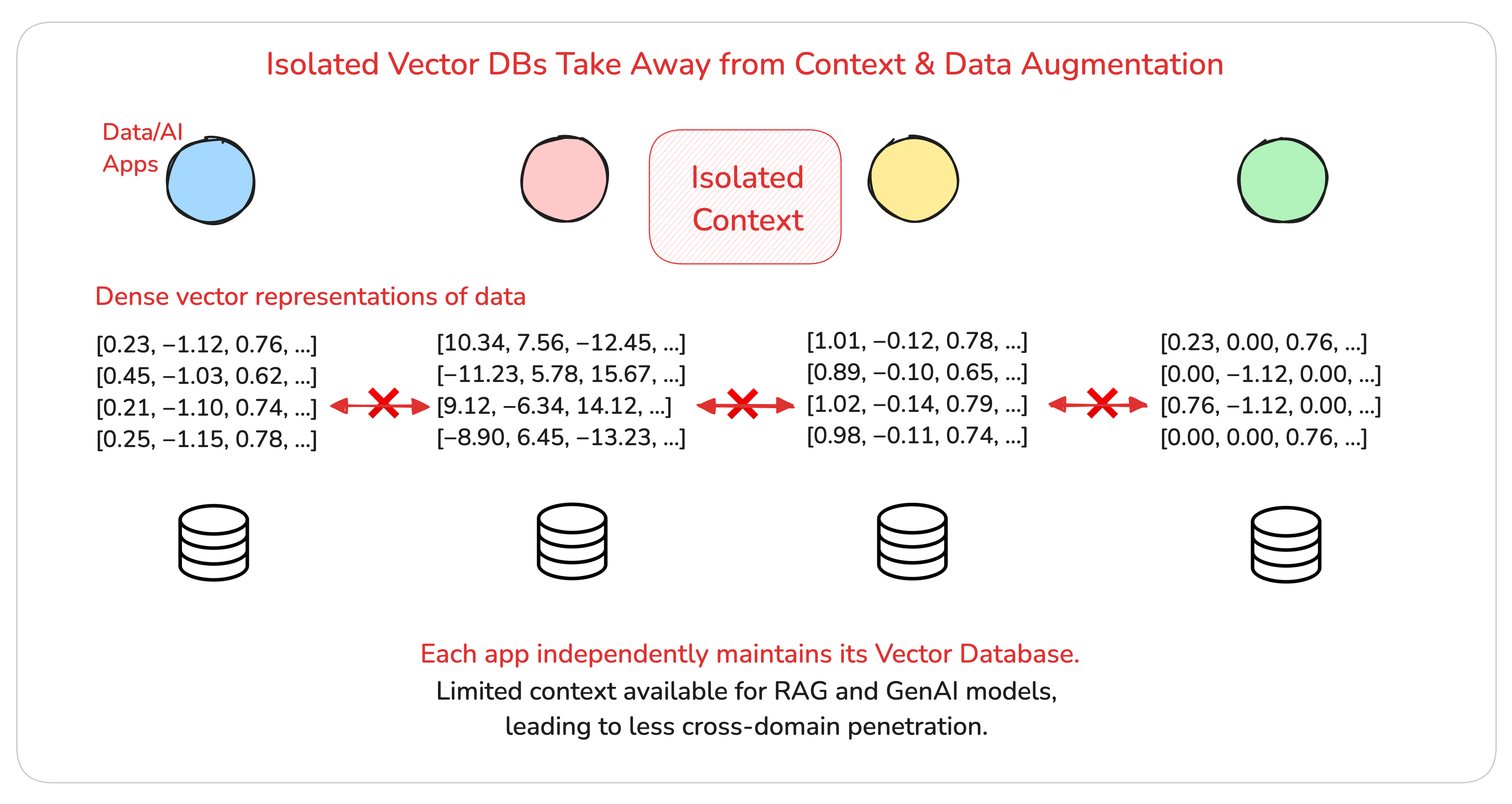
This issue is exacerbated when dealing with heterogeneous data sources or contexts requiring precise retrieval from structured databases, as LLMs are inherently designed to process unstructured text and may lack the necessary contextual grounding for structured inputs.
What organisations need here to bridge the gap between broad capabilities and the deep knowledge needed to perform accurately in these areas.
Problem 2: Executing a series of tasks or a process
While building an application, the development teams and DEs often need the capability to call the models (say, LLMs) during multiple steps in the process.
For instance, you’re creating an adaptive survey. You start by asking a survey group a series of questions, but the responses trigger follow-up questions based on specific answers. For example, if a participant mentions that a product feature was "okay but a bit confusing," you might want to dig deeper: Was it confusing because of terminology? Usability? Expectations?
To make this possible, you'd need a combination of external logic combined with an LLM’s insights at each step.
External Logic + Responsive LLM Tasks = Intuitive SolutionHere, an LLM can help detect the sentiment behind a response—such as identifying frustration or ambivalence—and suggest the next logical question for richer data collection. This adaptive, back-and-forth approach allows for deeper insights, making the survey much more valuable.
But this demands a wider context during each jump- from one task to another. Often interwoven across domain data. For example, to ask intelligent questions, the LLMs across different steps would need context or retrieve information from not just the Product Domain but also Sales & Marketing to truly grasp the intentions, patterns, and response expectations of different survey segments. Moreover, the retrieved data from different domains must be able to understand each other (e.g.: context that ‘target_region’ from marketing data and ‘geo_state’ in a sales asset could refer to the same information).
How do we improve LLM “intelligence” and rake enough dependability to affect big KPIs
Let’s face it: no business operates on simple, one-off tasks. It’s always about navigating complex workflows, juggling numerous deliverables, and aligning processes across different domains with those ultimate goals that push the organisation forward.
The approach is to humanise the entire problem-solving process by breaking down a problem into smaller, manageable parts and assigning specialized agents to tackle each one. This needs decomposing the problem into sub-parts and assigning tailored and specialized agents to solve each of the subproblems.
This is where AI agents have made a sharp entry to turn your LLM into more than just a chatty assistant, connecting it with specialized skills to take on real-world challenges and closing the ‘reasoning and step-wise execution’ gap.
Deploying the multi-agent workflow
When it comes to addressing cross-domain & cross-functional needs, multi-agent AI workflows help break down complex domain-specific tasks to allow individual agents to handle specialized aspects of a problem, creating a highly adaptive and efficient workflow.
In this multi-agent workflow, every agent is an independent actor powered by LLMs and collaborating with other agents. Every agent has its own prompt, a connected LLM and some custom codes to collaborate with the other agents.
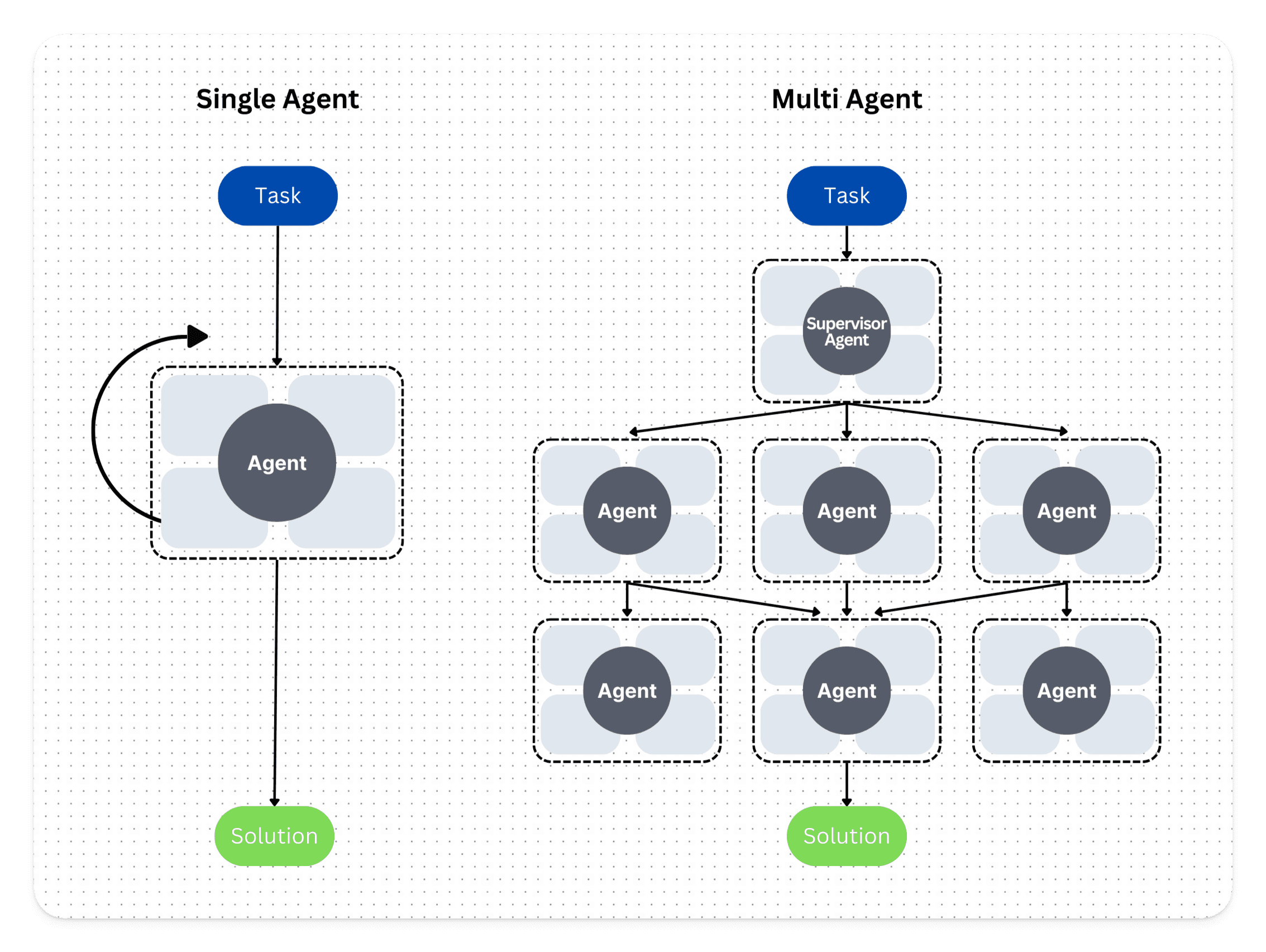
Imagine an adaptive survey where follow-up questions dynamically evolve based on real-time sentiment analysis. In this scenario:
- One agent, powered by an LLM, analyzes survey responses for sentiment and nuances, detecting elements like frustration or satisfaction.
- Another agent, specialized in crafting dynamic queries, generates follow-up questions aligned with the detected sentiment, user profile, and product feature.
- For instance, if frustration about a product feature is identified, the follow-up might delve deeper into the specific pain point that applies to the user profile.
By having specialized agents handle these decision-making steps, businesses ensure workflows that are both robust and flexible, allowing for more personalized and insightful user interactions.
Why is the multi-agent system preferred over the single-agent system?
1. Adding too many tools to a single agent increases the likelihood of failures. Multi-agent systems mitigate this by assigning each agent only the tools needed for its task.
2. Different prompts can be coupled with different agents, and each prompt can have its own instructions powered by separate custom-tailored LLM.
3. Each agent can be independently improved without disrupting the entire system, enabling targeted updates, risk reduction, and easier scaling while maintaining system stability.
Adopting Reinforcement Learning through RAG
Reinforcement learning (RL) is like learning from trial and error! In the multi-agent system, RL algorithms allow agents to adjust their actions based on rewards, such as task accuracy or efficiency improvements.
While orgs try to achieve optimal results through reinforcement learning, leveraging RAG systems in addition to RL makes the system more resilient, intelligent, and context-aware by enabling continuous learning.
The RAG systems comprise two primary components: the retrieval and generation components, where the retrieval phase identifies relevant external data or documents, and the generation phase produces contextually appropriate responses or outputs.
In cross-domain scenarios, RL models often need to handle a variety of contexts. RAG’s retrieval system helps by fetching relevant external knowledge to guide the RL agent's decision-making. This allows RL to apply general strategies to specific situations, benefiting from data that wasn’t initially available in the agent’s training environment.
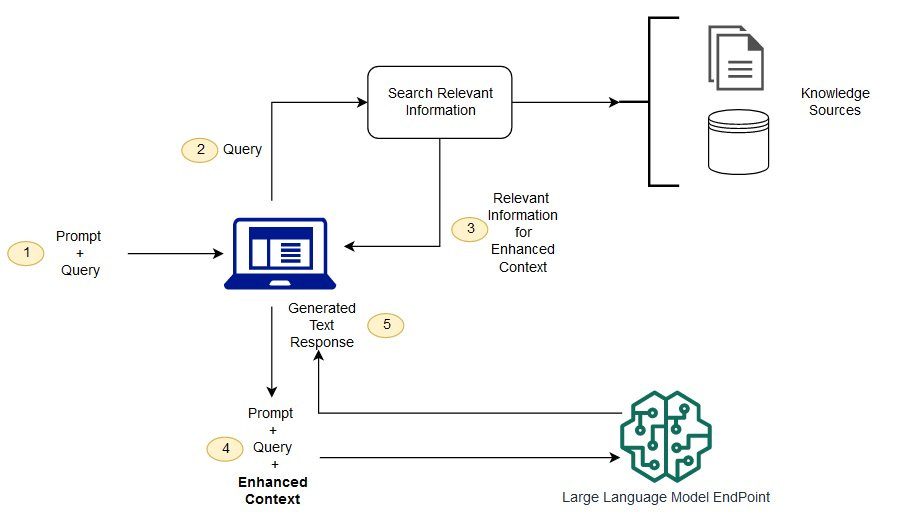
Instead of relying only on internal model predictions, the RL agent can pull in relevant, external data from large document corpora or databases with RAG’s retrieval component. This is especially useful when the agent needs to understand the environment more deeply (such as answering queries or generating text based on real-world facts).
RL spanning across domains often require the agent to adapt to new information in real-time, which can be difficult if the agent only has access to a narrow, domain-specific dataset. RAG allows the agent to access external knowledge relevant to the task at hand.
How Data Products Augment Cross-functional Context to Enable Accurate Multi-Agent Systems
The proposed solution integrates the strength of individual components and their capabilities to integrate with each other in order to address the challenges of multi-functional tasks across multiple domains.
Integrating multiple technology stacks is complex, causing siloed data, misaligned goals, and requiring high maintenance as teams struggle with communication and data consistency.
In one line, Data Products serving contextually enhanced data aligned to a specific agent’s primary tasks/functions.
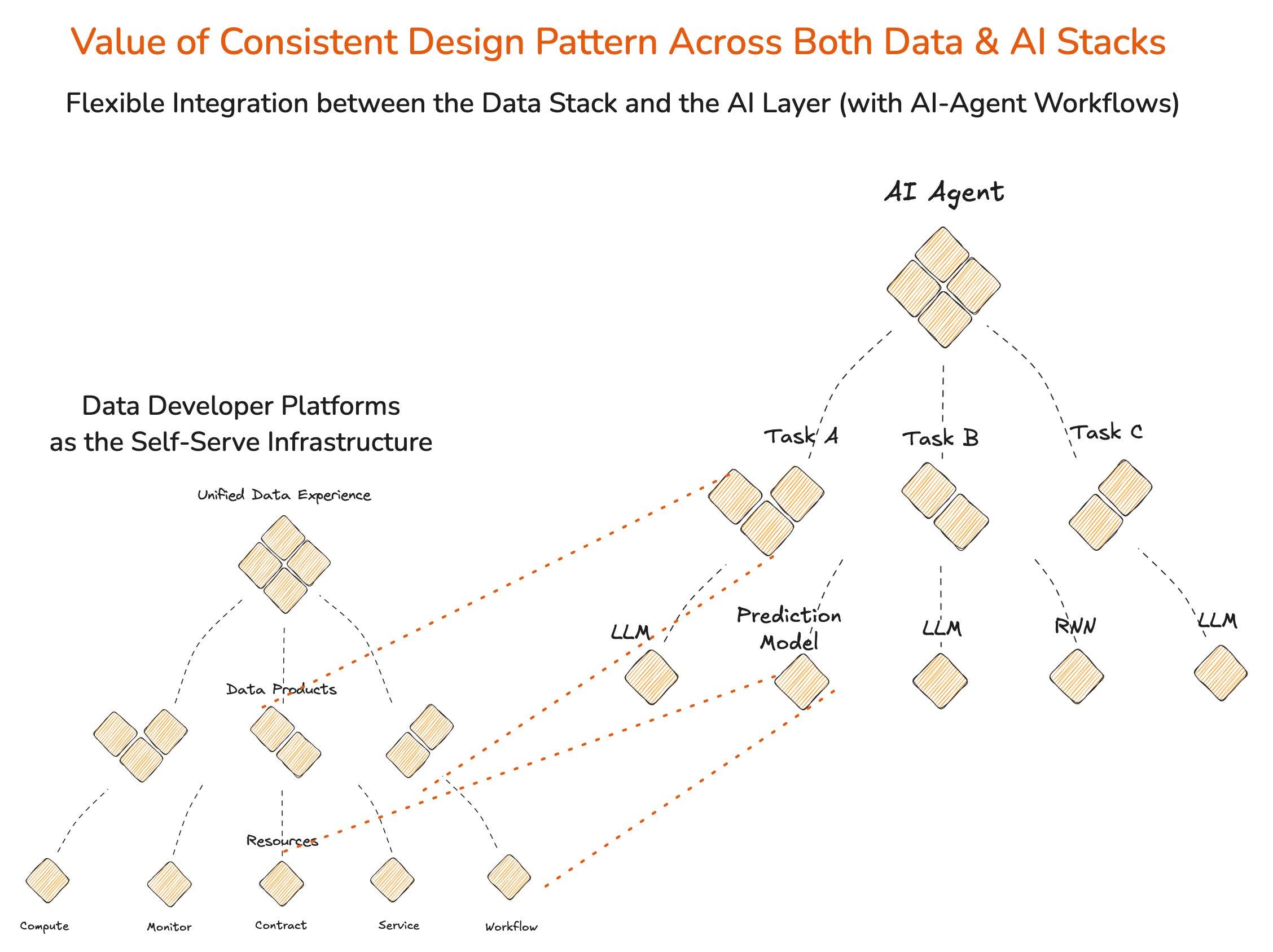
In this part of the article, we’ll try to curate a use case where the data product approach integrates with the multi-agent workflow in support of LLMs to solve the challenges of performing cross-functional operations.
A Real-Business Case: Marketing’s Impact on the Supply Domain
In the typical business setting that takes the marketing and supplier example, let’s assume we want to measure the impact of a marketing campaign on suppliers.
Our focus: Deriving how cross-functional needs across these domains can be met with the data product approach + agentic workflows.
Data Products acting as domain boundaries
The individual data products are bounded sources of domain-specific intelligence, storing data and contextual information that agents can query effectively.
At the core, the data products act as specialised containers representing the discrete and specific domains. So, each data product represents a domain-specific dataset with defined boundaries and intelligence, like a "marketing" data product would mean one of the data products hosted by the marketing domain.
For simplicity, we can assume there’s one data product for each of the domains in this example: a ‘Campaign Compass’ data product for the marketing domain and a ‘Supplier Hub’ data product for the supply domain.
Campaign Compass provides its users with an end-to-end view of different metrics like:
- Impressions, click-through rate, engagement rate, return on Ad spend (metrics) to help identify key regions or demographics where the campaign resonates most.
- Product sales lift by region, conversion rates (metrics) to assess how the campaign drives demand across specific products.
- Sentiment score, brand perception, customer satisfaction rate (metrics) to measure shifts in brand perception.
Supplier Hub has insights into metrics like:
- Order fulfillment rate, stock-out frequency (metrics) to evaluate partner readiness to meet demand from campaign spikes.
- On-time delivery rate, lead time, inventory accuracy (metrics) to evaluate partners who excel in timely and efficient responses to increased demand.
- Lead time to help plan ahead based on supplier response times.
These two data products provide specialised data, metrics, and dimensions, which can be queried to answer questions while analysing or making decisions that evolve campaigns, optimise supply, or troubleshoot.
RAGs orchestrating queries and designating tasks for agents
The RAGs here act as intermediaries for understanding complex, cross-functional questions and identifying the domains to parse the queries into sub-tasks designated for relevant agents or data products.
The retrieval counterpart of RAGs collects query-specific data from across domains, and the generative counterpart generates a new query with additional context, which is then used to deliver context-enhanced and accurate data.
For example, an LLM could supply a high-level question to a RAG model, which retrieves and interprets the various elements (e.g., marketing campaign performance and supplier impact), and direct each agent to query the necessary data products.
There is a defined workflow where step-by-step processes are defined for the agents.
In the established scenario, an LLM interprets complex, multi-faceted queries like:
"How did Campaign X impact Supplier Y's fulfillment rates and delivery times?"
- Interprets the query and identifies that the required data spans two domains: marketing (Campaign Compass) and supply chain (Supplier Hub)
- It breaks down such queries into sub-tasks aligned to each domain like:
- Retrieve campaign performance metrics (engagement, demand).
- Fetch partner-specific supply chain metrics (delivery delays, stockouts).
- Delegates sub-tasks to respective agents:
- The LLM instructs Agent A to verify the query scope and identify relevant dimensions for each domain-specific sub-task.
- Agent B generates targeted queries for each data product
- Agent C ensures the retrieved data is accurate and ready for synthesis
AI Agents deriving domain information from data products
Now, you have deployed a bunch of domain-specific AI agents in the multi-agent system, each agent dedicated to executing a part of the workflow that the AI model assigned to achieve the end goal.
Here, each data product is paired with a custom agent or a set of custom agents trained to query and analyze metrics unique to its domain.
Let’s consider agents A, B & C work with Campaign Compass that interact sequentially with each other to interpret marketing questions, translate them into queries, and validate the resulting data against the campaign objectives.
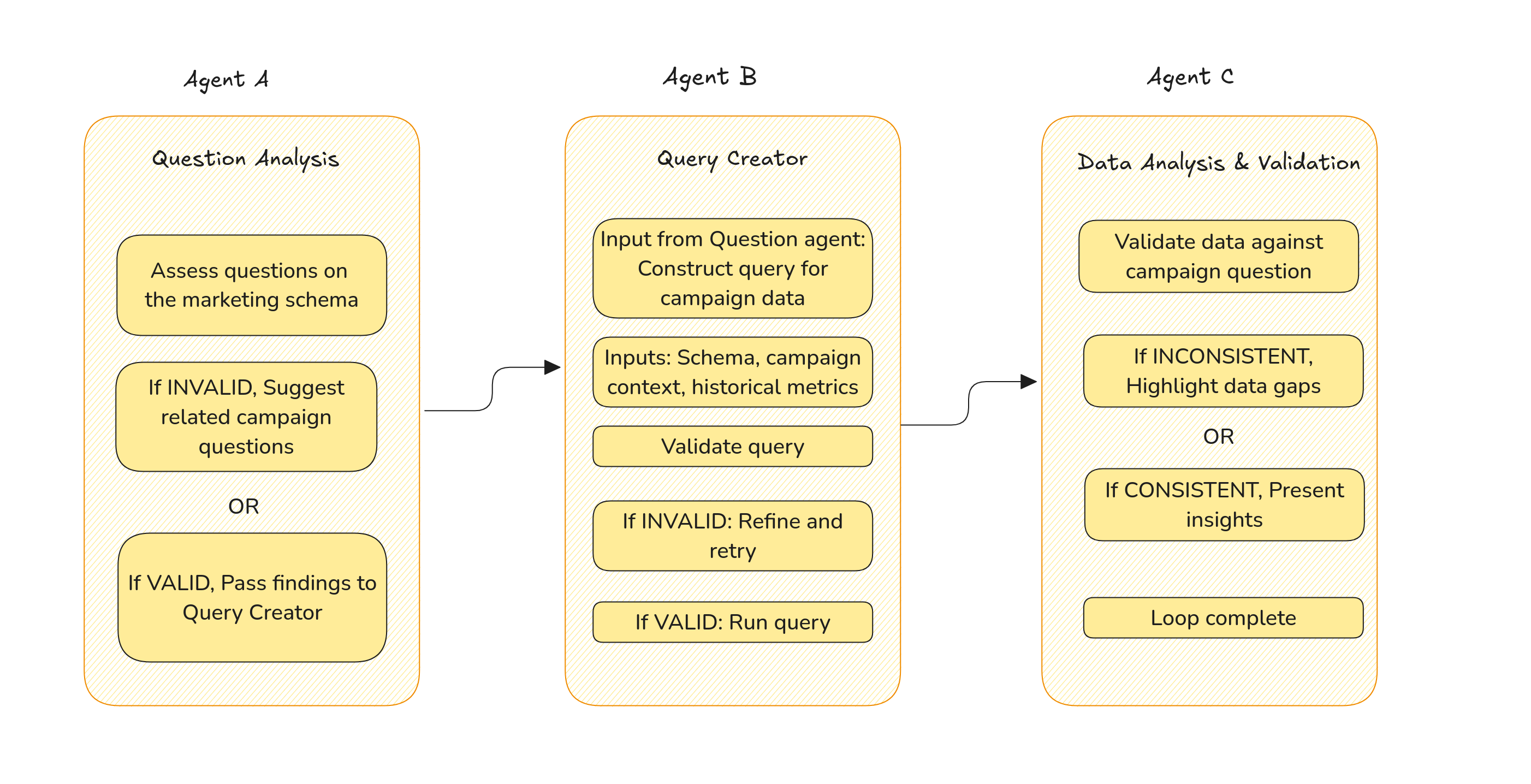
Similarly, agents working in the supplier domain with Supplier Hub collaborate to ensure supply chain insights are accurate and relevant, validating each step from question analysis to final data consistency.
This approach empowers businesses with reliable insights for managing supplier performance effectively.
Mapping AI Agent workflows with Data Object Graphs
A data object graph (DOG) is like a structured map showing how data objects or nodes (e.g., metrics, datasets, insights) connect and influence each other.
Data Expert Recommendation
Jon Cooke has done a spectacular job of advocating the impact of DOGs across his socials. Check out to learn more.
An agent creates a DOG and uses this graph to navigate through complex, multi-step business workflows. Starting with a clear business objective, the agent parsing the DOG breaks it into manageable subtasks, identifying the data objects and processes necessary to achieve the goal.
- The Agent then traces its path through the graph, ensuring that each node contributes meaningfully to the final outcome.
- If it encounters errors or gaps, it can backtrack, adjust the graph, and re-evaluate to improve decision-making accuracy.
- The agent coordinates with other AI agents and LLMs by sharing its Data Object Graph.
LLMs back in Action
Once the agents respond, the LLM integrates their insights, connecting marketing metrics (e.g., audience reach) to supply chain outcomes (e.g., delivery delays).
The LLM relies on structured prompts and templates to ensure consistency in outputs, integrating predefined metrics into readable text based on user queries, all while maintaining relevance and clarity for decision-makers.
Using NLG capabilities to combine outputs from the Question Analysis, Query Creator, and Data Analysis & Validation agents.
Hence, after the agents validate that Supplier Z’s on-time delivery rate dropped by 10% following Campaign X, the LLM might produce a summary like this: “Campaign X boosted demand for Supplier Z’s products by 20%, but fulfilment delays increased by 10%, likely impacting customer satisfaction.”
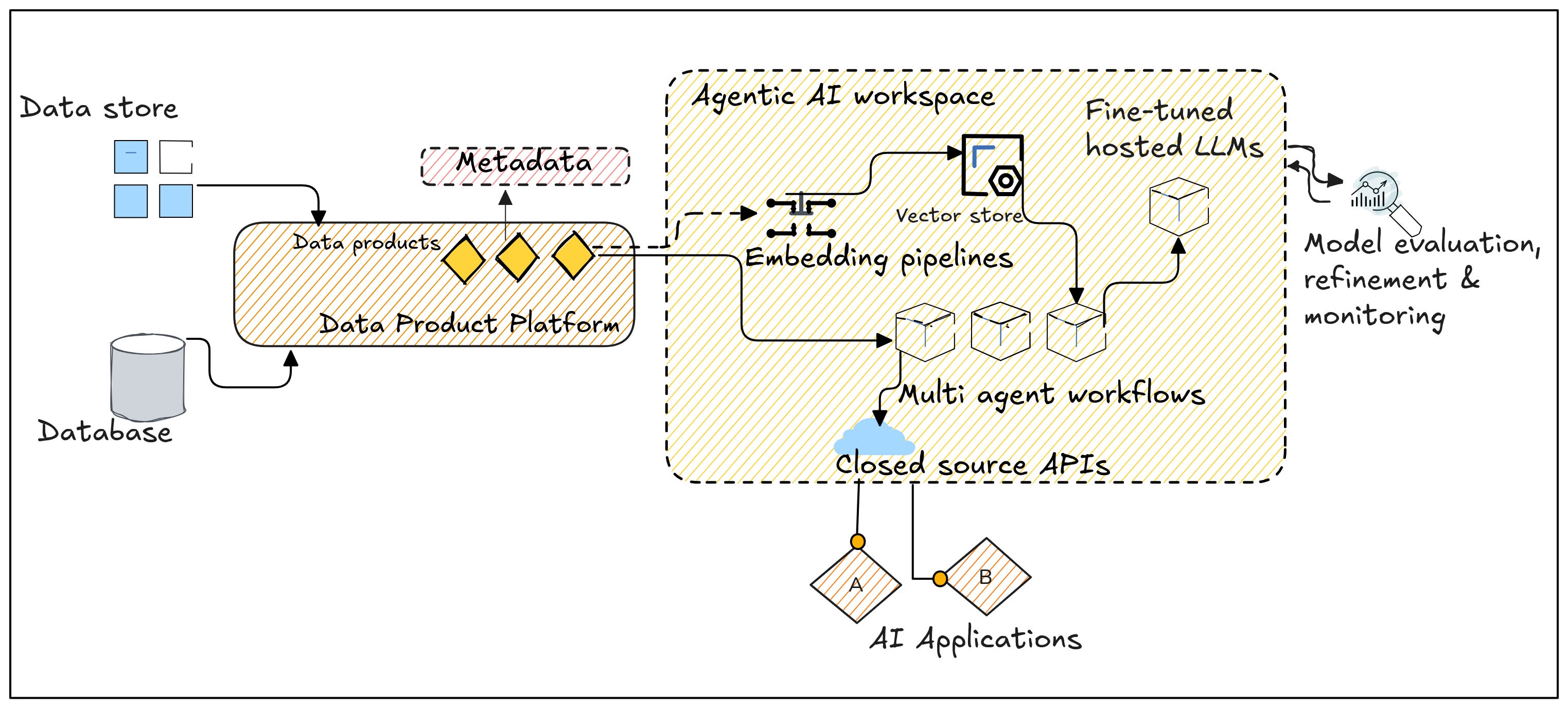
A Unified Data Product Platform provides semantic understanding for enhanced accuracy
The semantic layer standardizes how data products define terms like "campaign success" or "partner performance," ensuring agents and LLMs interpret data consistently. A centralised repo of knowledge embedded within the unified platform ensures context sharing and closes the gaps between siloes vectors.
Utilising the semantic layer of the data product platform also allows users to create knowledge graphs to link entities (e.g., campaigns, partners, demographics) across domains, enabling nuanced cross-domain queries.
For instance:
- Linking Campaign X to Region A and its associated Partners.
- Mapping partner-specific metrics like delivery accuracy to customer satisfaction scores derived from marketing data.
The LLM adds context by relating marketing data (like campaign engagement) to supply chain metrics (like delivery performance), offering stakeholders a clear picture of cause-and-effect relationships. Here, the semantic layer ensures that both the LLM and the AI agents can query these metrics consistently across domains.
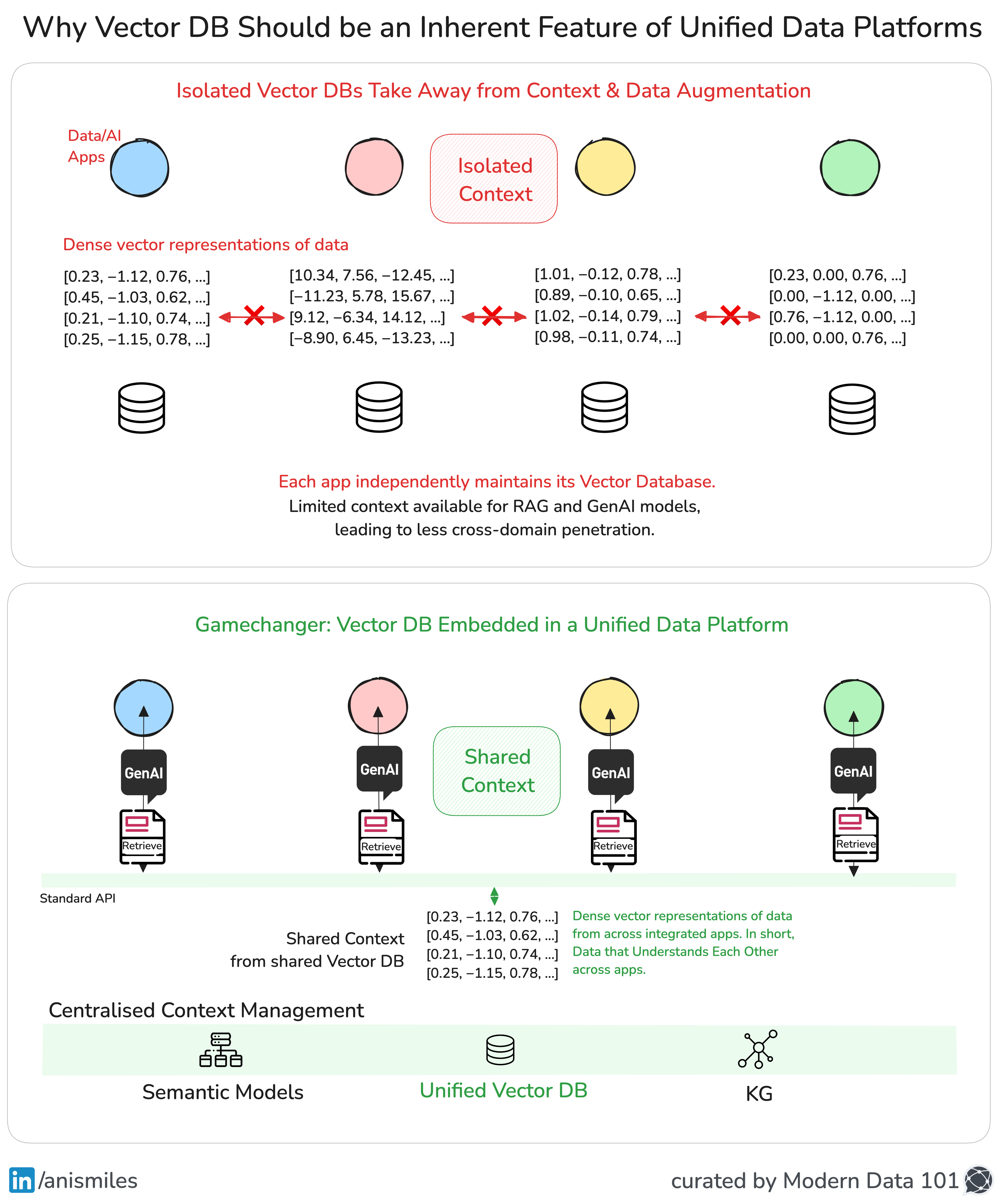
Resource Recommendation
A brief take by Animesh Kumar on the impact of Vector DBs when offered as an out-of-box feature of Unified Data Platforms
LLMs/RAG models use the semantic layer to interpret and translate marketing and supply chain terms into a unified business language.
The agents are configured to connect directly to the semantic layers. These layers abstract the technical complexity, allowing the agents to access clean, consistent data sets:
- Campaign Compass provides marketing metrics in predefined schemas.
- Supplier Hub delivers supply chain KPIs tailored to specific partner profiles.
Incorporating knowledge graphs to meet ends more effectively
Organisations leveraging custom AI agents tend to derive optimal value when focused on effectively integrating knowledge graphs to allow agents to delineate and understand the context of and the relationship between multiple data points.
Instead of using basic flat vector databases to feed the AI agent’s memory that could misinterpret similar information, incorporating a knowledge graph helps agents track and remember data with nuanced relationships.
For instance, an AI agent with flat memory is deployed for a marketing task. This might confuse similar-looking campaigns and target the wrong audience.
Using a knowledge graph, the agent links campaigns with audience details, past performance, and demographics. This allows it to make precise recommendations for each audience segment, avoiding generic suggestions and boosting campaign effectiveness.
The Data Governance Drill
When it comes to AI and data initiatives, governance cannot be a step back. Beyond the operational improvements, incorporating the data product platform is a governance driver as well.
Your data product platform serves as a unified layer that supports all data products, ensuring consistency in data management, governance, and security across domains through shared foundational technologies.
The governance engine operates centrally in the control plane, enabling both local (use-case-/domain-specific) and global compliance for data products across multiple domains in the data activation plane.
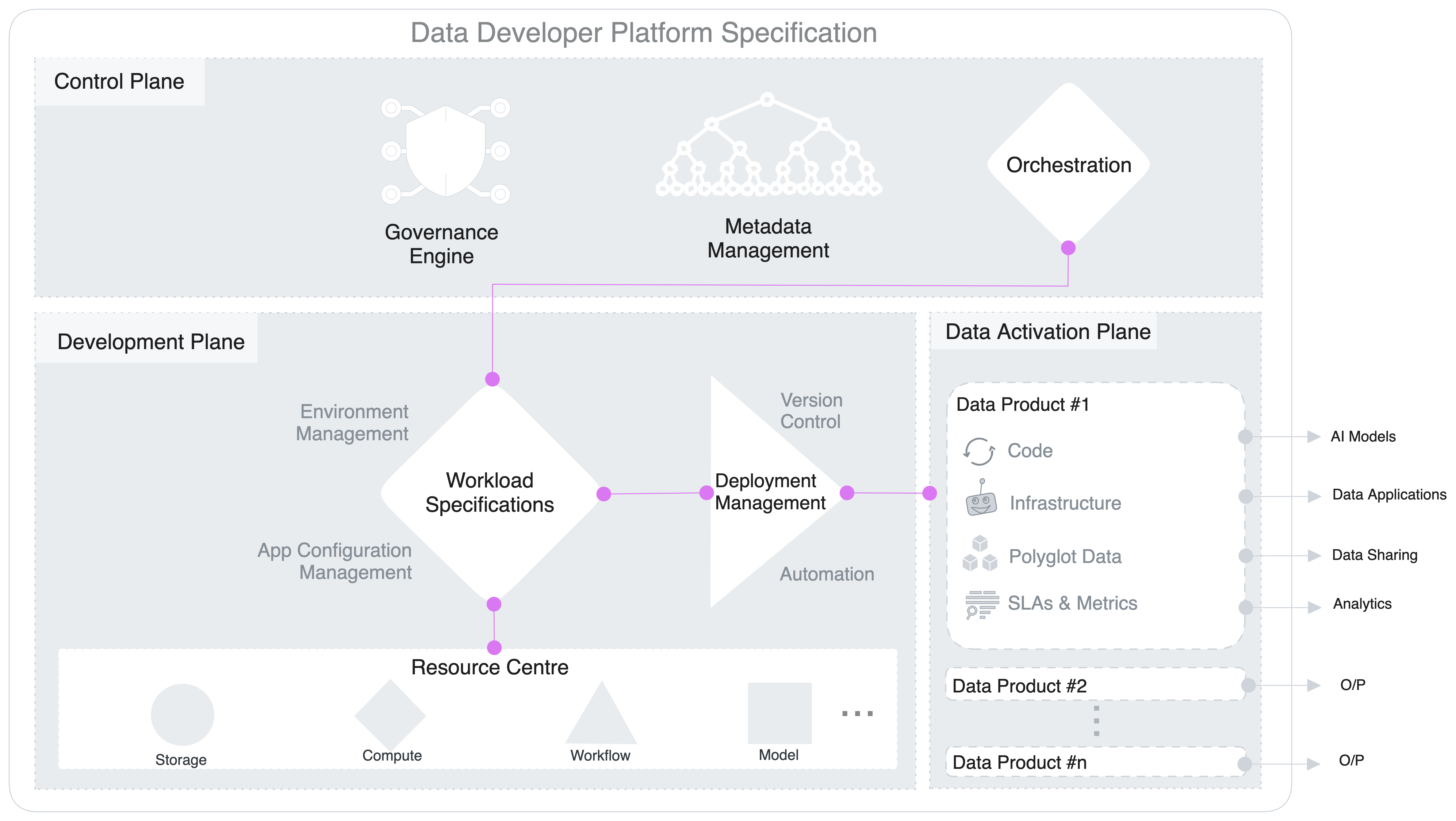
This inherently addresses a spectrum of AI-related compliance drills one layer up in the consumption plane. And with user trust becoming the key priority, addressing governance needs is a must with a data product approach in the AI space.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
MD101 Support ☎️
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Author Connect 🖋️

Find me on LinkedIn 💬

New on LinkedIn, join for a quick chat 💬

Find me on LinkedIn 💬
From The MD101 Team 🧡
Bonus for Sticking With Us to the End!
🧡 The Data Product Playbook
Here’s your own copy of the Actionable Data Product Playbook. With 1500+ downloads so far and quality feedback, we are thrilled with the response to this 6-week guide we’ve built with industry experts and practitioners.
Stay tuned on moderndata101.com for more actionable resources from us!

🎧 Latest from Modern Data 101
A senior analytics engineer and a founding member of the Data Product Leadership Community spilling the beans for the curious ones!