
Get weekly insights on modern data delivered to your inbox, straight from our hand-picked curations!
Take a joyride and embrace the evolutionary architecture, data-driven routing, 4D architecture, fan-out deployment pipelines, feature toggles, and conflict resolution in transitioning into the data product ecosystem.
With the rapid introduction of new and disruptive innovations in the data space, CDOs are in a very tricky fight-or-flight mode. It’s harmful not only for the role but also for organisations increasingly experiencing higher attrition. The disruption is not just on a technical level but also on a resource level, which is especially precarious when the role forms a pivotal dependency in the hierarchy of data teams.
We cannot and, in fact, shouldn’t stop innovations from coming our way. They are the key to better days. But we can take steps to shield ourselves from disruptions and volatility of our efforts.
The data architecture plays an important role as a shield against disruptive changes. We have received several queries about the transition angle, which especially stems from the inherent friction that comes with heavy transitions.

As the name suggests, evolutionary architecture aims to introduce changes incrementally without impacting ongoing processes. It impacts both development and operation cycles, enabling more efficient systems without the heavy cost of migration.
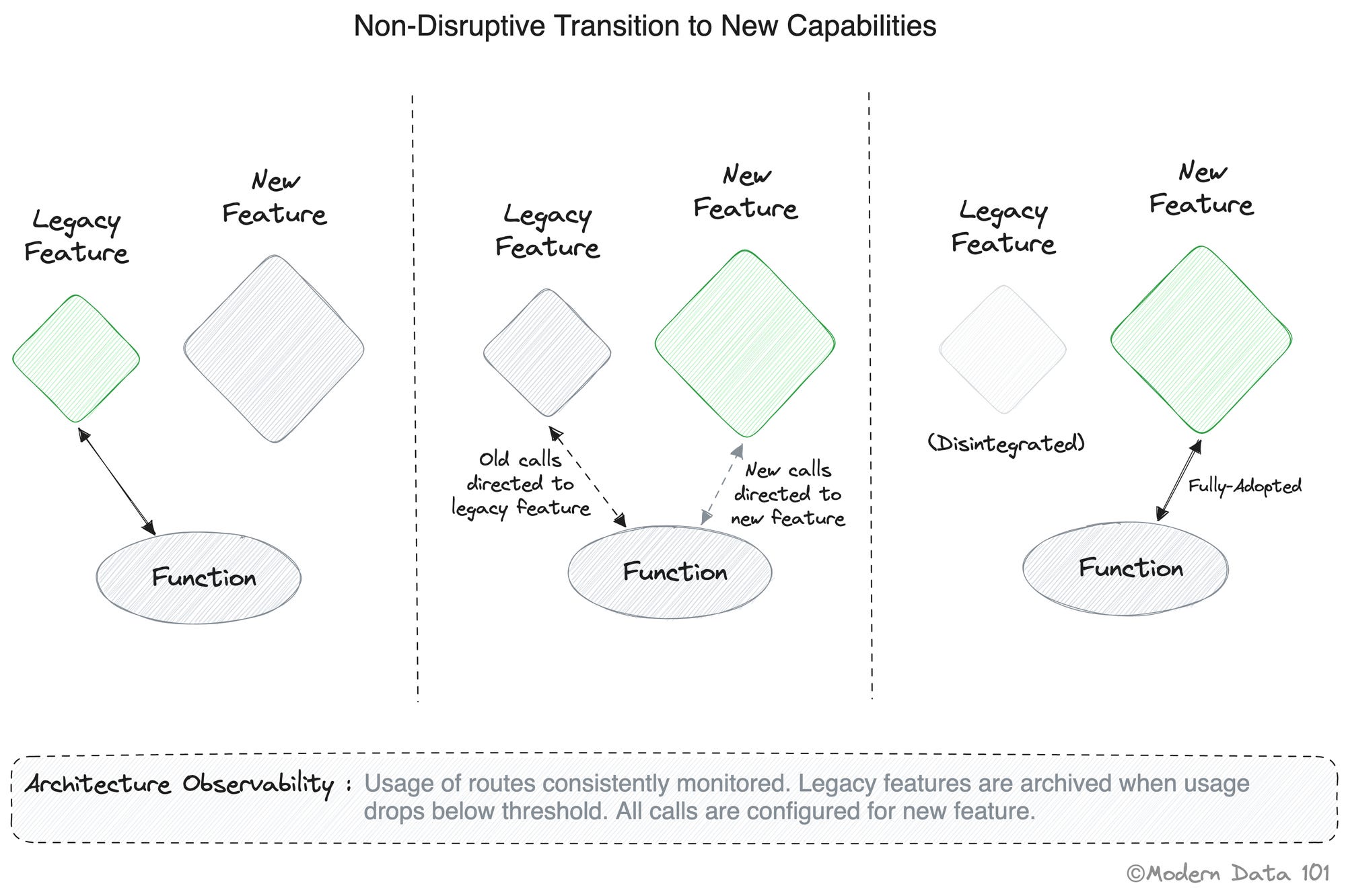
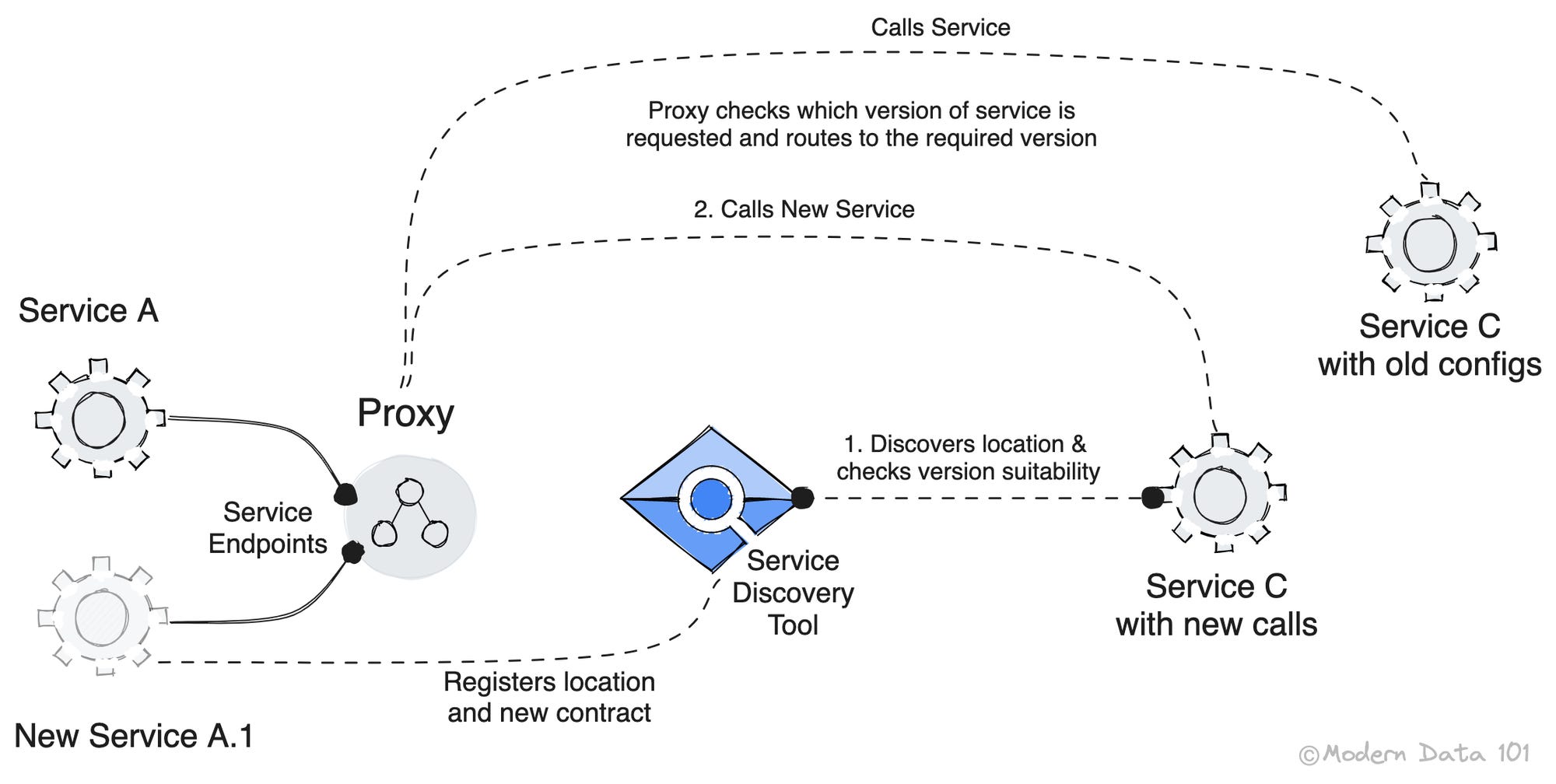
When a new feature is deployed by a team, and they want to release it to production without impacting existing upstream and downstream operations that integrate with their legacy feature, data-driven routing comes into the picture.
The new feature is deployed in a different environment/workspace.
1. All existing calls that are configured for the legacy feature stay as they are and continue to call the legacy feature.
2. Any new calls that are configured from dependent functions are configured to the new feature and start calling the new feature.
3. Architecture ops teams consistently observe and monitor the routes and record the usage rate.
4. Over time, as different functions configure their calls for the new feature, the usage of the legacy route drops below a manageable threshold.
5. All calls to the legacy feature (in the bucket below the threshold) are migrated to the new one, and the legacy feature is disintegrated/archived.
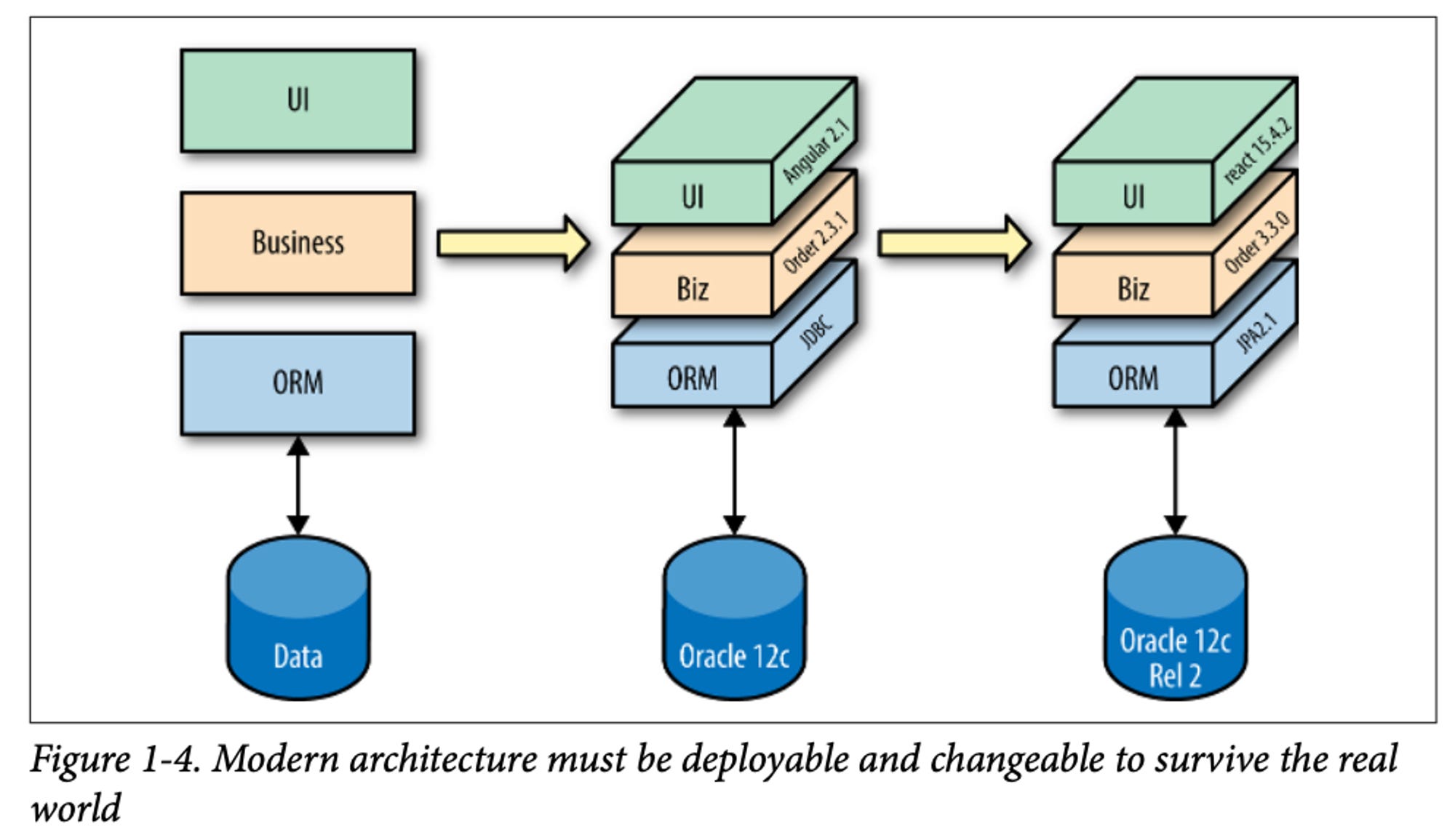
Contrary to popular perception, good architectures are not 2D diagrams with an absolute nature. A good architecture design spans across a 4D plane. Alongside a 2D structure, details of existing tools and integrations form the third dimension, and the architectural view across time, gives a concrete understanding of evolutionary transitions.
Architecture is abstract until operationalized, when it becomes a living thing.
(source)
A data architecture that takes dynamism and disruptions into account and is, in fact, built for change goes a long way in shielding data teams from the impact of rapid disruptions.
A real-world example of “timeless” architecture is architecture based on fundamental building blocks or resource-level granularity. In evolutionary architecture’s context, a fundamental architectural building block, “as described in Building Evolutionary Architectures, is an independently deployable component with high functional cohesion, which includes all the structural elements required for the system to function properly.”
These building blocks in a data architecture are a finite set of fundamental resources that have been uniquely identified as essential to the data ecosystem. For example, storage, compute, service, workflow, policy, etc. They enable architects and developers to rapidly configure and de-configure new models due to the virtue of modularization.
It’s like having a set of Legos which you can use to construct a house and then break it down to build a car. In both cases, the Lego blocks are the fundamental ready-to-use resources which the architect can use to construct any architectural design. This flexibility allows architects to manifest a 4D architecture in the real world, embedding their architectures with cushions for dynamic change and disruptions.
1. A hierarchical architecture for data is the fundamental need for scalable systems.
2. A composable set of resources - fundamental atomic building blocks and the means to quick pivots into variant higher-order frameworks or data design architectures such as meshes and fabrics.
3. A fundamental systems thinking approach to reap value from frequent and disruptive innovations without having to rip and replace months and years of hard work and investments- too common in the data landscape.
4. Evolving the organisation’s data stack with complete ownership and control into higher-order frameworks (and innovations) instead of rupturing under the weight of rapid disruption.
Instead of having engineers petrified with absolute and inflexible “best practices” that harm their agility and creativity, the deployment cycle needs to be embedded with more unit tests that catch outliers and violations. This conserves speed and allows developers to focus only selectively on the guidelines instead of spending hours and days figuring out the “new way”.
Any transition needs to be agile and a comfortable experience for developers and the people in general who are associated with the impacted processes. Without this agility, transitions are much more costly, time-consuming, and less effective overall.
Some developers try to “get by” with a continuous integration server but soon find they lack the level of separation of tasks and feedback necessary.
(source)
While continuous integration pipelines “get the job done”, they are not transition-friendly and not even a perfect solution for 2D architectures. They offer dedicated space for “build” ops and allow developers to embed multiple integrations frequently and early on in the data lifecycle, along with different essential tests. All these, while extremely helpful for building, especially a heavy-integration pipeline, end up as a heavy consolidated block.
However, developers feel the hiccups when they have to prepare for production since it involves multiple update-and-test iterations, demanding more atomic modules instead of one big consolidation. This also holds for transitory phases, which involve significant testability of isolated and experimental pipelines or services. Deployment pipelines divide a big chunky process into smaller independent stages, which are easier to manage and transform.
To execute these countless branches that arise during assessing production-readiness, deployment pipelines are fanned out into parallel tracks, which execute tests and processes and report (fan-in) to a common point. If all tracks are deemed successful, the code is pushed into production. This also allows developers and architects to design modular segments, irrespective of type (embedded or ad-hoc), that can run and be tested independently.
Many companies don’t realize they can use their production environment for exploratory testing. Once a team becomes comfortable using feature toggles, they can deploy those changes to production since most feature toggle frameworks allow developers to route users based on wide variety of criteria (IP address, access control list (ACL), etc.). If a team deploys new features within feature toggles to which only the QA department has access, they can test in production.
(source)
Rolling out a new feature in production doesn’t necessarily mean disrupting the existing processes in production. The best example of how this is feasible from an architecture POV is the Data Developer Platform’s Workspaces. Data Product developers/owners can create logically isolated environments to run their experimental features that integrate with the same inputs and write to an encapsulated board.
If the experiments are successful, they can be activated and iteratively replaces old calls with newly configured calls. These feature flags/toggles can also be coded into dynamic toggles to reduce the debt of manual interference. These dynamic pathways are referred to as toggle routers that trigger based pre-configured tests.
Data architects and developers can also build more confidence in their 4D models (transition-friendly architectures) by consistently embedding use and try blocks in the deployment pipeline. While the legacy code resides in use, the new/experimental feature resides in try and is passively executed. Any fatal flags or violations do not reach or impact the end user, but every execution gets logged for the developers to assess and make decisions for production readiness.
To create realistic 4D architectures, the data architect needs the likes of a conceptual telescope that can peer down at least a few quarters. The ability to have an overview of the broader goals and objectives of the primary teams and stakeholders is key to finding the right trade-offs early on in the process.
Discovering conflicting goals at a later stage leads to non-functional 4D architectures that are not adept at handling the transitory nature of data-driven organisations. They could be 4D on paper but miss the key element: future-state-friendliness. Conflicting goals lead to significant costs and time behind reworking and redesigning models and pipelines.
A real-world example of an architectural paradigm that allows conflict resolution at early stages is the Data Lens in Data Developer Platforms. It offers a logical view of broader goals from different domains and teams, operational models that are up for reusability, existing relationships between core business entities, and much more.
Data developers can use the lens to draft models across time on a logical level, which means no harmful impact on actual data entities or pipelines. They can explore different simulations and test them out with data-views and mock data to build higher confidence, and when they are happy with a concrete output, the pipeline can run its due course of A/B tests and iterations over the deployment pipeline before getting materialized in production.

