

Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

%20(1).png)
TABLE OF CONTENT



Like all software systems, data or AI use cases are supported by deep underlying infrastructures. But why has the infrastructure specific to data evolved into one of the most overwhelming of the lot? The brief answer is the transient element of data, which isn’t such a dominating presence in general software systems. Data is varied, dynamic, and always surprising.
As humans, we are tuned to invent as challenges come our way, and we did the same with data infrastructures—we added a new branch every time data acted a little moody, leading to uber-complex data pipelines and legacy structures that are impossible to demystify.
The solution seems simple: Data itself needs to be built into the data infrastructure instead of just passing through pre-built nuts and bolts (which are decoupled from data). Data needs to be an influence on the data stack to stabilise it or manage reactive evolution.
All along the evolution of data systems, if you really observe, data has never been an active part of the architecture. It has been passively managed by all the blocks and cubes built around it. It’s time to cut that passive cord and realise that what makes data infras quickly lose relevance (and overly complex) is that data itself is not built into the architectures.
But how can data be part of the infrastructure when it’s neither a tool nor a resource? Short answer: Data Products. In this piece, we want to take a cut at explaining the concept and essence of data products, keeping superficial definitions aside and targeting concrete value. There has been much dilution of the value of data products due to the favourable hype around it, but we hope this piece helps cut through the fog.
Before we begin, I’d like to resurface an excerpt from a great thinker of our time:
His [Ralph Johnson’s] conclusion was that “Architecture is about the important stuff. Whatever that is”. On first blush, that sounds trite, but I find it carries a lot of richness. It means that the heart of thinking architecturally about software is to decide what is important…and then expend energy on keeping those architectural elements in good condition.
For a developer to become an architect, they need to be able to recognise what elements are important, recognising what elements are likely to result in serious problems should they not be controlled. ~ Martin Fowler
The unmanageable tech debt of our times is a result of prioritisation inefficiencies, among other concerns. While it sounds simple, being able to decide what’s important is of primary value for any team, individual, or organisation.
It’s no different with Data. While it would be nice to have data power everything in our businesses, the pursuit of the same is immediately a lost cause.
While we can write down a dozen metrics that quantitatively “measure” priorities and importance, the big picture of what takes precedence boils down to cultural dynamics.
We HAVE to view Data Products with this same lens.
We cannot afford to cage it within strict technical boundaries. Otherwise, we risk failing at the problem we have set out to solve: reduce the data infra and volume overwhelm (instead of adding more clunky customisations every time there’s a novel query).
As the history of software goes, Applications have loosely been defined as such:
(Excerpt)
How different are applications and products really? While Data Products make a good phrase to easily summarise things in the context of data, there is little reinvention we need here.
Applications: Used for a purpose
Product: Used to omit/diminish effort spent on a purpose
When it came to the tussle of defining data products, the industry has taken a shot at each of the above. Some said data products were a single independent unit of code, data, metadata, and resources (infra). Some said data products were the fundamental unit necessary to serve a single business purpose. Some said it was both from two different angles. And some compromised on what made a data product a data product based on budget constraints.
From a 10,000 ft. view, all ultimately boils down to cultural influences.
For perspective, Here’s a data developer’s POV who works day in and out with data:
Within any organisation, the needs and expectations of various groups of consumers around data availability and timeliness (among other issues) will vary. This variance highlights the importance of Service Level Agreements (SLAs) in defining the boundaries of data products. SLAs help identify the appropriate split of data products within a cluster, ensuring they meet the needs of different data consumers.
~ Ayush Sharma in “Understanding the Clear Bounds for Data Products”
There are hundreds of other data teams approaching the problem very differently.
Data goes through multiple layers of people, processes, and transformations before reaching the actual consumer. Every layer of people and processes comes with its own cultural bias.
We can never take the risk of ignoring this bias. Ignoring it adds inefficiencies and frustrations in every layer, making the seemingly perfect theory a painstaking undertaking that suddenly adds unbelievable friction to the data-to-consumption flow.
Products dispersed across layers take into account the concerns of users located in different layers. In other words, they consider how Analysts/Data Scientists prefer to ingest and explore data in their workspaces, how the data engineering team operates, or how governance stewards prefer to disperse policies. What all these roles consider important as users = direct feedback for product development.
Let’s see how the priorities of both users and operators are considered by the product framework.

How Data Products Serve Key Business Metrics: A View into sequential development of Source, Aggregate, and Consumer Data Products.
As you can observe in the sequence, the products are coming up on demand, and the use case or purpose is at the forefront at all times. Let’s break this down a little.
Again, the aggregate products depend on how the team operates and decides to manage the constant stream of queries. How and what do data developers prioritise to quench user demands?
Complex source-to-consumption transform code gets broken down into more manageable units depending on the team’s approach to code and caching. Aggregates come into the picture over time where the team realises that a conglomerate is better able to serve a broad band of queries instead of direct iteration with source products.
This becomes a new product in its own right with a separate set of objectives, resources, SLAs, and greater context given its closeness to downstream consumers.
~Excerpt from another section of this text
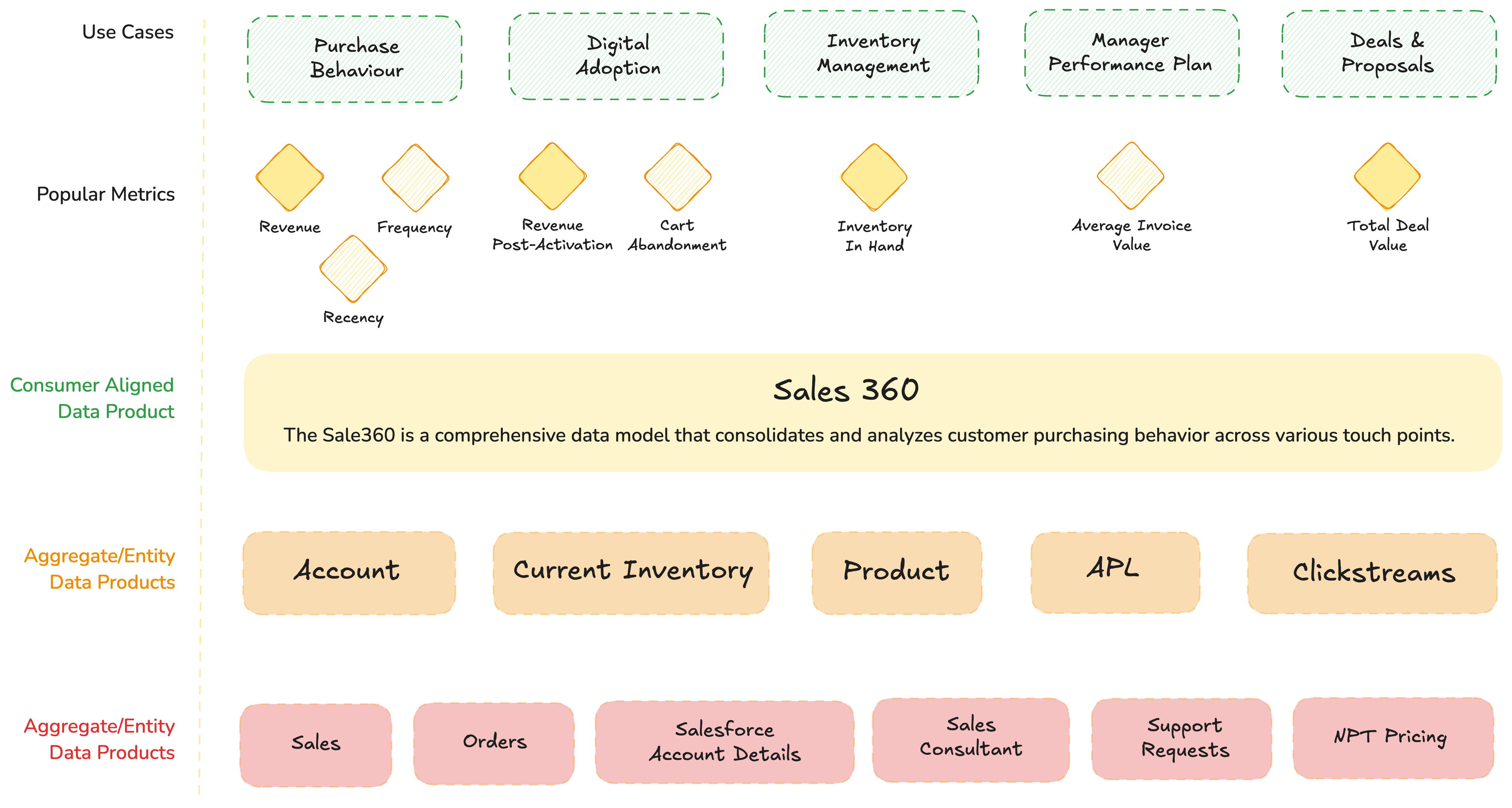
These aggregates are now directly powering the consumer-facing data product (Sales 360) and enabling it more effectively than source products.
Over time, all the necessary source and aggregate products are mapped out based on consumers' usage patterns and data developers' operational comforts until you have a solid network of reliable data going up and down product funnels.
The key difference is Product Influence, which enables teams to actually implement a right-to-left or user-to-sources journey instead of the traditional left-to-right data management (where the user gets what upstream teams send their way or consider “important”).
The key difference with the Product framework embedded in the architecture is that teams are able to not just drive efforts based on actual business goals, but are effectively able to work through priority gaps and tussles across multiple layers. All because every layer is now practically able to face the same direction. User User User.
In the last segment of this piece, we’ve broken down the significance of Product Influence and how it impacts the data citizens residing in different layers of the architecture.
(all diagrams are for representation only)
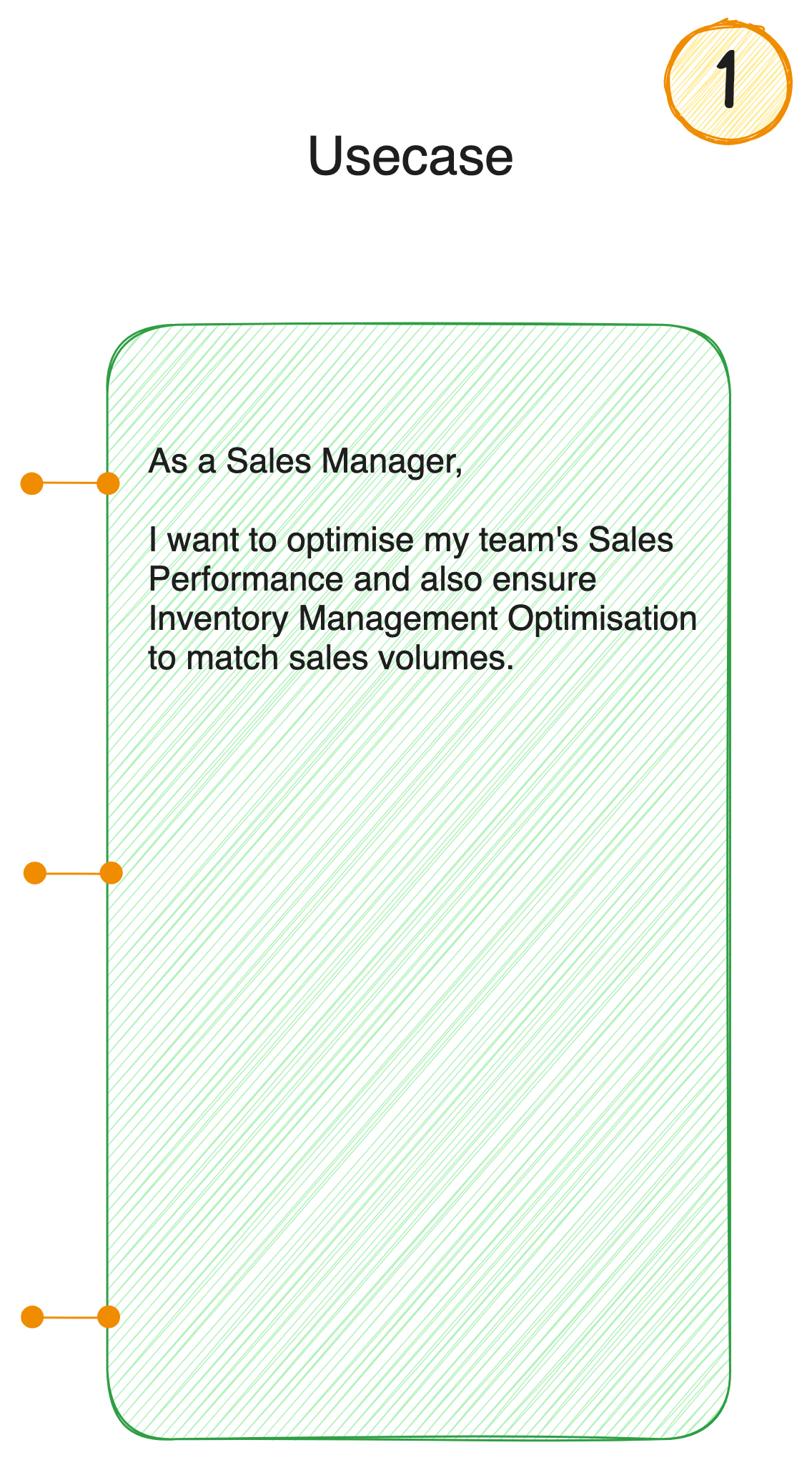
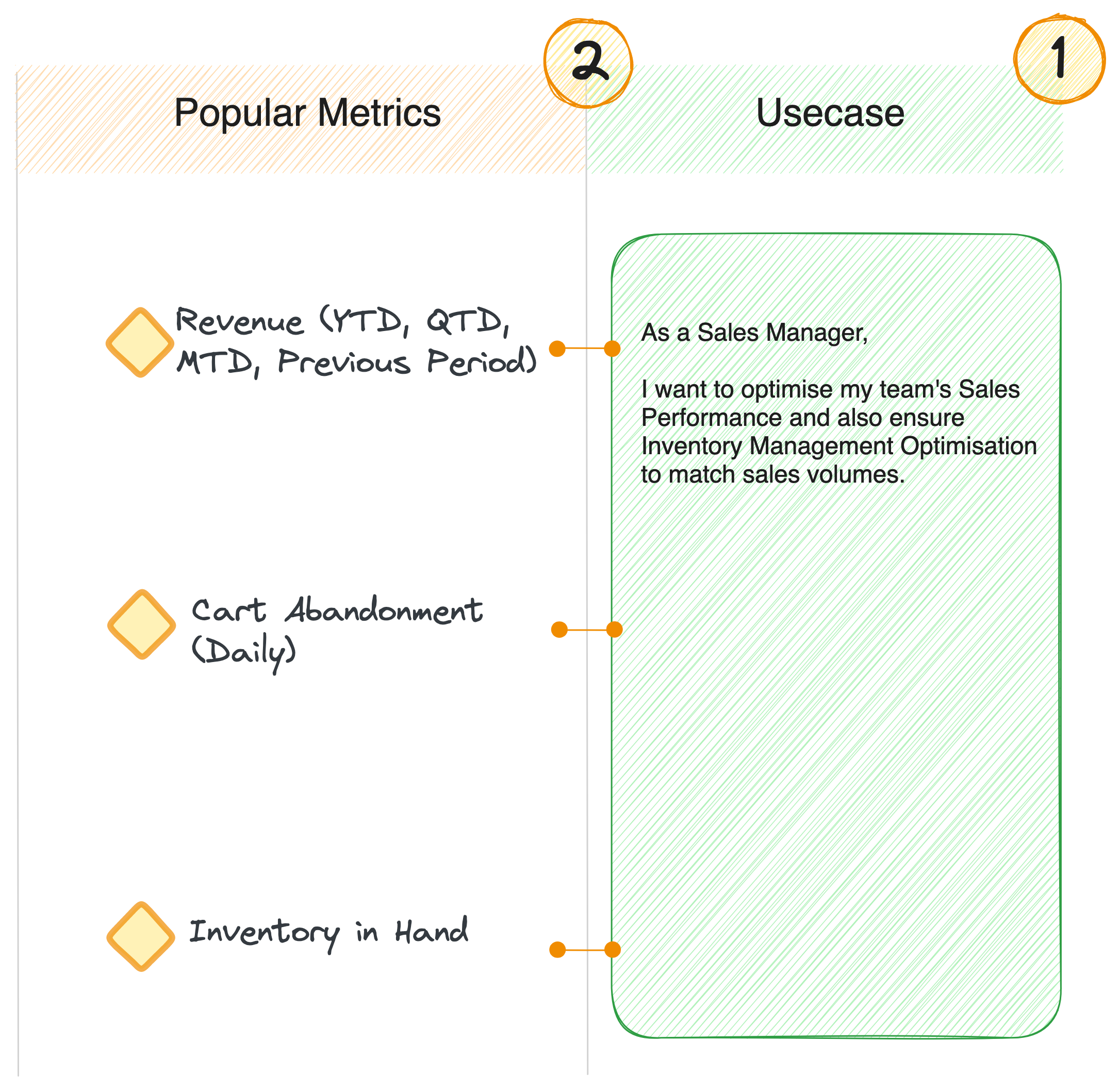
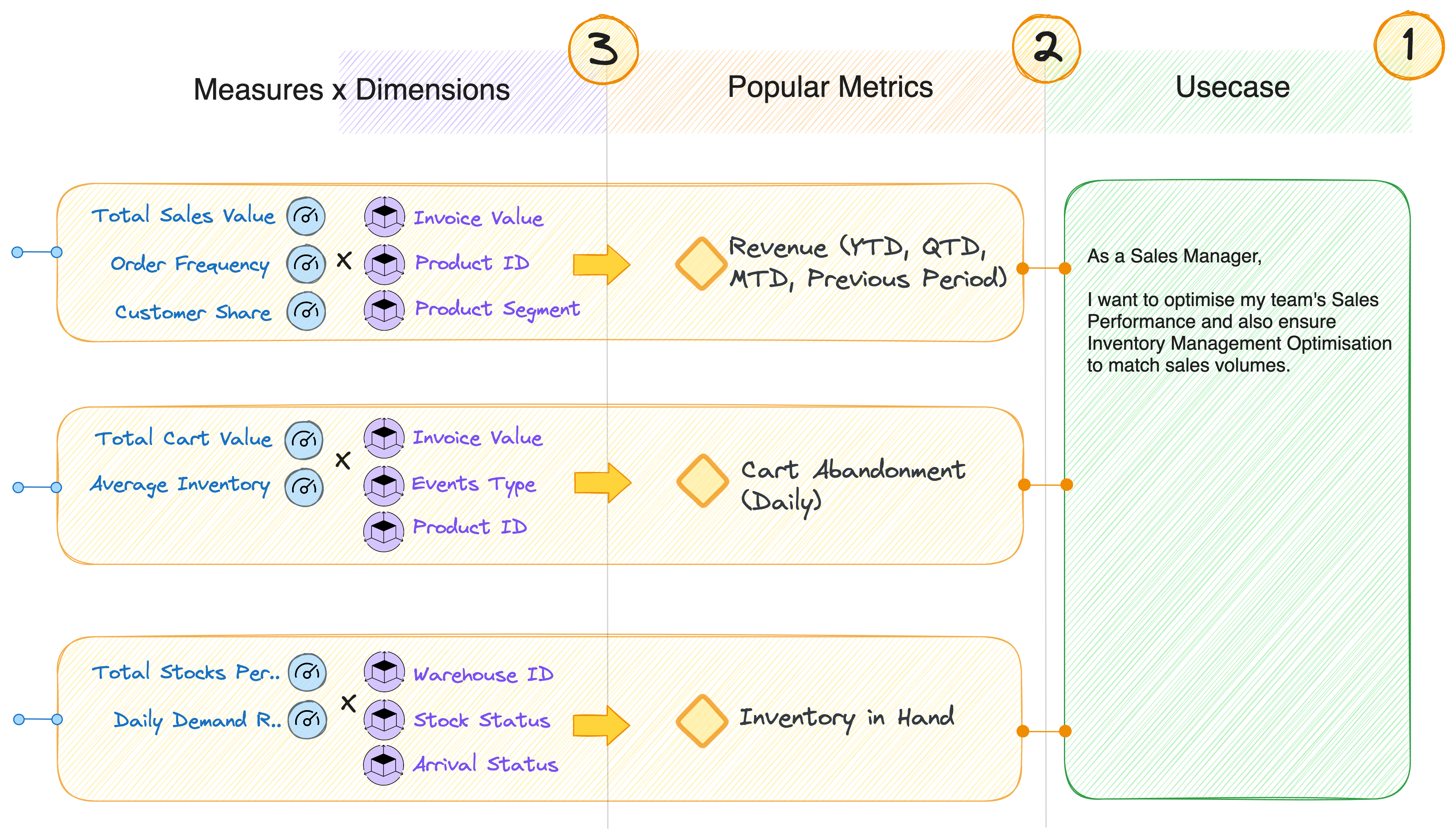
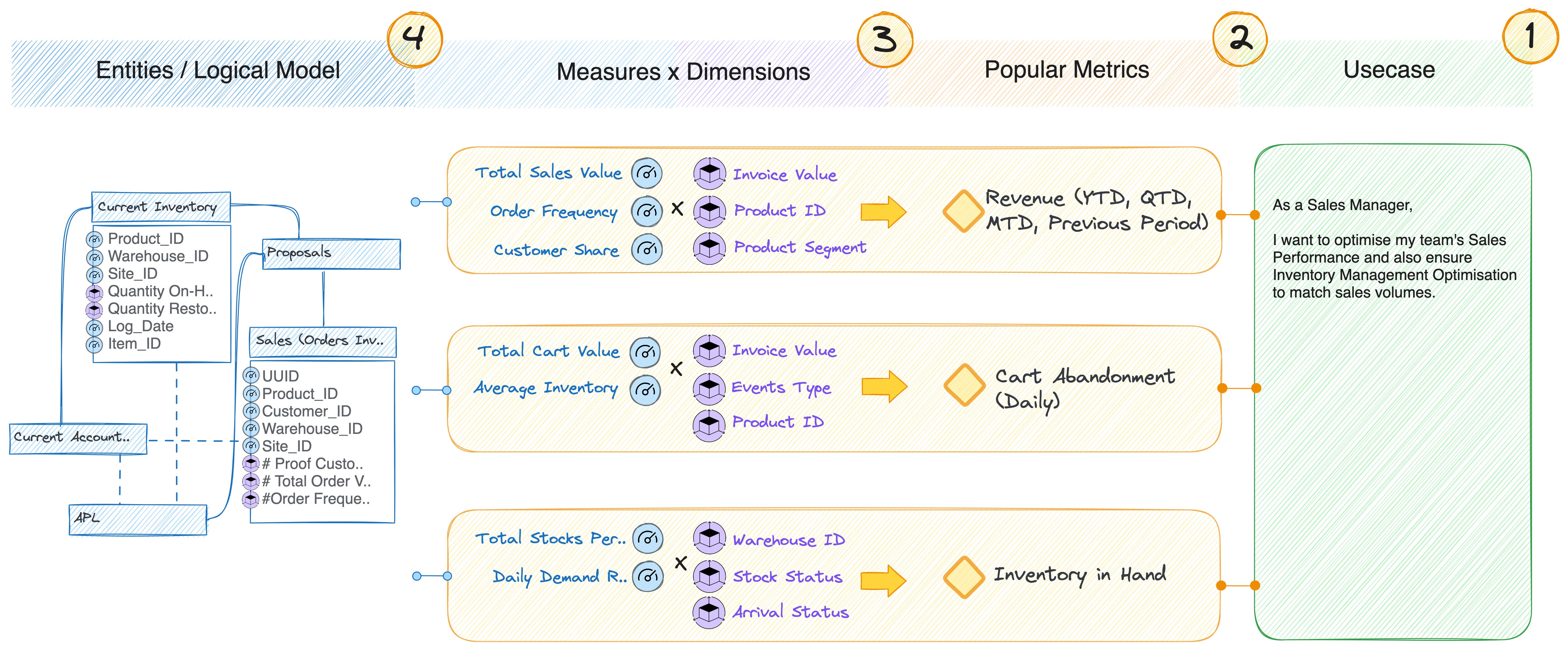
The outcome of stage 4 is the product prototype or the consumer-aligned data product model. Share
Imagine spending a ton of effort and resources only to find out there are bugs in how the model addresses the requirements. You need to iterate and get it right, and every time you do, it multiplies the resource cost and stakeholder frustration. This means running bills on compute, expanded timelines, and probably a CFO with a raised eyebrow at the end of 6 months.
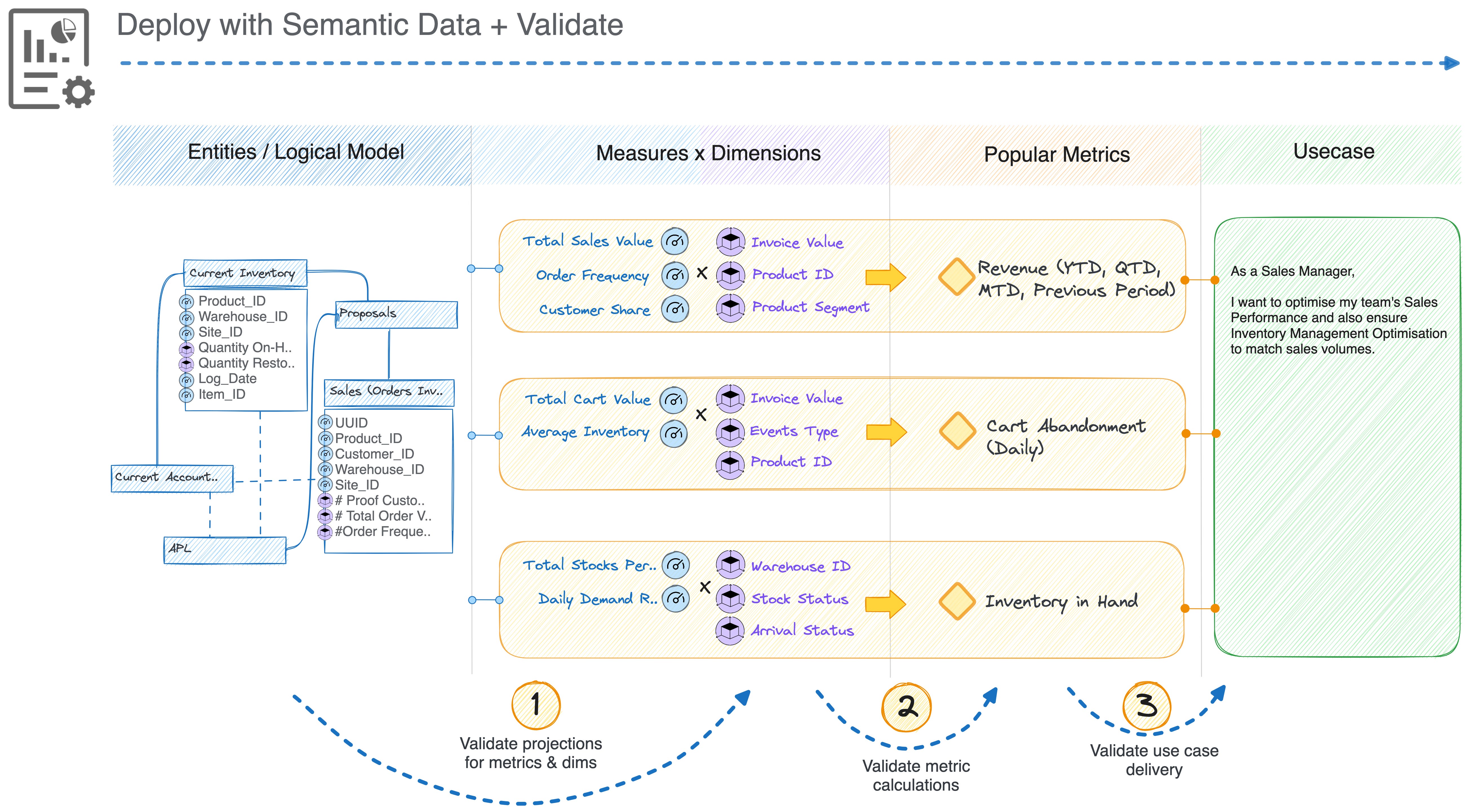
So, instead of spending ANY effort on actual data integration and iteration, you deploy with simulated or mock data. Of course, there are multiple ways to establish hyper-realistic data today that smartly reflect the domain’s character. Here’s one for reference.
On deploying the prototype with mock data:
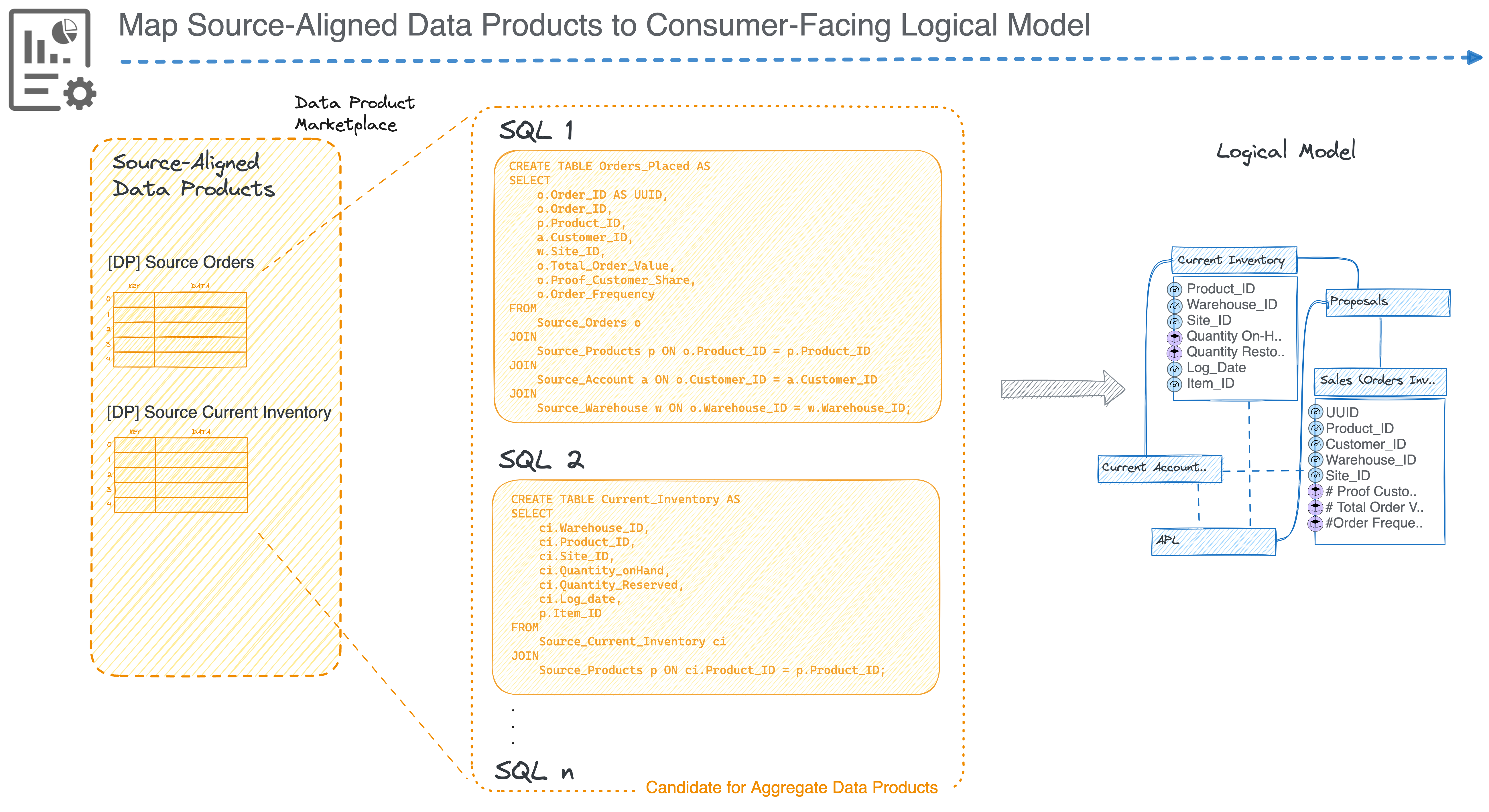
Let’s for a moment assume, you already have a pre-existing set of source products from other use cases. You start exploring the Data Product Marketplace and identify the suitable products for mapping to the new data product model. The transforms or SQLs from Source Products to Consumer Products become, as we saw above, potential candidates for Aggregate Data Products.
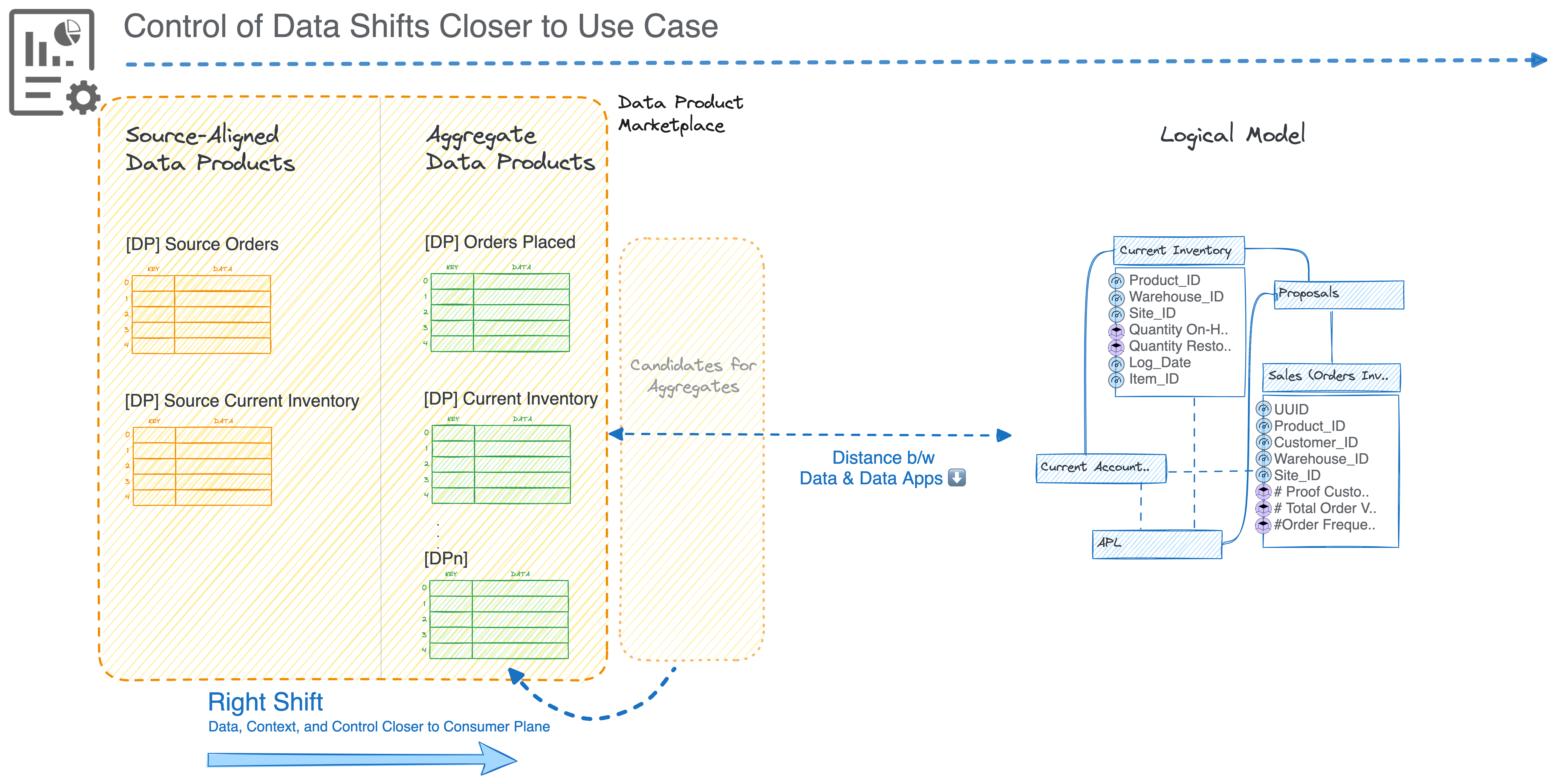
As soon as aggregate products are established, your journey from data to consumer is cut short by many hops and loops.
On a side note, how to convert SQLs to Products?
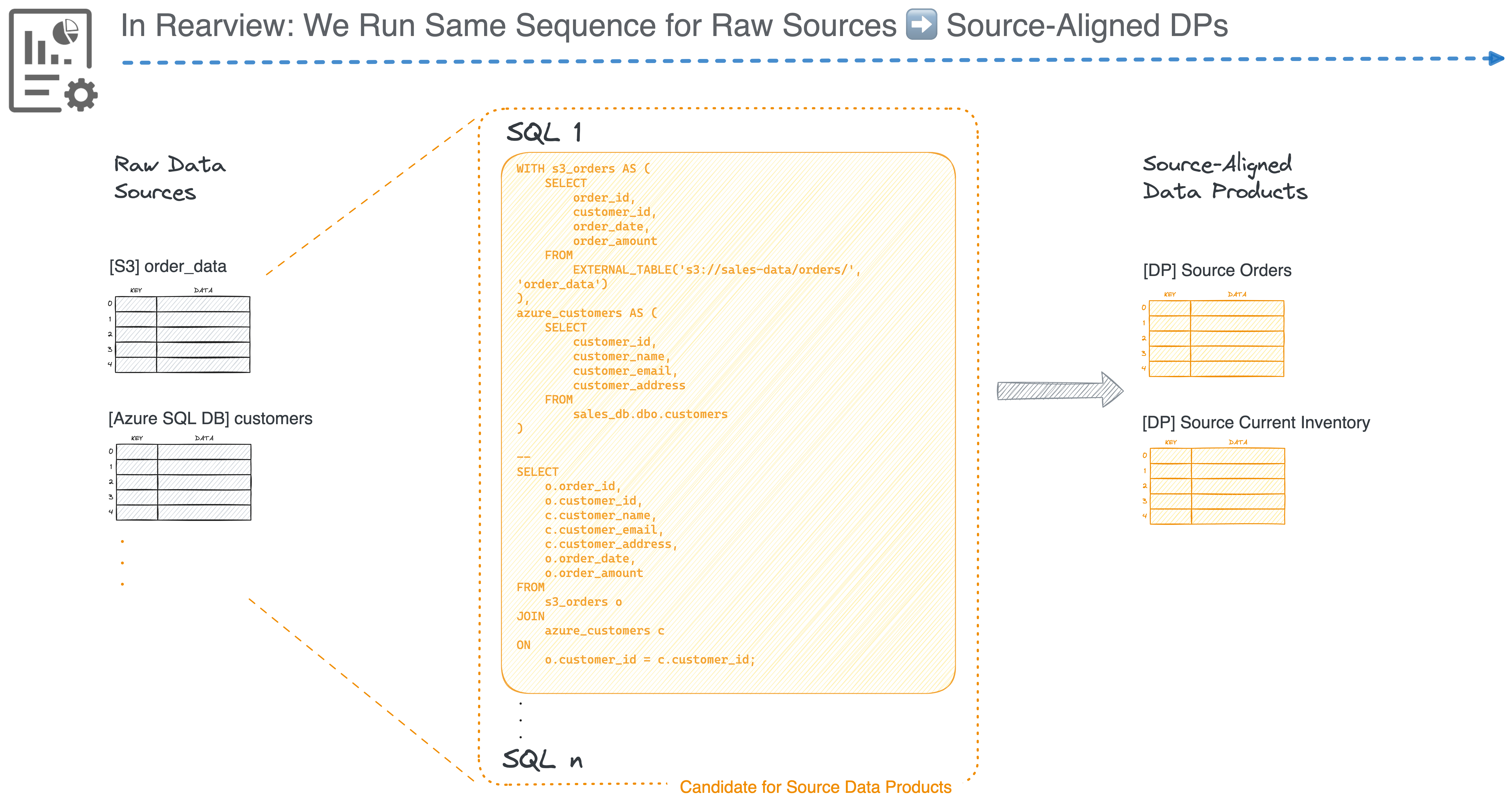
For the case of first-time adopters or no existing source products:
The business directly interacts with the Consumer-Aligned Data Product (CADP) or the logical Data Product Model. Based on changing requirements, they can create, update, or delete the Data Product. The distance between this CADP and the data progressively diminishes as more intermediate products pop up.
The journey from raw sources is significantly cut down to the distance between an aggregate product and a consumer data product.
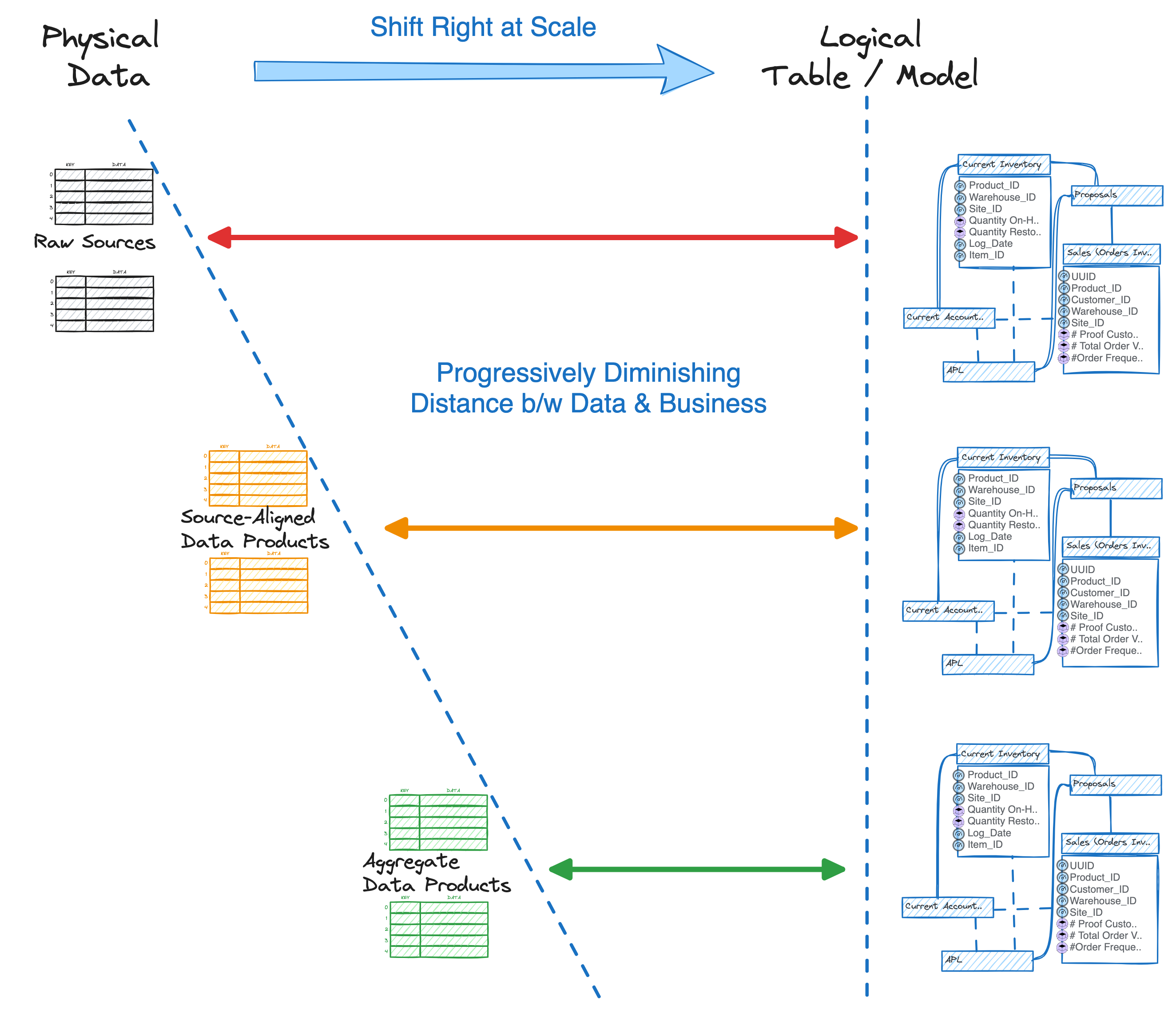
It is interesting to note that all products are independent and serve multiple aggregates or CADPs across different domains and use cases. Each has a lifecycle well within the bounds of the limited and well-defined purpose it serves.
This enables higher-level products to comfortably (with high transparency) rely on the inputs from lower-level products and essentially reduces the complexity and management overwhelm of the path between raw sources and consumer endpoint(s).
This brings us back to the question we started with: How can data be embedded into the infrastructure as an active influence that can stabilise and control the spreading wildfire of pipelines and model branches?
We have a wider context of the influence and impact of data products now, but here’s a different angle that ties together the loose end we started with.
Data Products cut through to the last strand of the data stack, from source to consumption. They are like vertical infrastructure slices (imagine greek columns supporting a huge pediment) inclusive of the data itself.

And the “Product” approach enables this influence by carrying downstream context all the way up (right-to-left).
Let’s take a look at the collective influence of data and product approach from source to consumption (the traditional direction and how it’s reversed):
Any mid-to-large org is burdened with an overwhelming number of data sources. Data Products cut down this complexity by bringing downstream context into the picture.
This gives us Source-Aligned Data Products- A combination of context, SLAs, transparent impact, and a clear set of input ports (only ingesting what’s in demand).
Based on how the data team operates and what they view as aggregates that serve downstream purposes more easily, complex source-to-consumption transform code gets broken down into more manageable units (depending on the team’s approach to code and caching). Aggregate Data Products come into the picture over time, where the team realises that a conglomerate is reusable and better able to serve a broad band of queries instead of direct iteration with source products.
For example, source tables like “Sales” and “Orders” might need more complex queries compared to the aggregate “Accounts”. This becomes a new product in its own right with a separate set of objectives, SLAs, and richer context due to its closeness to users. The Product is independent with a separate set of infra resources and code, with source products as input ports and isolated from disruption from other product engines.
SLAs are highly dependent on consumption patterns and organisational hierarchies. Who should get access and why? While a bare-bone quality structure works for one, another might find it essential to have higher quality demands.
The Product slices are built to influence a right-to-left flow of context: from users to source. What’s Level A of the requirements? How can we boil down the requirements from Level A to different touch points of the data across the source-to-consumption stack? Do upstream SLAs conflict with downstream necessities or standards? How can we get a clear picture of these conflicts without corruption from other unassociated tracks (which might be challenging given how pipelines overlap with little isolation of context)?
Products, by nature, are always facing the users. They’re built for purpose. Data Products enable the ability to define consumption while keeping in mind the user’s preferences. The user shouldn’t bend to the product, the product must bend to the user’s native environnment.
The data product is able to furnish multiple output ports based on the user’s requirements. We call these Experience Ports which can serve a wide band of demands without any additional processing or transformation effort (ejects the same data through different channels).
This may include HTTP, GraphQL, Postgres, Data APIs, LLM Interface, Iris Dashboards and more for seamless integration with data applications and AI workspaces.
From The MD101 Team
Here’s your own copy of the Actionable Data Product Playbook. With over 200 downloads so far and quality feedback, we are thrilled with the response to this 6-week guide we’ve built with industry experts and practitioners. Stay tuned on moderndata101.com for more actionable resources from us!

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

.avif)


Animesh Kumar is the Co-Founder and Chief Technology Officer at The Modern Data Company, where he leads the design and development of DataOS, the company’s flagship data operating system. With over two decades in data engineering and platform development, he is also the founding curator of Modern Data 101, an independent community for data leaders and practitioners, and a contributor to the Data Developer Platform (DDP) specification, shaping how the industry approaches data products and platforms.

I am a passionate & pragmatic leader, architect & engineer. I use iterative architecture & lean methodologies to deliver software products with measurable value, aligned with goals & objectives, on time & with balanced technical debt.

Find more community resources

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.





