



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.png)


TABLE OF CONTENT




The Modern Data Stack or MDS has been a frequent subject of debate among technocrats. This could easily be confusing for data personnel and the frequent question that floats up is
Aren’t we supposed to implement the modern data stack instead of running away from it? After all, it is the “modern” equivalent of the legacy frameworks which aren’t the best alternatives either.
Consider the MDS as a giant experimental direction that has not been faring too well, so the data industry at large is experimenting with other strategies or directions. But what is the Modern Data Stack experiment and why are data practitioners overwhelmed with it?
Some key phrases to note here:
The MDS is positioned to solve the above two problems, but is it doing a good job at it? Not really.
The MDS could easily be referred to as a double-edged sword: while it solves problems A & B, it creates problems C & D, and the cycle continues. Anybody that wields the MDS is bound to suffer a couple of wounds.
After engineers solved (data collaboration) problems within Big Tech, the rest of the industry raced to copy them without being thoughtful about their unique data needs. The products of the Modern Data Stack were primarily developed in highly mature data ecosystems to solve very specific infra issues. The tools were not fundamentally designed to operate in a workflow. This is not necessarily a bad thing (In fact, I think most tools in the MDS are excellent) but it creates a mentality rooted in ‘what’s next?’ instead of ‘Are our fundamentals in place?’.
~ Chad Sanderson | Head of Product @Convoy
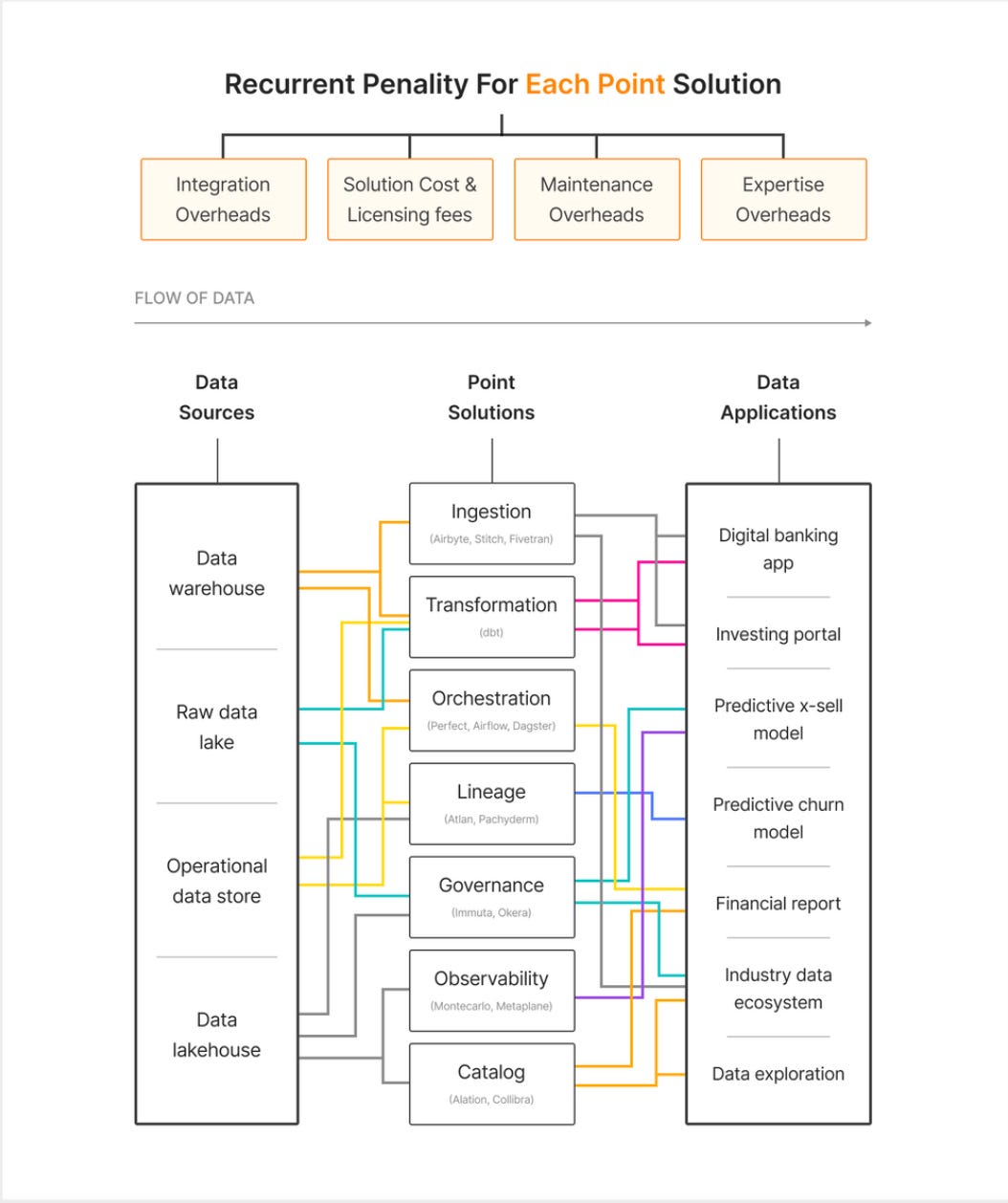
Over the last five to six years, hundreds of tools popped up in the data space and each claimed to solve part of the problem, creating an overwhelming number of competitive tools. In any typical data architecture today, data practitioners are faced with a constant need to decide and report which tool to plug in and why that tool makes more sense than a pool of other options.
Every tool in the data ecosystem is not typically integrable with any and every other tool in the data architecture. Often a little push is necessary to fit the tool right in. Moreover, even if tools work in harmony with all other pieces in the infrastructure, there’s always an added effort of checking integration feasibility and then tying up the tool with every other piece every time any new tool is onboarded.
Every time a new tool is onboarded, an excess cost is incurred behind the solution and licensing fees which have to be processed and renewed recurrently. There’s also a huge cost behind employee onboarding, training, and hiring the right expertise. Especially when it comes to niche tools that require specific skills.
The MDS redirects data teams from focussing on data and applications to maintaining the infrastructure that powers the data and applications. If, say, 70% of the team’s effort is spent on maintenance, 30% is spent on building the right applications that could mine valuable insights that could actually impact the bottom line.
In spite of tightly coupled ties between multiple tools, an overwhelming number of integrations easily become fragile, and soon the tools stop communicating with each other smoothly. In other words, there is rampant friction between tools, leading to data and insights being caged within the walls of siloed tools and environments.
Learn more on what is a data stack and its evolution in this blog.
Evolution of the Data Stack: The story of how we interpret ever-growing data
Agile Principles
State of Modern Data Stack
MDS has successfully solved several collaboration issues of legacy systems. However, while it solved several challenges, it also presented new ones. The primary reason was that it was not built around people, but more around processes, tools, and specific infrastructures which neither accommodate change nor flexibility.
Due to complex integrations, multiple layers, and the resulting information friction, significant gaps between business and IT folks develop. No common layer for business teams to define, enforce, and operate business logic and requirements across the physical data and architectures exists. This actively increases the number of interactions between teams to resolve the after-effects of data solos.
With isolated tools, there is not enough information or metadata, preventing a detailed insight into the data ecosystem. So while teams brainstorm new ways to improve excellency, their plans are limited to foundations of partial information.
Agile Principles
State of Modern Data Stack
MDS is resistant to change due to the vast web of upstream and downstream integration points where change has to be reflected. Moreover, the change is always reflected in abrupt phases since all the pipelines are never up at the same time in real-world scenarios. Due to this resistance, continuous delivery and continuous integration (CI/CD) is challenging for MDS. With tons of point solutions to integrate, operate, and fix, the focus is stolen away from ensuring a continuous data flow across business and IT teams.
Agile Principles
State of Modern Data Stack
Installing and maintaining the MDS drags the data-to-insights journey across months and even years. The cycle ends up being a long span when integration, maintenance, and onboarding overheads are taken into account. To get to the point of a working data product, several iterations and backtracking must be overcome.
Agile Principles
State of Modern Data Stack
While even the MDS can be designed well, it is limited to a weaved architecture where every integration is a continuous source of data debt and requires consistent maintenance. MDS imposes complexity instead of simplicity on its users with data silos, integration overheads, and recurrent licensing complexities.
Since its inception, ModernData101 has garnered a select group of Data Leaders and Practitioners among its readership. We’d love to welcome more experts in the field to share their story here and connect with more folks building for better. If you have a story to tell, feel free to email your title and a brief synopsis to the email-ID of the author.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



