



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...
%20(1).png)
.png)
TABLE OF CONTENT




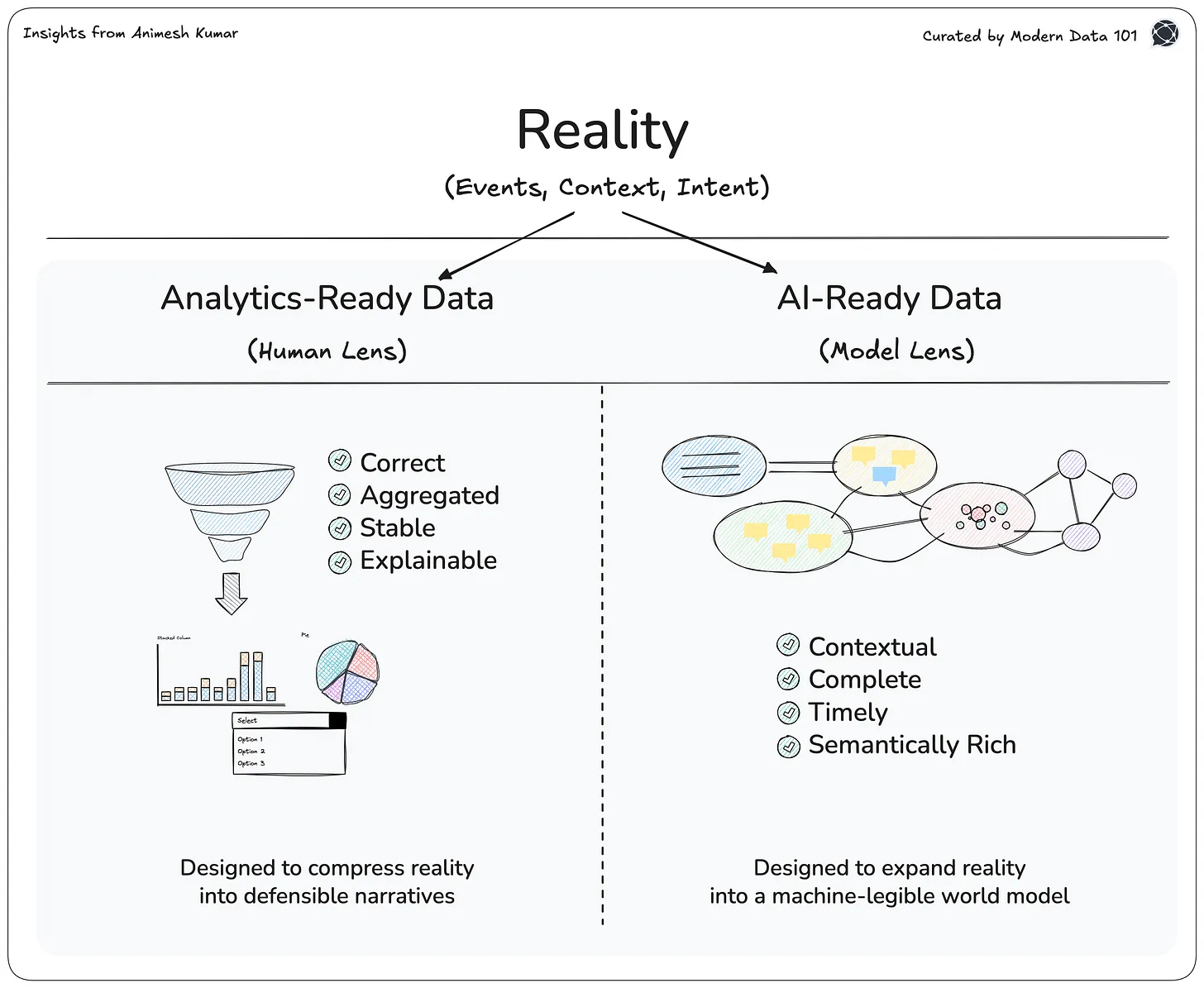
Understanding the Semantic Layer as a Standard Reference
The Workaround: N-Dimensional Data Cubes & Marts
The Obvious Next Step: BI Tools
The Solution at Present: Semantic Layer
Pitfalls of the Current Solution & Roadmap
Outcome of a Reliable Semantic Layer
If you’re reading this, you’ve already heard about the semantic layer. This is especially true in the recent past when semantics wasn’t just a layer in the data stack anymore but transformed into a movement that deems it a must-have. It’s good news for all of us that data discovery and context are getting the attention they deserve.
While it may seem inevitable now, it wasn’t always the first thing we, as a data industry, set out to solve. But now, it’s a non-negotiable. Why though? Data was always ever present. Why didn’t we need sophisticated semantics to understand it better from the get-go?
While data was ever present and hasn’t actually grown in volume (contrary to what you may hear), we’ve just become better at tech capabilities that have, over time, evolved to capture various streams of data. For instance, IoT devices today even detect breath and subtle movements to enhance air conditioning. Every click, view, and event has significant and potentially beneficial business results if the patterns are identified successfully—and we can capture it all now.

As the data we can tap into has grown, the need for automated context has grown as well. If there are 2 tables recorded cryptically or with some domain-specific jargon, for example, cryptic SAP table names such as TRDIR and D010TAB, it might be easy just to memorise them or refer to a key/cheatsheet to understand what they’re really for and if you can use them.
However, when the same problem pops up from countless tables, data formats, sources, and business domains, the cost of understanding the data is back-breaking. There is a loss of time and opportunities, the cost of mistranslations, miscommunications, semantic mistrust, and so much more.
But impressively, as data citizens, we have always strived to solve the problems driven by our innate need to understand the world around us better. Our solutions have sometimes matched the size of the problems, and when they failed, we moved on to create the next best solution.
It’s rather interesting to note how when there’s a new solution on the frontline, we don’t shy away from declaring it THE Solution that would solve all pains and multiply all gains. But taking an honest look at anything and everything, except perhaps coffee that does solve everything, there is no product or solution out there that would ever have the last word.
The point of mentioning this is to encourage an open mind while criticising and glorifying past and current solutions. On that note, let’s take a look at how we tried to solve semantics in the past and how we arrived at the semantic movement.
Instead of defining by characteristics, we want to express semantics in terms of its purpose.
We’ve tried to keep this brief and to the point, but feel free to add if you think we missed an important capability.
Let’s dive back into the journey from past solutions that sought richer context to the ongoing semantic movement.
As we know, in modern data ecosystems, context often starts taking shape when a number of data entities are stacked up. Let’s take a measure for example→ discount %.
In real-world scenarios, the discount % applied against a customer is not a straightforward “apply-to-all” function. It’s rather a very complicated function that takes into account:
In a more analytical context, I need to extract one measure from dimensions sprinkled across multiple tables or views. Understandably, the context behind something as simple as discount is complex due to the variety and volume of data we capture and generate. But as a sales analyst, all I need to know is what discount % is fit for a particular prospect/customer.
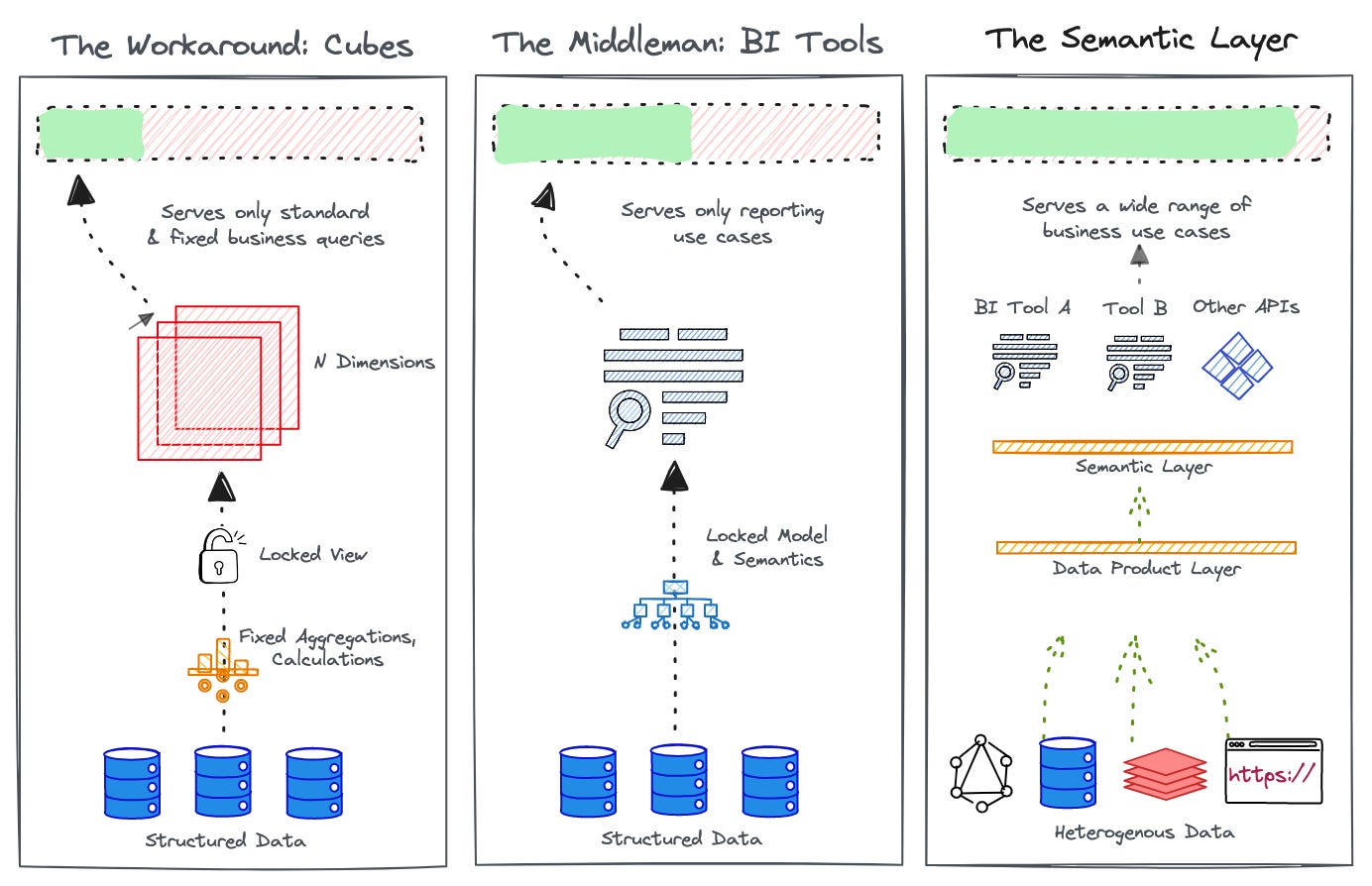
To solve such recurrent analytics requirements, we came up with data cubes that stored standard aggregations, calculations, and function-specific data, which could be queried by our sales analyst. You could slice this cube, roll it up, pivot it, and run all sorts of functions to get different views of the data at hand. Similar to cubes, data marts also stuck to function-specific data that gave different business units the flexibility to have complete control over the data.
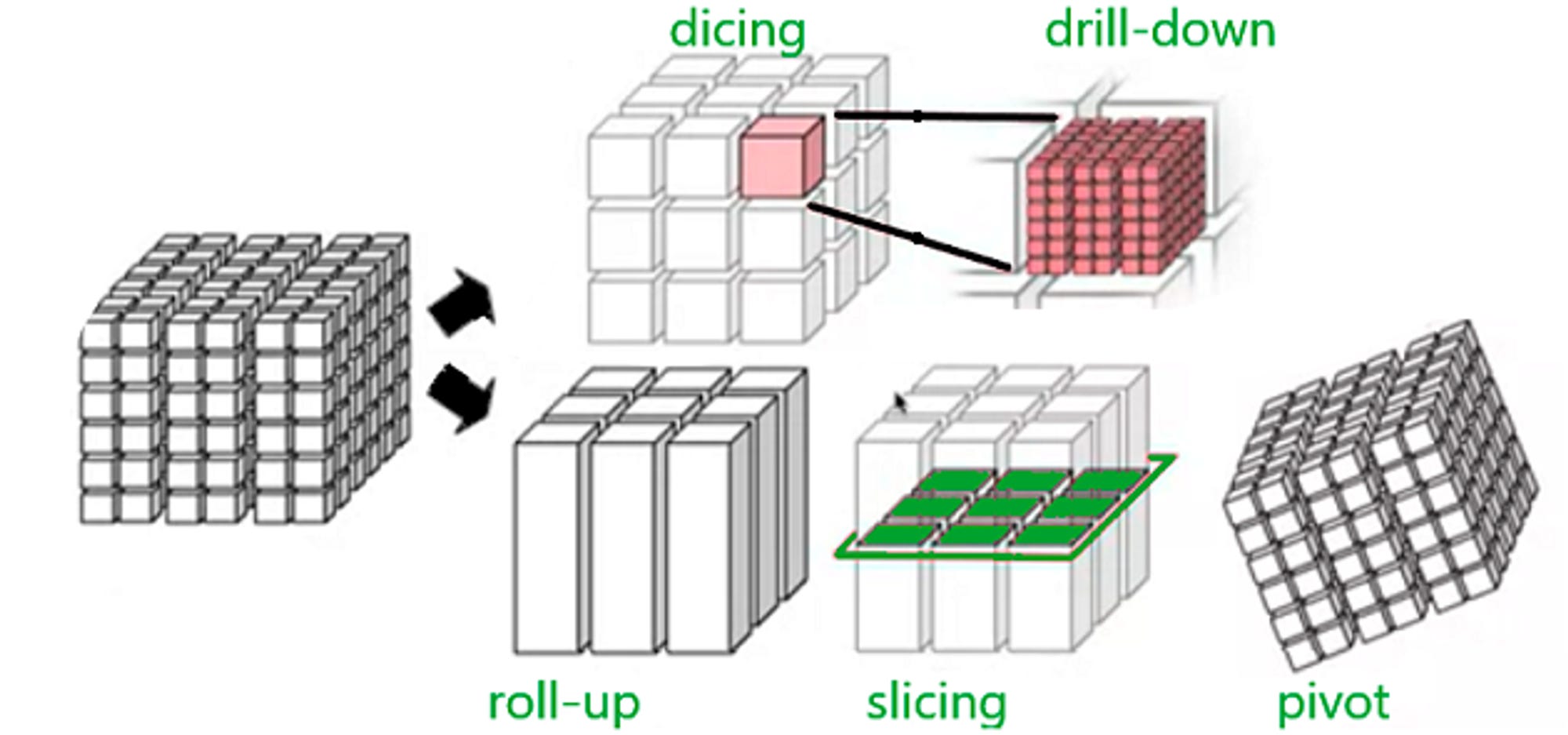
Cubes were an excellent solution for a time when compute power was limited. But while cubes or cube-like stores resolved the most-asked queries and standard business aliments, they left no space for analytical innovation. You had to stay within the bounds of pre-calculated measures from pre-decided aggregations. And while there was flexibility in how business units had control over their data, in doing so, they lost the bridge to global context.
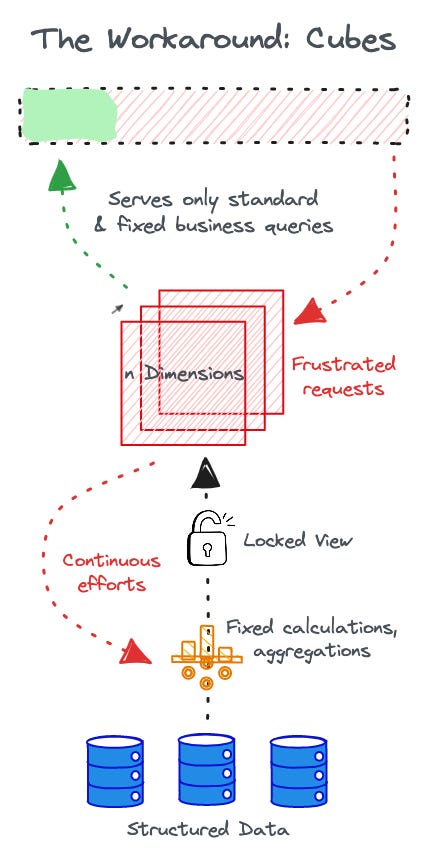
Analysts had to think of all edge cases that a business unit might need to solve and add the corresponding aggregates, combinations, and calculations to be able to serve a unit efficiently. But as we know, businesses have undying curiosities and queries. As novel queries stacked up, it made the cube model even more impractical and ineffective. Think multiple unresolved tickets, inability to keep up with business pace, and build-up of frustration between analytics engineers and business teams.
Any query that was remotely novel, had to be remodelled into the cube. New calculations had to be run through iterations with domain experts and analytical engineers for feasibility. New aggregates had to be constructed.
BI Tools brought in a refreshing change and visibly contributed to pushing businesses forward. It taught us that data was never meant to be trapped within the boundaries of closed spaces. Context needed to be globally accessible and understandable for true scale and flexibility in leveraging the actual physical data.
While there are many instances of BI tools being used with cubes for reporting, it wasn’t an effective model or standard way to use the tools. Instead, BI tools were better leveraged with direct access to the data layer and building on top of it.
With a direct path to data, say to warehouses, BI tools gave the ability to define semantics or context around the data through logical models. Users could directly define metrics, calculations, and associations on existing tables and run reporting functions as necessary. In other words, something very similar to a semantic layer/model (we’ll soon see why this wasn’t enough).
This eliminated the lock-in of cubes that had the tendency to cause discrepancies, disconnection from the larger context, or inflexibility. Business users could query data directly or create new custom definitions instead of having to query from a bounded set of pre-defined aggregations and variables.
Why, then, did it create the need for a semantic layer?
While BI tools freed us extensively from inflexibility and from the lock-ins of restricted cube or cube-like models, they also bestowed a certain form of trap that we wouldn’t become fully aware of for a long time: BI tools meant limited semantics if not limited data.
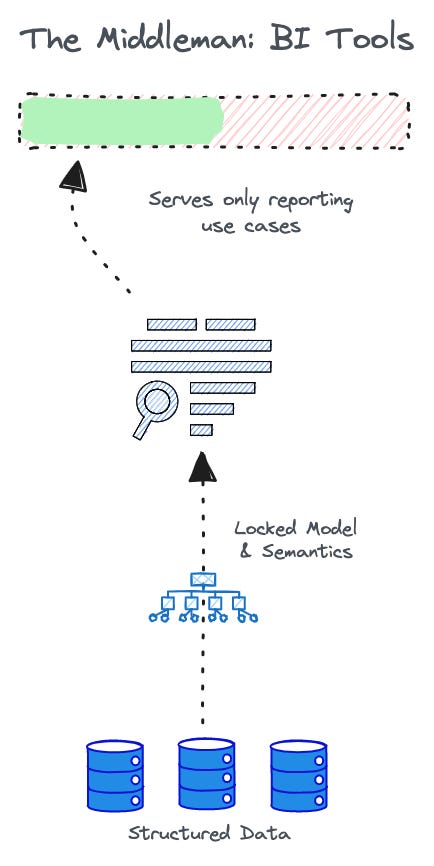
The analytics team could have a fully defined model locked inside their preferred BI tool, which would make it inaccessible or, rather, absolutely inoperable for any other team or tool sitting outside this ecosystem.
For instance, if the Product Team wanted to use some analytics data that the BI team had managed in the past, it would have to find a way to integrate with the existing BI model, work from scratch to understand and associate with their specific semantics, and then project the same through their custom apps or interfaces. While described in a few lines, it could easily take over 6 months to get the process up and running.
This limits the power of data and even semantics extensively. It adds a lot of rework and shuts down scalability with data in real time. Semantics shouldn’t be trapped inside one tool or vendor, and it most definitely should not serve reporting solely.
Semantics, by its innate nature, needed a medium to branch out to become accessible and operable by all entities in the data ecosystem, including all forms of technology (tools/interfaces/apps native or familiar to different functions) and a variety of personas in the data ecosystem for diverse use cases.
In traditional approaches to the semantic layer, you’ll find that it’s mostly restricted to reporting use cases. But why limit semantics only to reporting or replacing the BI layer? The proposition to solve the limitations of BI (and solve them less half-heartedly) is a dedicated layer for semantics which could not just talk to multiple BI tools (as preferred by different teams) but also a variety of tech counterparts as needed.
We only have to come down one step from the BI tools to position a global semantics layer that has end-to-end visibility and is also visible to all entities in the data stack. It’s a pure decoupling of semantics and BI.
This implies multiple use cases across multiple domains benefitting from the same logical layer instead of reworking logic from the ground up, running frustrating iterations with different teams, integrating and maintaining ties, and surviving clashing contexts.
On a more granular level, this means the ability to reuse metrics, measures, and other data entities after understanding what it means for different units with high clarity. Most importantly, it is the ability to flexibly build more niche context on top of existing broader context.
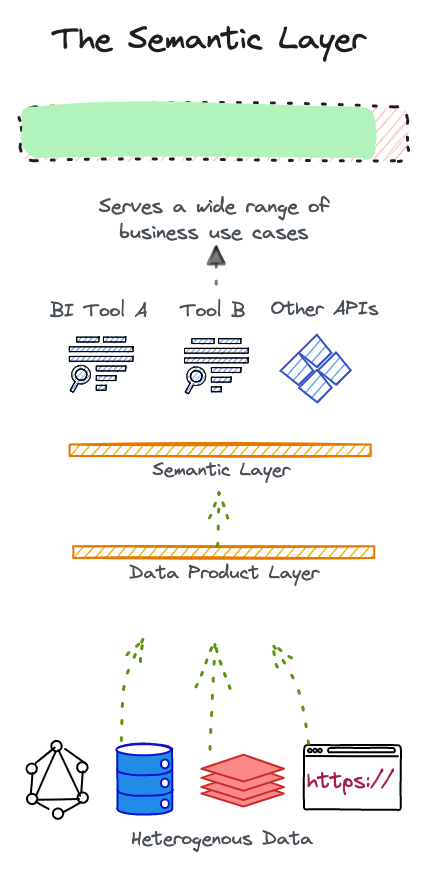
We will go a step further to understand the potential of the semantic layer and some of its pitfalls, which would shed more light on the true power of this dedicated layer ⬇️
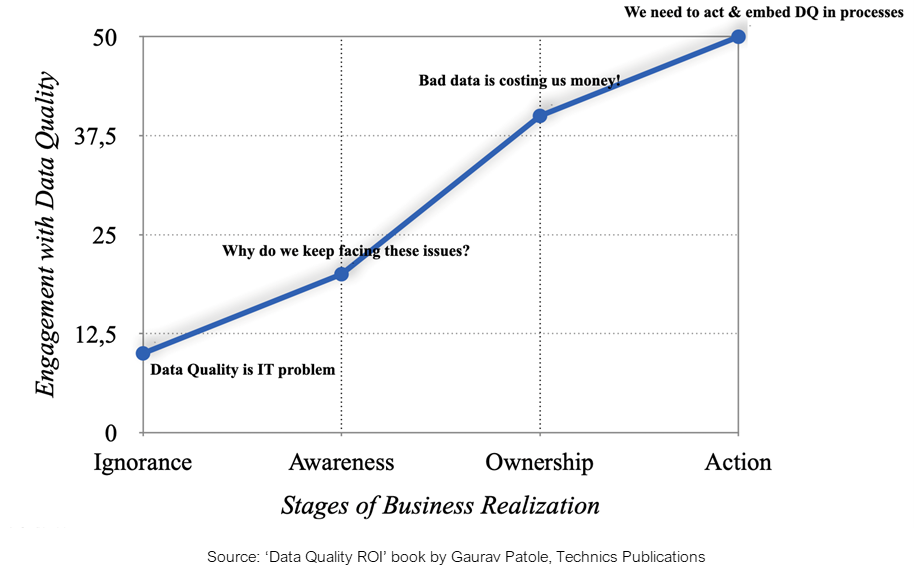
The semantic layer could easily turn into a wolf in sheep’s clothing. Semantic untrustworthiness stems from the chaotic clutter of modern data stacks, where there are so many tools, integrations, and unstable pipelines that the true and clean semantics gets lost in the web. Another level of semantics is required to understand the low-level semantics, which just complicates the problem further.
By directly placing a semantic layer over the physical data, you are solving the problem of discoverability and context. But you are also duplicating the same data issues (lack of SLOs—quality & governance) to the semantic layer. The sales analyst may be able to locate, understand, and use the right measures and metrics, but is the value of the metric even dependable?
This is where model-first data products save the day. Let’s overlook grandiose vocab, and instead, for a minute, let’s focus on the value. Model-first data products start from context and then move down to activation efforts.
In other words, through a prototype of the logical model in the semantic layer, you’ll be able to define the exact requirements that you need your data to serve (becoming purpose-driven).
Accordingly, the data product is developed and the logical model gets activated in the semantic layer. This enables the data, metrics, measures, dimensions, and any other assets served by the semantic layer to become dependable through guarded SLOs on quality and access.
For more insight into model-first data products, refer here ⬇️
Metrics-Focused Data Strategy with Model-First Data Products | Issue #48
Emphasising again, the semantics layer shouldn’t be limited to reporting use cases. It has the power to serve much more. If the semantic layer comes with the ability to accommodate data APIs, the data suddenly becomes accessible to a wide range of data applications, interfaces, and third-party analytics tools.
Imagine the huge potential of this capability. With data APIs, you can not only create applications on the fly but also templatise industry-standard and domain-specific applications for reusability and scale—drawing power from the same semantic models underneath, which serve quality-approved and governed data. For instance, consider a GraphQL endpoint which anyone can get responses from (with necessary SLO-based conditions).
The applications are endless with data APIs + semantics layer. You can power LLMs, predictive models, reporting dashboards, share data with external parties, create customised applications for internal domains or customers, and much more.
On its own, the semantic layer is adamantly stuck on solving just the problems of discoverability and context. Bringing in a semantic layer as an isolated solution means also bringing in a basket of other tools for critical functions such as quality, governance, observability, and more (to not duplicate the issues of physical raw data).
Instead, the semantics layer as part of a more complete vertical of the data stack is more practical in real-world scenarios. The vertical implies:
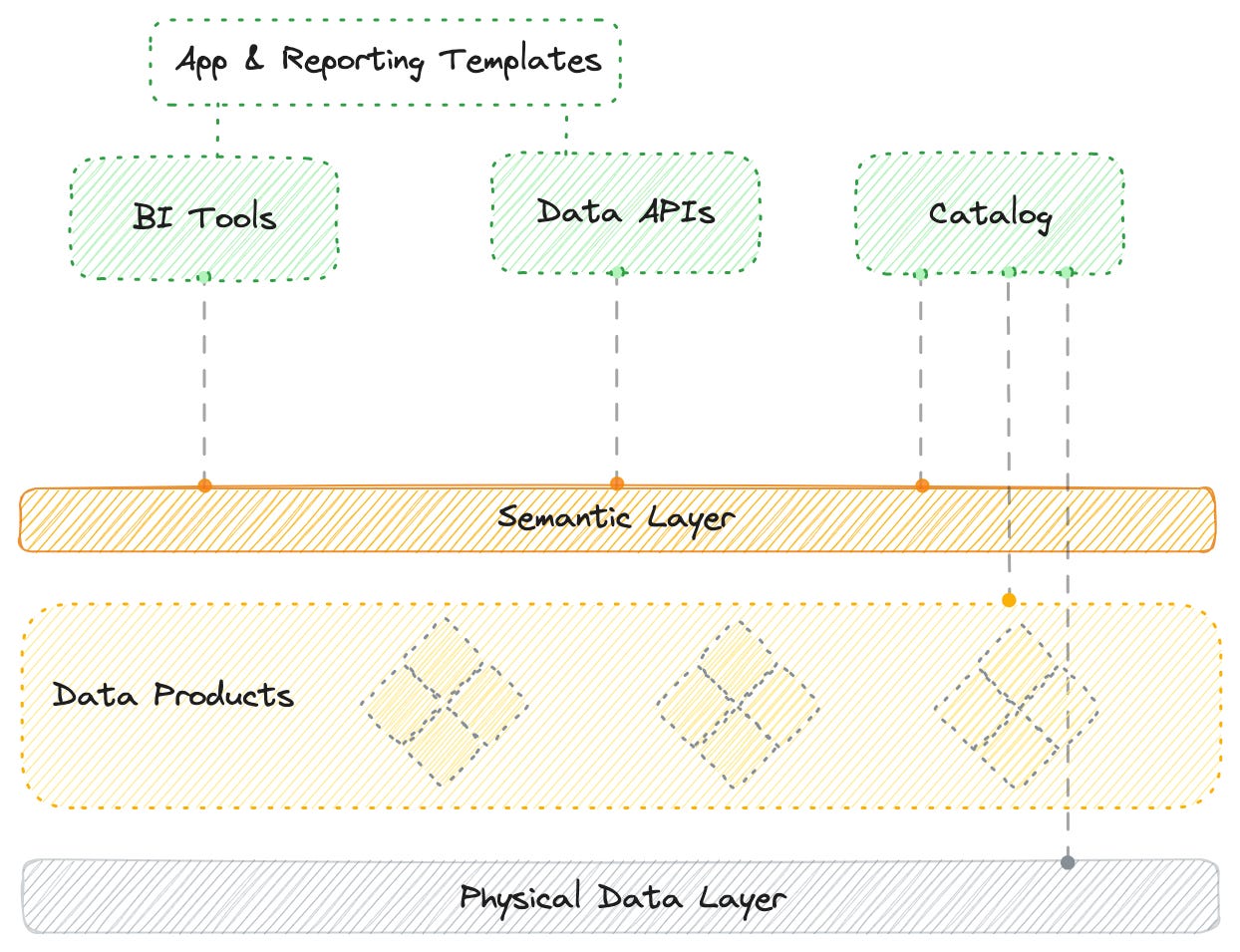
Consider how, in a Data Developer Platform, both the semantics layer and the physical data layer feed into the All-Purpose Catalog, which further powers the Business Glossary. The All-Purpose Catalog's simple ability to become a bridge between the logical and physical layers has huge potential.
In traditional semantic solutions, this connectivity is amiss. Any and everybody needs to go through the logical barrier (which may be biased) to make sense of the physical data, limiting the flexibility of the physical data and the use cases it can serve.
Domain experts need the ability not just to access context but also to take a call on whether the context serves its purpose with respect to the actual data at hand. With this bridge, you are not only adopting the benefits of the semantic layer but also getting ++benefits of accessing the context defined at both logical and physical layers.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


