

Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...
.png)
.png)
TABLE OF CONTENT



We need to end the disaster of disparate storage in data engineering. We’ve been so used to the complexities of multiple data sources and stores as isolated units, we consider it part of the process. Ask a Data Engineer what their usual day looks like, and you’ll get an elaborate spiel on overwhelming pipelines with a significant chunk dedicated to integrating and maintaining multiple data sources.
Having a single isolated lake is far from the desired solution. It eventually results in the same jumbled pipelines and swampy data- the two distinct nightmares of a data engineer. There is a dire need to rethink storage as a unified solution. Declaratively interoperable, encompassing disparate sources into a single unit with embedded governance, and independent to the furthest degree.
We’ve covered the entire problem analysis, ideation, and implementation across two parts.
Part 1 covers the design, approach, and experience of Unified Storage. Watch this space for
Part 2, where we share the implementation and experience of the users of Unified Storage.
But before we dive head-first into storage and its many fascinating dynamics, we have an exciting announcement! Animesh will be speaking with Divya, Partnerships & Strategy Leader @ThoughtWorks, in Boston next week. If you’re attending the CDOIQ conference or are in Boston, make sure to stop by on 18th July, 3:30 PM Friday!

Find the deets here: CDOIQ 2023 Agenda
Back to our story!
Let’s all agree, based on historical evidence, disruptive transformations end up costing us more time and resources than the theoretical plan and given the data domain is mined with rapidly evolving innovations, yet another disruption with distant promises is not ideally favourable for practical reasons.
So instead, let’s approach the problem with a product mindset to optimise storage evolution- what are the most expensive challenges of storage today, and how can they be pushed back non-disruptively?
Access to data is very restrictive in prevalent data stacks, and a central engineering team has to step in as a mediator, even for minor tasks. The transformation necessary to make your data useful creates multiple dependencies on central engineering teams, who become high-friction mediators between data producers and consumers. Engineers burdened with open tickets in not uncommon, indefinitely stuck in patching up countless faulty pipelines.
Storage so far has only been treated in silos. Data is optimised specifically for applications or engines, which severely limits its usefulness. Analytical engines that it doesn’t accommodate suffer from gruelling speed and expensive queries. Isolated sources also mean writing complex pipelines and workflows to integrate several endpoints. Maintaining the mass sucks out most of the engineer's time, leaving next to no time for innovating profitable projects and solutions.
The consequence of the above two challenges is the extensive cognitive load which translates to sleepless nights for data engineers. Data engineers are not just restricted to plumbing jobs that deal with integrating countless point tools around data storage, but they are also required to repeatedly maintain and relearn the dynamic philosophies and patterns of multiple integrations.
The high-friction processes around data storage make accessing data at scale extremely challenging. Therefore, even if the organisation owns extremely rich data from valuable sources, they are unable to use it to power its business. This is called dark data- data with plausible potential but with no utilisation.
If storage continues to be dealt with as scattered points in the data stack, given the rising complexity of pipelines and the growth spurt of data, the situation would escalate into broken, heavy, expensive, and inaccessible storage.
The most logical next step to resolve this is a Unified Storage paradigm. This means a single storage port that easily interoperates with other data management tools and capability layers.
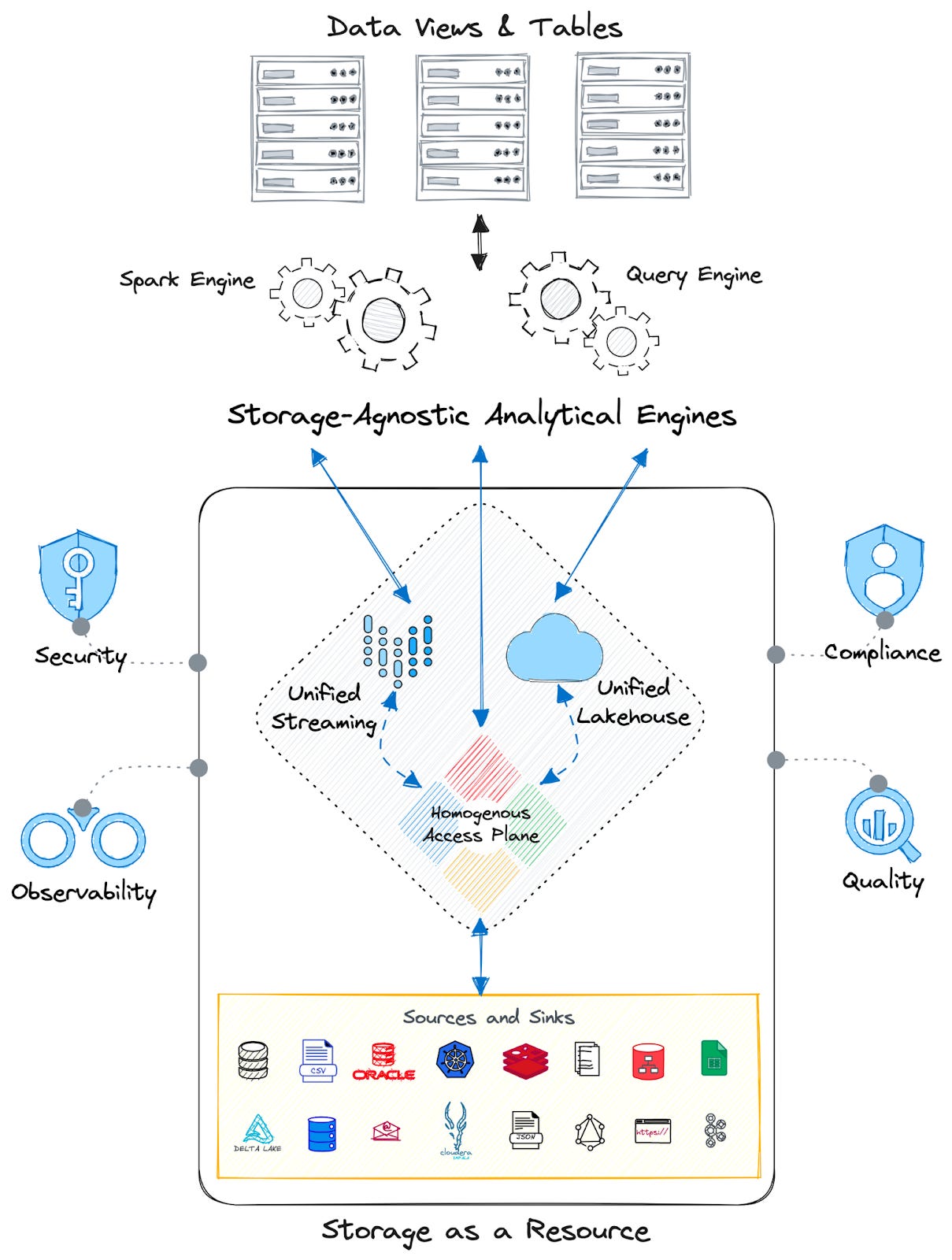
Instead of disparate data sources to maintain and process, imagine the simplicity if there was just one point of management. No complication while querying, transforming, or analysing because there’s only one standardised connection that needs to be established instead of multiple integrations, each with a different access pattern, philosophy, or optimisation requirement.
In prevalent storage systems, we deal with heterogeneous access ports with overwhelming pipelines, integration and access patterns, and optimisation requirements. Data is almost always moved (expensive) to common native storage to enable fundamental capabilities such as discoverability, governance, quality assessment, and analytics. And the movement is not a one-time task, given the rate of change of data across the original sources.
In contrast, Unified Storage brings in a homogenous access plane. Both native and external sources appear as part of one common storage - a single access point to querying, analysing, or transforming jobs. So even while the data sits at disparate sources, the user accesses it as if from one source with no data movement or duplication.
In prevalent systems, analytical engines are storage-dependent, and data needs to be optimised specifically for the engines or applications. Without optimisation, queries slow down to a gruelling pace, directly impacting analytical jobs and business decisions. Often, data is optimised for a single application or engine, which makes it challenging for other applications to consume that data.
In contrast, with the unification of storage as a resource, data is optimised for consumption across engines (SQL, Spark, etc.), enabling analytical engines to become storage-agnostic. For example, DataOS, which uses Unified Storage as an architectural building block, has two query engines - Minerva (static query engine) and Themis (elastic query engine), designed for two distinct purposes, and multiple data processing engines, including Spark. However, all the engines are able to interact with the Unified Storage optimally without any need for specific optimisation or special drivers and engines.
In prevalent data stacks, data is only partially discoverable within the bounds of the data source. Users have an obligation to navigate to specific sources or move data to a central location for universal discovery.
On the contrary, Unified Storage is able to present virtualised views of data across heterogeneous sources. Due to metadata extraction from each integrated source, native or external, users are able to design very specific queries and get results from across their data ecosystem. They can look for data products, tables, topics, views, and much more without moving or duplicating data.
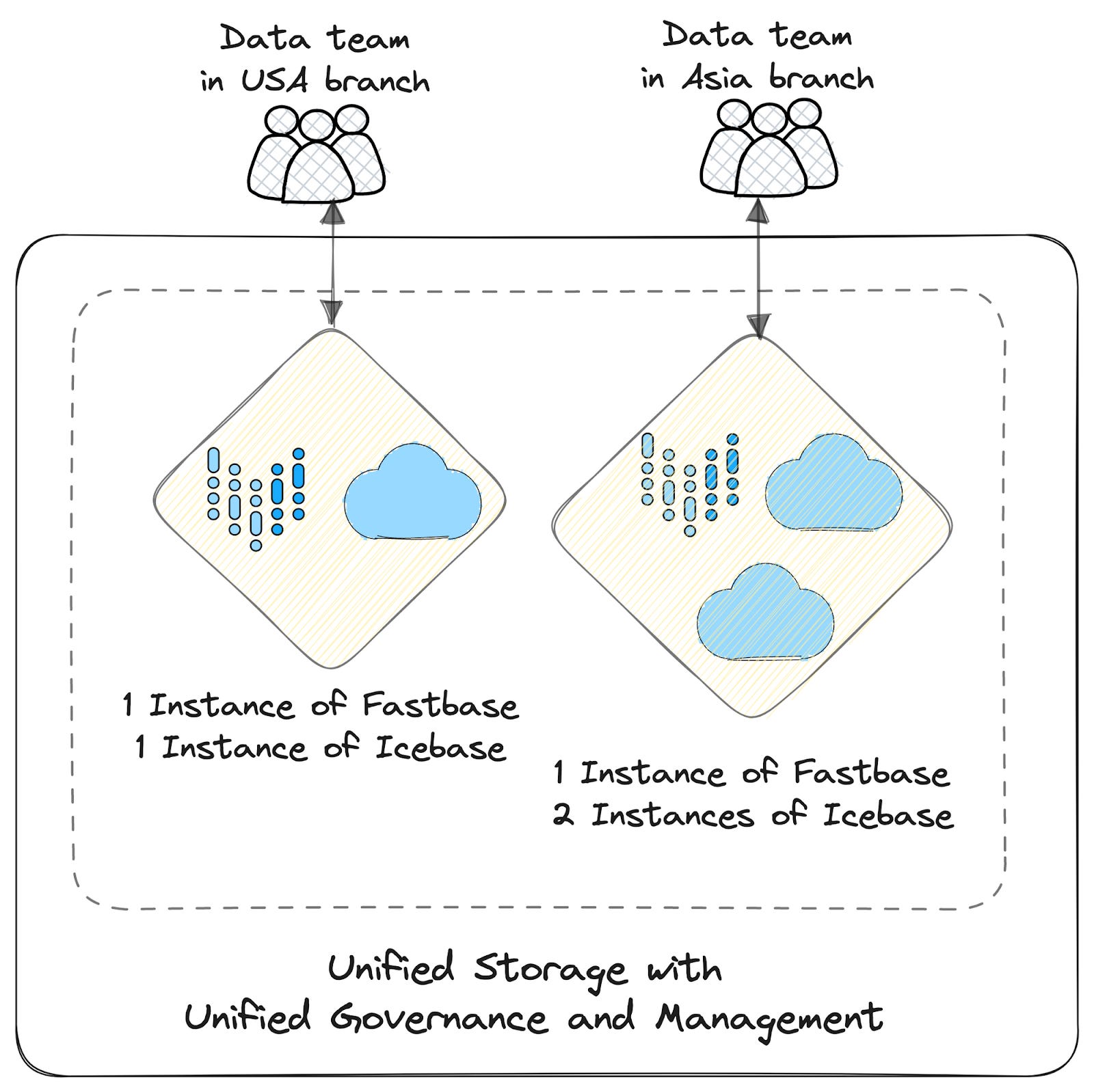
Most organisations, especially those at considerable scale, have the need to create multiple storage units, even natively, for separation of concerns, such as for different projects, locations, etc. This means building and maintaining storage from scratch for every new requirement. Over time, these separate units evolve into divergent patterns and philosophies.
Instead, with Unified Storage, users create modular instances of storage with separately provisioned infrastructure, policies, and quality checks- all under the hood of one common storage with a single point of management. Even large organisations would have one storage resource to master and maintain, severely cutting down the cognitive load. Each instance of storage does not require bottom-up build or maintenance, just a single spec input to spin it up over a pre-existing foundation.
In existing storage constructs, streaming is often considered a separate channel and comes with its own infrastructure and tooling. There is no leeway to consume stream data through a single unified channel. The user is required to integrate disparate streams and optimise them for consumption separately. Each production and consumption point must adhere to the specific tooling requirements.
Unified streaming allows direct connection and automated collection from any stream, simplifies transformation logic through standardised formats, and easily integrates historical or batch data with streams for analysis. An implementation of unified storage, such as Fastbase, supports Apache Pulsar format for streaming workloads. Pulsar offers a “unified messaging model” that combines the best features of traditional messaging systems like RabbitMQ and pub-sub (publish-subscribe) event streaming platforms like Apache Kafka.
We often see in existing data stacks how complex it is to govern data and data citizens on top of data management. This is because the current data stack is a giant web of countless tools and processes, and there is no way to infuse propagation of declarative governance and quality through such siloed systems. Let’s take a look at how a Unified Architecture approaches this.
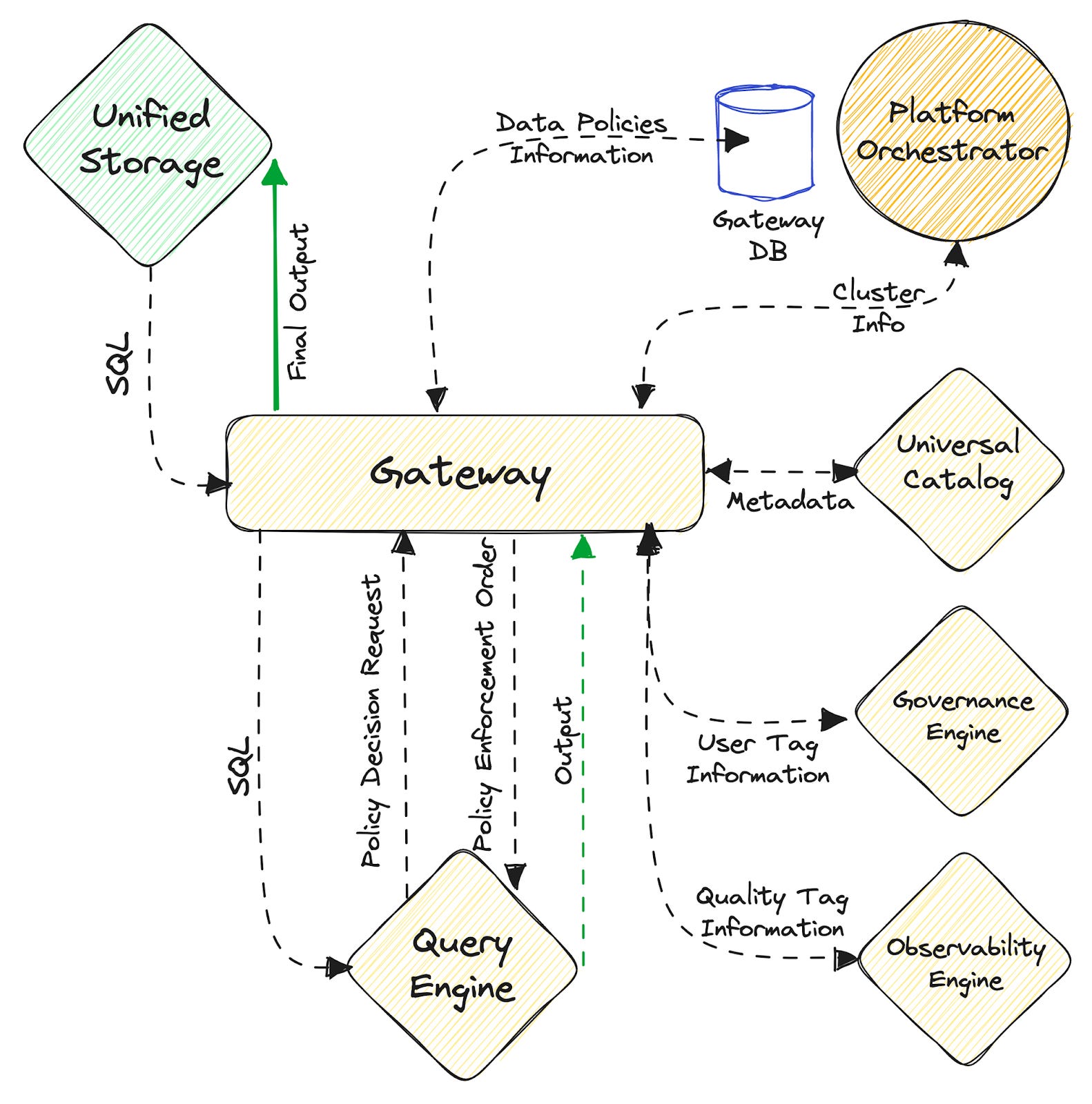
In existing storage paradigms, Governance is undoubtedly an afterthought. It is rolled out per source and is restricted to native points. Additionally, there is an overload of credentials to manage for disparate data sources. Siloed storage is also not programmed to work with standard semantic tags for governance. Both masking and access policies for users or machines must be applied in silos.
In contrast, Unified Storage comes with inherent governance, which is automatically embedded for data as soon as it’s composed into the unified storage resource, irrespective of native or external locations. Abstracted credential management allows users to “access once, access forever” until access is revoked. Universal semantic tags enforce policies across all data sources, native or external. Implementation of tags at one point (say, the catalog), propagates the tag across the entire data stack.
Much like Governance, Observability has also remained an afterthought, rolled out at the tail end of data management processes, most often as an optional capability. Moreover, observability too exists in silos, separately enabled for every source. Prevalent storage constructs have no embedded quality or hygiene checks which is a major challenge when data is managed at scale. If something faults, it eats up resources over an unnecessarily complex route to root cause analysis (RCA).
Unified storage has the ability to embed storage as an inherent feature due to high interoperability and metadata exposure from the storage resources and downstream access points such as analytical engines. Storage is no longer a siloed organ but right in the middle of the core spine, aware of transmissions across the data stack. This awareness is key to speedy RCA and, therefore, a better experience for both data producers and consumers.
Data Product is the smallest independent unit in the data architecture and encompasses infrastructure, all code in one place, and the data and metadata powered by the former two components.
The scope of this article doesn't cover why and how data products benefit both data producers and consumers, but the data product attributes speak for themselves: Discoverable, Universally Addressable, Natively Accessible, Trustworthy, Interoperable, Valuable on its own, and Secure. In summation, data products ensure high-quality, reliable data that are critical to the business.
Unified Storage catalyses the data product development experience by virtue of its embedded capabilities. Let’s look at a few data product vitals and see how unified storage as a resource helps enable those.
Data products are self-reliant and standalone units. This is because every data product has an isolated infrastructure. The ability to provision an instance of storage as an interoperable building block specifically for a data product vertical, therefore, becomes key to data product development. This ability also helps provision separate environments for dev, stg, or prod, with minimal cognitive load - a single change in a templatised spec file.
Data products are developed and used across various domains in the organisation. This implies their interaction with various different analytical and data-processing engines. If the data producer is required to publish data in a specific format and park in specialised storage engines to facilitate the use cases which other storage engines can’t process, there is a hard stop to democratisation. Data products are meant to serve several applications and use cases on a need basis; with limited access options, the data product’s purpose is hardly established.
A data product’s inherent nature is trustworthiness and quality. If data consumers can reliably use your data for analysis, AI/ML modeling, data sharing, or application development, the business saves tons of manhours and resources by vastly cutting down quality and access iterations. Unified storage comes with embedded governance and quality adherence, solving the storage aspect for data products. Be it policy propagation across disparate instances of storage and sources or observability metrics across these points, holistic views and insights are feasible due to the unification of storage as a resource.
The data product development process is infested with countless experiments. If data product developers move or duplicate data every time an experiment is spun up, experimentation itself would become an expensive and complex process. And every time an experiment fails, it has a tendency to corrupt physical data. High-performance teams run on seamless experimentation, which is enabled through virtualised views of unified storage. Data product developers build as many experiments as necessary without ever moving data from their original sources, putting in a hundred different credentials every time a source needs to be accessed, or letting their experiments impact the virtue of data.
*Originally published by the authors on Cloud Data Insights
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

.avif)


Animesh Kumar is the Co-Founder and Chief Technology Officer at The Modern Data Company, where he leads the design and development of DataOS, the company’s flagship data operating system. With over two decades in data engineering and platform development, he is also the founding curator of Modern Data 101, an independent community for data leaders and practitioners, and a contributor to the Data Developer Platform (DDP) specification, shaping how the industry approaches data products and platforms.

I am a passionate & pragmatic leader, architect & engineer. I use iterative architecture & lean methodologies to deliver software products with measurable value, aligned with goals & objectives, on time & with balanced technical debt.

Find more community resources

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.





