

Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

%20(1).png)
TABLE OF CONTENT



What is a Data Developer Platform (DDP)
Conceptual Philosophy of DDP
Outcome of a DDP
Fundamental Principles of a DDP
First Principles Design Approach
Implementing Your Own DDP
Moving to a Data Developer Platform (DDP) is not just another tooling shift or migration activity. While it is almost as simple as the former and not as challenging as the latter, the context of such a shift is entirely different.
Enabling a data developer platform is essentially a pivot in your data philosophy. Everything from how you approach and ingest data to how you understand and operationalise it undergoes a major transformation.
I’m glad to collaborate with Travis Thompson, the Chief Architect of the Data Operating System, on this piece. Travis has designed state-of-the-art architectures and solutions for top organisations, the likes of GAP, Iterative, MuleSoft, HP, and more. With over 30 years of experience in all things data and engineering, he is one expert you could spend hours listening to and learning from!
In this article, we have shared the philosophy of a Data Developer Platform and why it is an essential future-proofing kit in the rapidly changing technical landscape of data.
But first, boring introductions.
A Data Developer Platform can be thought of as an internal developer platform for data engineers and data scientists. Just as an internal developer platform provides a set of tools and services to help developers build and deploy applications more easily, a data developer platform provides a set of tools and services to help data professionals manage and analyze data more effectively.
An internal data platform typically includes tools for data integration, processing, storage, and analysis, as well as governance and security features to ensure that data is managed, compliant and secure. The platform may also provide a set of APIs and SDKs to enable developers to build custom applications and services on top of the platform.
In analogy to the internal developer platform, a data developer platform is designed to provide data professionals with a set of building blocks that they can use to build data products and services more quickly and efficiently. By providing a unified and standardised platform for managing data, an internal data platform can help organizations make better use of their data assets and drive business value.
This is where the DDP story finds its spark. A data developer platform’s philosophy is a direct parallel of the Operating System philosophy. Yes, the idea that literally changed the world by giving encapsulated technology into the hands of the masses.
While a gamer uses a Mac to run games, an accountant uses the same machine to process heavy Excel files. While a musician uses a phone to create complex media files, a grandparent uses it to video call the grandkids.
Same platform. Different use cases.
Same infrastructure. Variety of simple and complex solutions.
In all cases, neither of the users needs to understand the low-level technology or build their applications from scratch to start using the applications for their desired outcomes. But does that mean there’s no one on the other end figuring out the infrastructure complexities of the laptops, PCs, and phones?
There indeed is a very small (compared to the size of the user base) team behind infrastructure building and maintenance, and their job is to ensure all the users on the other side have a seamless experience without the need to get into the nitty-gritty. If the infrastructure is well-kept, users are abstracted from the pains of booting, maintaining, and running the low-level nuances of day-to-day applications that directly bring them value.
So is the case with a well-designed data developer platform. While smaller dedicated platform teams manage and regulate the infrastructure, larger teams of data developers are able to focus their time and effort on building data applications instead of worrying about plumbing issues. Applications across a broad range, including AI/ML, data sharing, and analytics, are all enabled at scale through the virtue of the same philosophy.
With a DDP in place, the data developer is essentially abstracted from all the low-lying details- all now delegated to the unified infrastructure of the DDP. The only job of the data developer now is to build and enable data applications that directly power business value. And while the infrastructure takes care of the resources, environments, provisioning, and supervisory activities, a small dedicated platform team ensures that the infra is healthy and ready to do its job.
A data developer platform is a flexible base and allows users to materialise desired solutions or a plethora of data design patterns on top of it. We will attempt to explain the flexibility through a concept that most of you might relate to: The Data Product construct.
The idea of “Data Products” holds significant deep-seated value since it enwraps key pillars of data robustness. Data products talk about eight features of data that make it worthy of consumption: Discoverable, Addressable, Understandable, Native accessible, Trustworthy, Interoperable, Valuable on its own, and Secure.
There are multiple ways to arrive at a data product depending on the organisation’s philosophy. One might choose to implement a data mesh pattern, while another might go for a data fabric. Some might discard either of the above to build a minimum viable pattern that works for their use cases.
A DDP inherently comes with a minimum viable pattern to enable the Data Product construct. Let's look at the definition of a data product. It is an architectural quantum with three components: The data & metadata, the code handling the data, and the infrastructure powering both components. A bare minimum DDP is the infrastructure component, while a higher-order DDP comes with minimalistic templates for the code. Plugging in data allows it to capture and embed metadata and eventually serve data that checks off the requirements of a data product.
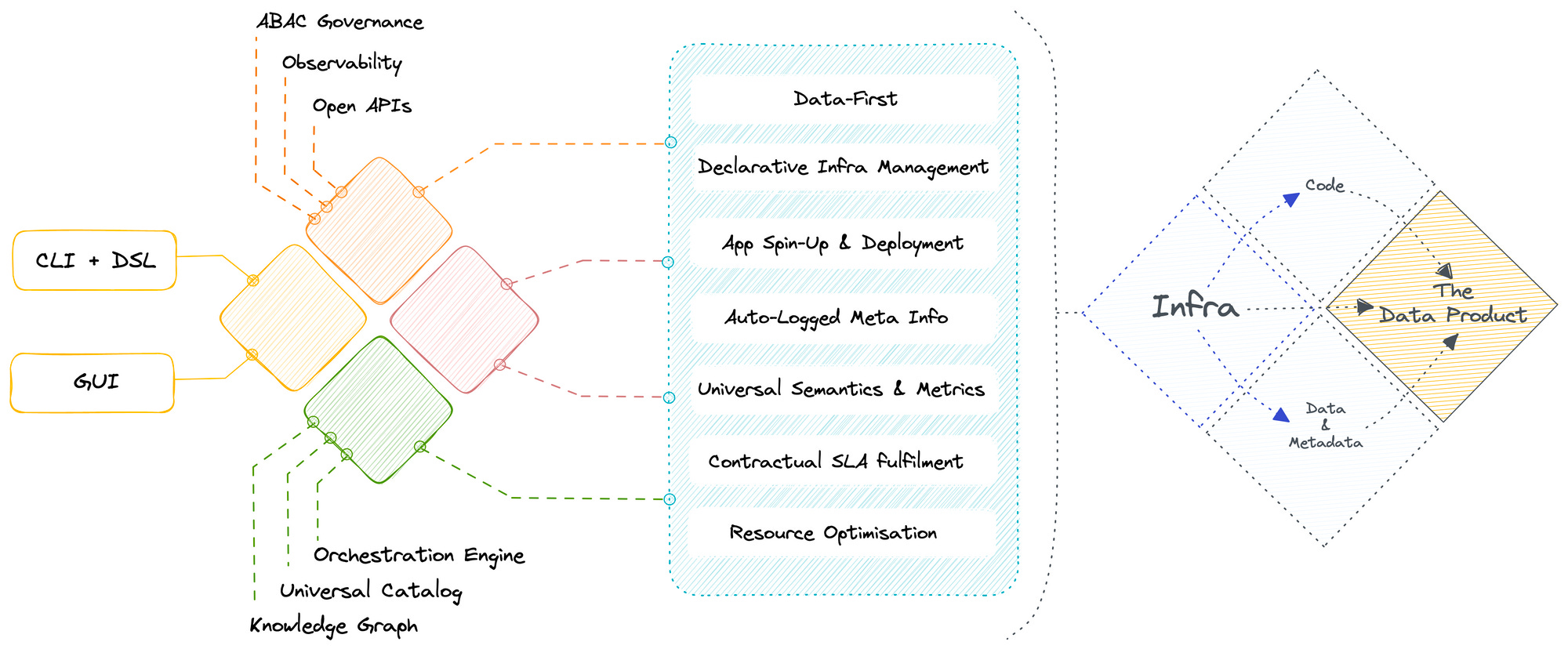
However, the story doesn’t end at that. Every organisation comes with its own approach to data, and it might so happen that they are not happy with the base pattern. The good news is they don’t have to start from scratch. Architects can easily build higher-order patterns on top of primitives, which are fundamental atomic non-negotiable units of any data stack, identified and embedded as part of a DDP with a unified architecture.
Once an architect or data engineer has access to low-level primitives, they can compose them together to manifest higher-order complex design patterns such as those of data mesh, data fabric, and even further higher-order patterns such as CDPs and customer 360s. All of which are designed and aimed at serving valuable data products when and where needed.
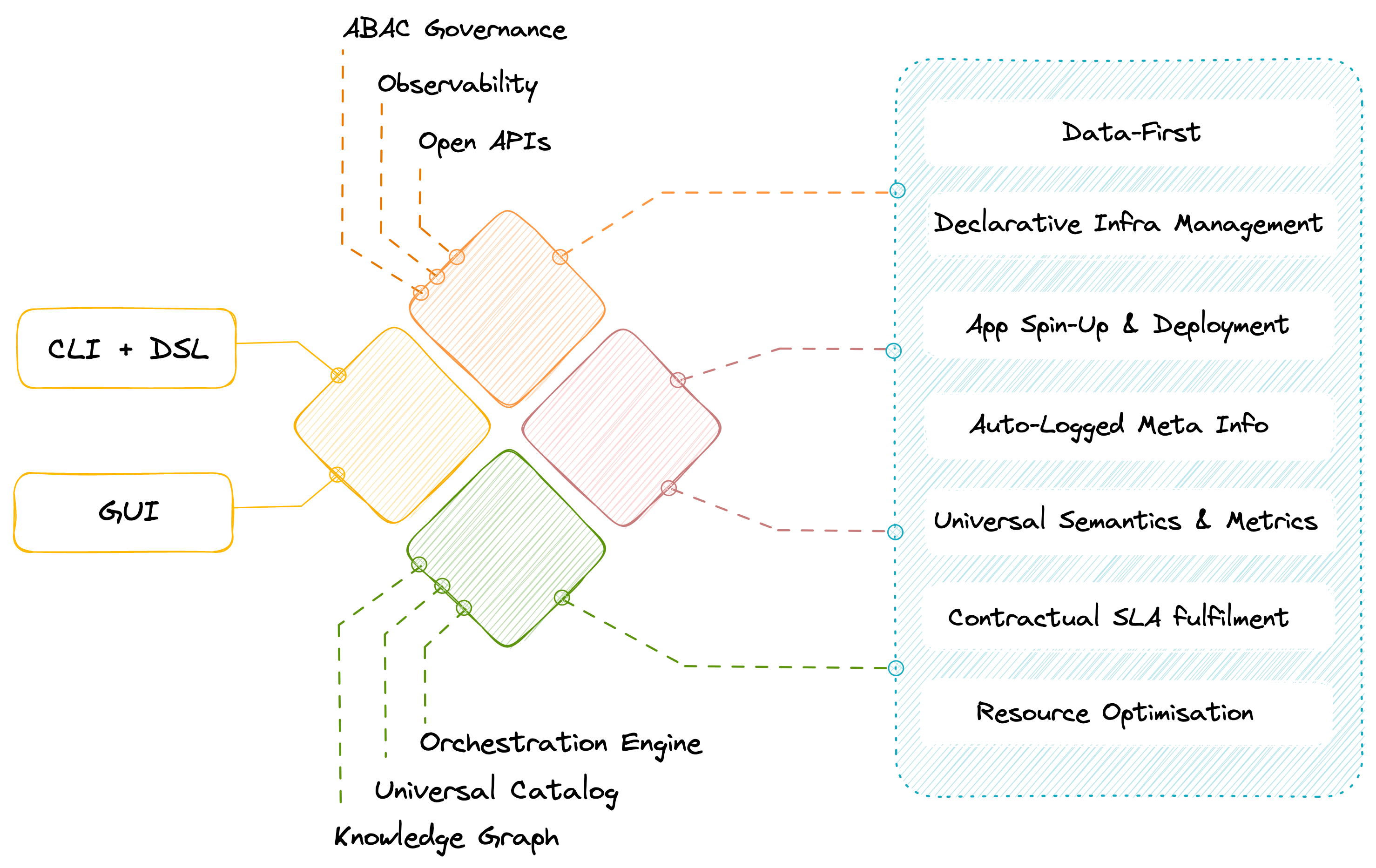
Data developer platforms can be designed in various ways. But a well-rounded platform is required to follow certain fundamental principles, without which the idea of DDP being the crux piece falls apart.
- Dynamic Configuration Management
- Infrastructure as Code
- SOTA Developer Experience
- Data-First instead of Maintenance-First
- Universal Semantics & Metrics
- Multi-Plane Experience
Let’s all agree change is the only constant, especially so in the data space. Declarative, single-point change management, therefore, becomes paramount to developer experience and pace of development and deployment. This goes by the name of dynamic configuration management and is established through workload-centric development. Lot of heavy words, but what do they mean?
Let’s look at the flow of DDP to applications at a very high level:
A business use case pops up → The domain user furnishes the data model for the use case or updates an existing one → The data engineer writes code to enable the data model → The data engineer writes configuration files for every resource and environment to provision infrastructure components such as storage and compute for the code.
In prevalent scenarios, swamps of config files are written, resulting in heavy configuration drifts and corrupted change management since the developer has to work across multiple touchpoints. This leads to more time spent on plumbing instead of simply opening the tap or enabling the data.
Dynamic configuration management solves this by distilling all points of change into one point. How is this possible? Through a low-lying infrastructure platform that composes all moving parts through a unified architecture. Such an architecture identifies fundamental atomic building blocks that are non-negotiables in a data stack. Let’s call them primitives.
Storage, compute, cluster, policy, service, and workflow are all examples of primitives. With these components packaged through infrastructure as code, developers can easily implement workload-centric development where they declaratively specify config requirements and the infrastructure is provisioned and deployed with respective resources at respective environments. Whenever a point of change arises, the developer makes the required change in the declarative specification to mirror the change across all dependent environments.
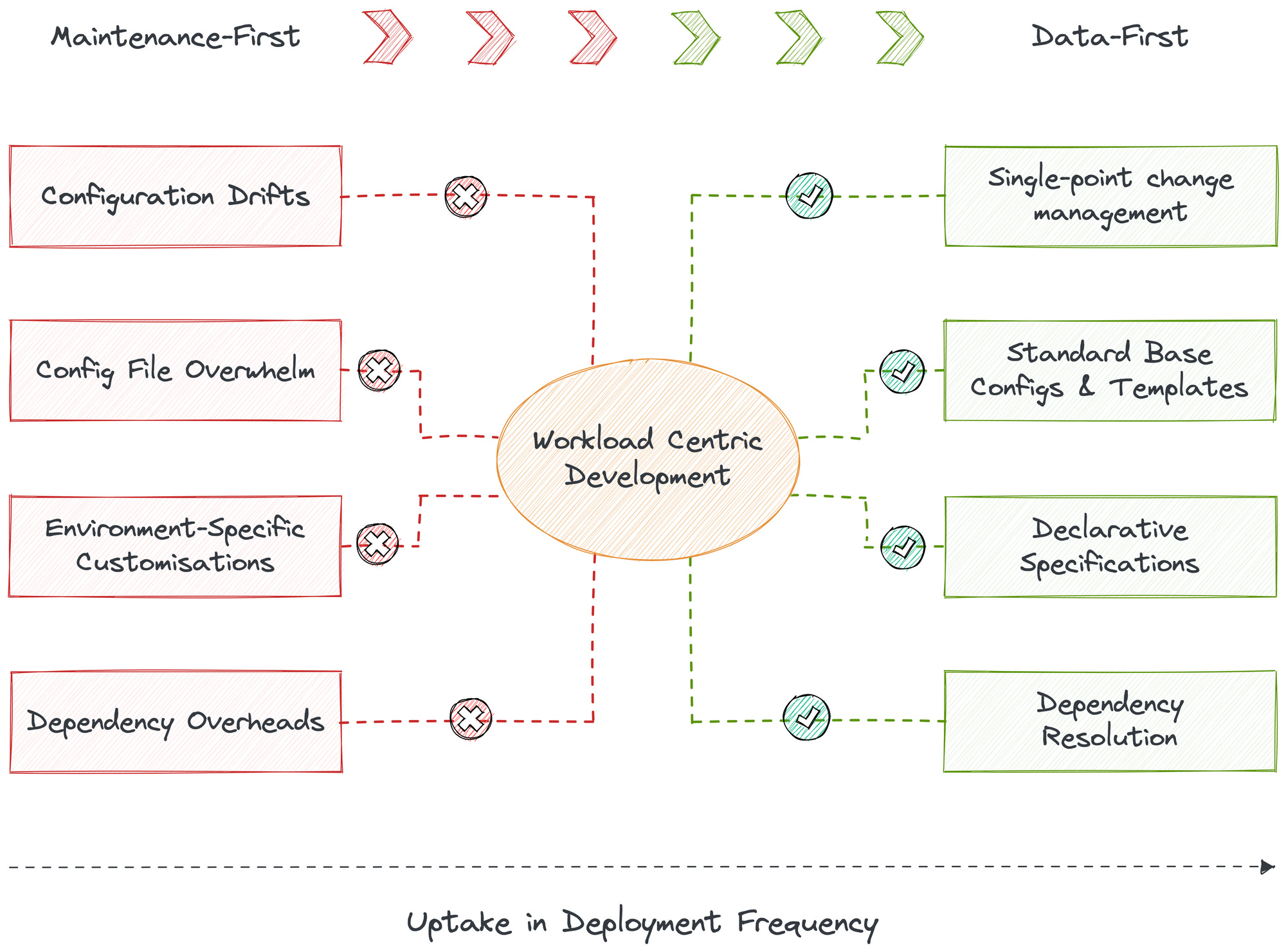
Workload-centric development enables data developers to quickly deploy workloads by eliminating configuration drifts and vast number of config files through standard base configurations that do not require environment-specific variables. The system auto-generates manifest files for apps, enabling CRUD ops, execution, and meta storage on top. Data developers can quickly spawn new applications and rapidly deploy them to multiple target environments or namespaces with configuration templates, abstracted credential management, and declarative and single workload specification.
The impact is instantly realised with a visible increase in deployment frequency.
We talked about infrastructure as code (IaC) in the above spiel. But what is it, and how does it benefit us? What makes IaC a critical enabler of the ideal DDP?
Infrastructure as code is the practice of building and managing infrastructure components as code. This leads to a significant impact by enabling programmatic access to data. Imagine the plethora of capabilities available at your fingertips by virtue of the OOP paradigm. IaC enables the higher-level construct of approaching data as software and wraps code systematically to enable object-oriented capabilities such as abstraction, encapsulation, modularity, inheritance, and polymorphism across all the components of the data stack. As an architectural quantum, the code becomes a part of the independent unit that is served as a Data Product.
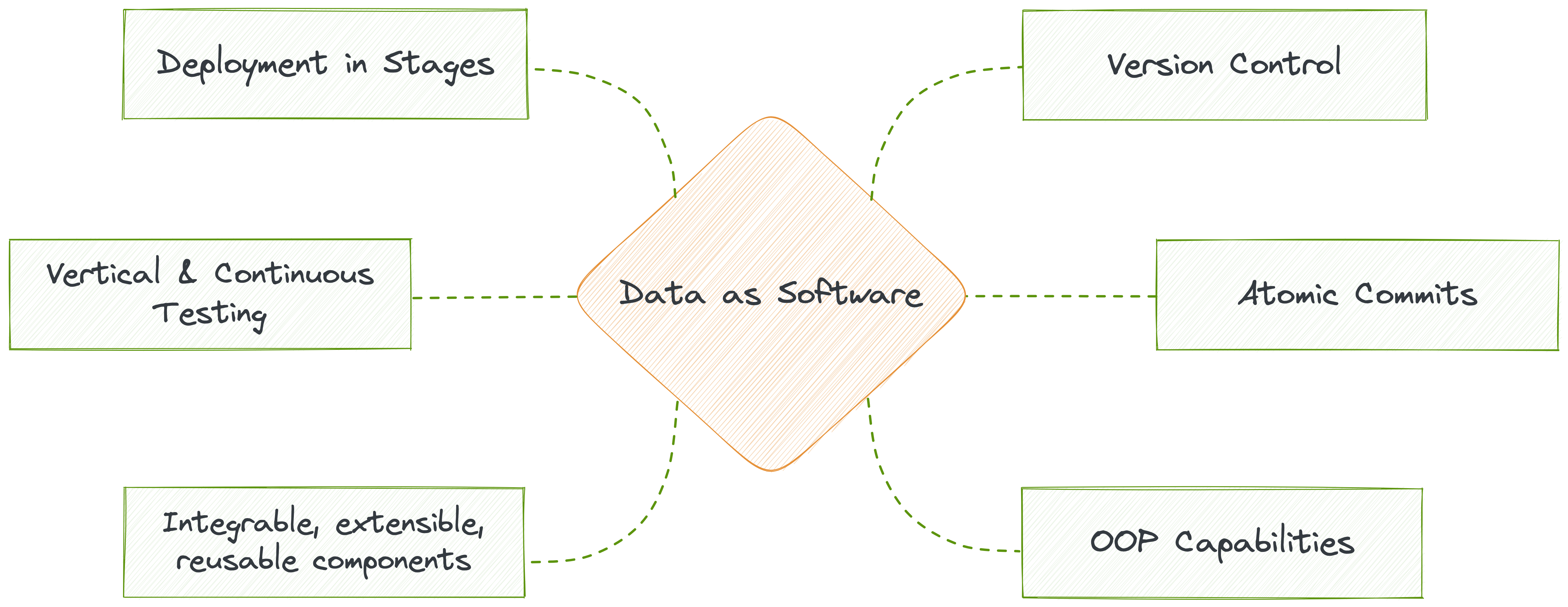
An ideal DDP implements infrastructure as code to manage and provision low-level components with state-of-the-art data developer experience. Data developers can customise high-level abstractions on a need basis, use lean CLI integrations they are familiar with, and overall experience software-like robustness through importable code, prompting interfaces with smart recommendations, and on-the-fly debugging capabilities.
CRUD ops on data and data artefacts, such as creation, deletion, and updates, follow the software development lifecycle undergoing review cycles, continuous testing, quality assurance, post-deployment monitoring and end-to-end observability. This enables the reusability and extensibility of infra artefacts and data assets, ultimately converging into all the qualities of the data product paradigm.
The programmable data platform encapsulates the low-level data infrastructure and enables data developers to shift from build mode to operate mode. DDP users can declaratively control data pipelines through a single workload specification or single-point management to create and deploy config files or new resources and decide how to provision, deploy, and manage them. For instance, provisioning RDS through IaC.
This approach consequently results in cruft (debt) depletion since data pipelines are declaratively managed with minimal manual intervention, allowing resource scaling, elasticity, and speed (TTROI). The infrastructure also fulfils higher-order operations such as data governance, observability, and metadata management based on declarative requirements.
Data Engineers are the victim of the current data ecosystem, and that is validated by a recent study which reports 97% of data engineers suffering from burnout. The prevalent data stacks compel data engineers to work repeatedly on fixing fragile fragments of countless data pipelines spawned at the rate of business queries.
DDP enables a seamless experience for data developers by abstracting away repetitive and complex maintenance and integration overheads while allowing familiar CLI interfaces to programmatically speak to qualified data and build applications that directly impact business decisions and ROI. Data developer experience is also significantly improved through the standardisation of key elements such as semantics, metrics, ontology, and taxonomy through consistent template prompts. All operations and meta details are auto-logged by the system to reduce process overheads.
Moreover, It is no secret that developers love to innovate and experiment. However, the cost of innovation has not always been in their favour, especially in the data space, which subsumes huge resources. But freedom to innovate fast and fail fast is the enabler of high-ROI teams. A well-designed DDP takes the heat of innovation and saves time spent on experimentation through smart capabilities.
Some of these include intelligent data movement, semantic playgrounds, rollback abilities across pipelines and data assets, and declarative transformations where users can specify the inputs and outputs. DDP will automatically generate the necessary code to run the experiments. Data developers can declaratively prep, deploy, and de-provision clusters, provision databases and sidecar proxies, and manage secrets for lifetime with one-time credential updates- all through the simple and common syntax of DSL.
The Data-First Stack (DFS) is a milestone innovation that is inspired by the data-first movement undertaken by a couple of data-first organizations such as Uber, Google, and Airbnb over the last decade. But what does data-first mean?
Data-first, as the name suggests, is putting data and data-powered decisions first while de-prioritizing everything else either through abstractions or intelligent design architectures. It would be easier to understand this if we look at it from the opposite direction - “data-last”.
Current practices, including MDS, is an implementation of “data-last” where massive efforts, resources, and time are spent on managing, processing, and maintaining data infrastructures and pipelines. Data and data applications are literally lost in this translation and have become the last focus points for data-centric teams, creating extremely challenging business minefields for data producers and data consumers.
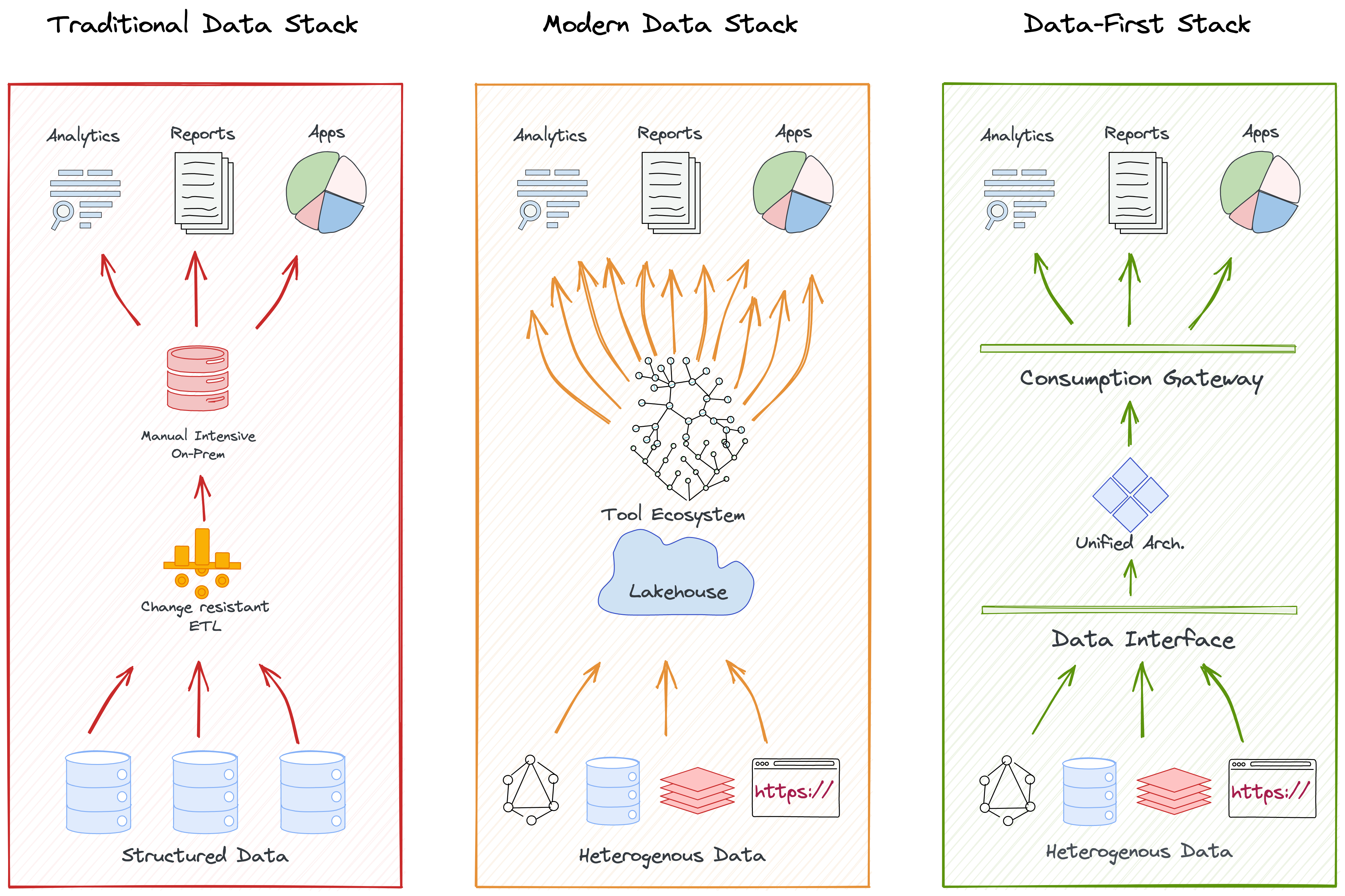
Today, businesses that have a good grasp of data make the difference between winning and losing the competitive edge. Many data-first organizations understood this long back and dedicated major projects to become data-first. However, replicating them is not the solution since their data stacks were catered to their specific internal architectures.
🔑 A data-first stack is only truly data-first if it is built in accordance with your internal infrastructure.
Contrary to the widespread mindset that it takes years to build a data-first stack, this no longer holds true with a DDP in place. It is not impossible to build a data-first stack and reap value from it within weeks instead of months and years.
Becoming data-first within weeks is possible through the high internal quality of a unified DDP architecture: Unification through Modularisation. Modularisation is possible through Infrastructure as Code that wraps around the finite set of primitives that have been uniquely identified as essential to the data ecosystem.’
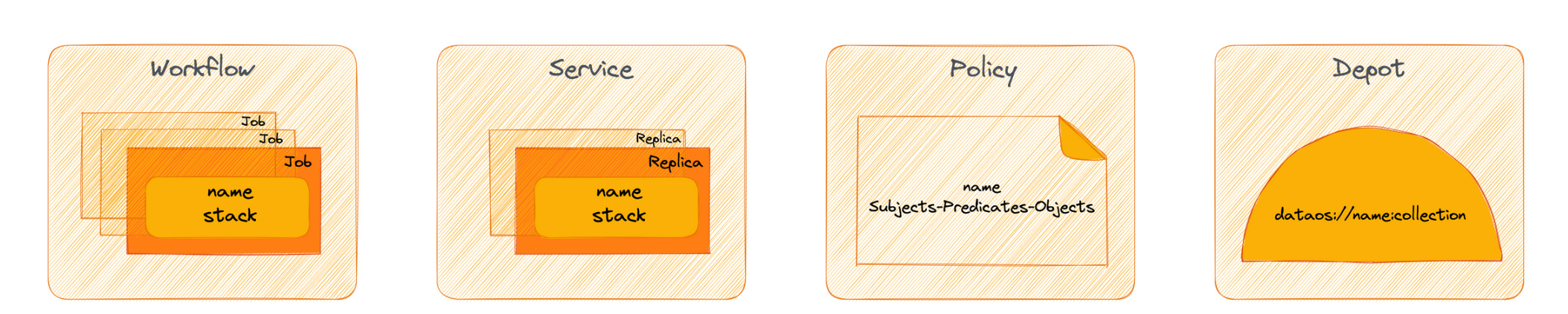

The DDP, technically defined, is a finite set of unique primitives (atomic and logical units with their own life cycle) that talk to each other to declaratively enable any and every operation that data users, generators, or operators require. Like a common set of core building blocks or lego pieces that can be put together to construct anything, be it a house, a car, or any object. DDP core primitives can similarly be put together to construct or deconstruct any data application that helps data developers serve and improve actual business value instead of wasting their time and efforts on managing the complex processes behind those outcomes.
There are multiple teams in an organisation, each dealing with their own share of data alongside cross-referencing data from other teams frequently to get more context for their data. This leads to a big jumble of random words and jargon thrown at each other. Exactly how two tribes with different languages would interact with each other. They might mean the same thing, but both are frustrated because they don’t understand they mean the same thing.
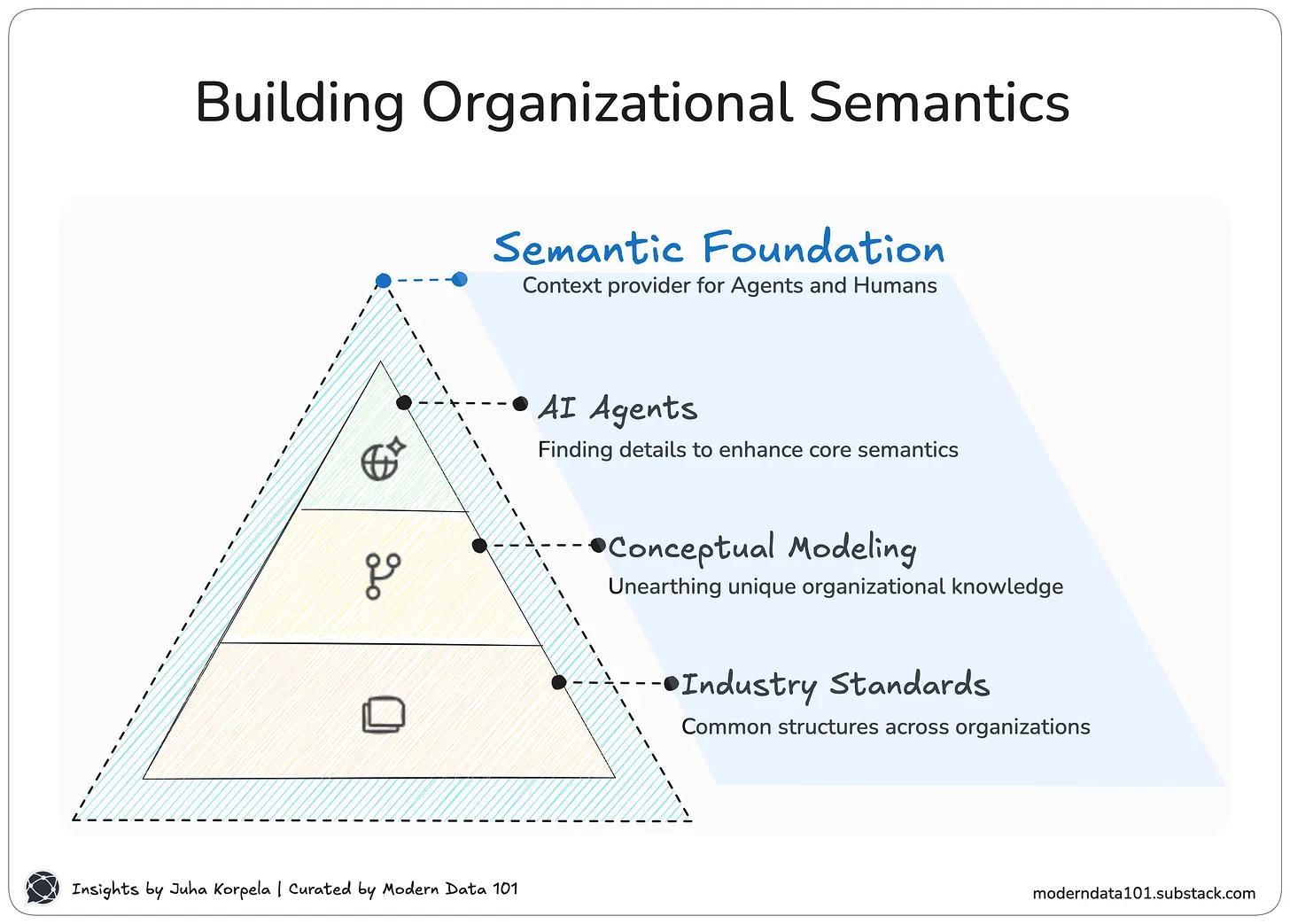
Semantics means the meaning and context behind data. It could be something as simple as a column name or even an elaborate description or equation. Given there are so many teams and domains, each with its standard way of defining the same data, it becomes extremely difficult to have a unified meaning for the data. This leads to semantic untrustworthiness that leads to multiple iterations between teams to understand and verify the meaning that has been described.
Semantic untrustworthiness also stems from a chaotic clutter of MDS, overwhelmed with tools, integrations, and unstable pipelines. Another level of semantics is required to understand the low-level semantics, complicating the problem further.
A DDP solves this problem since the low-level layers are powered through a unified architecture. Irrespective of disparate domains and distributed teams in the above layers, all logic, definitions, ontologies, and taxonomies defined across multiple layers and verticals plugs into a common business glossary that is embedded with the ability to accommodate synonymous jargon and diverging meanings.
The platform connects to all data source systems, resources, environments, and hierarchical business layers allowing data producers to augment the glossary with business semantics to make data products addressable. This holds true even for metrics that are similar to the semantic meaning. So now, when a marketing guy refers to, say, the business development team’s data, they don’t have to struggle with understanding new jargon, tallying columns, or iterating with the analysts to understand what the data means. Every time the data changes, they wouldn’t need to repeat the process either. Simply put, the amount of time and effort saved here is tremendous.
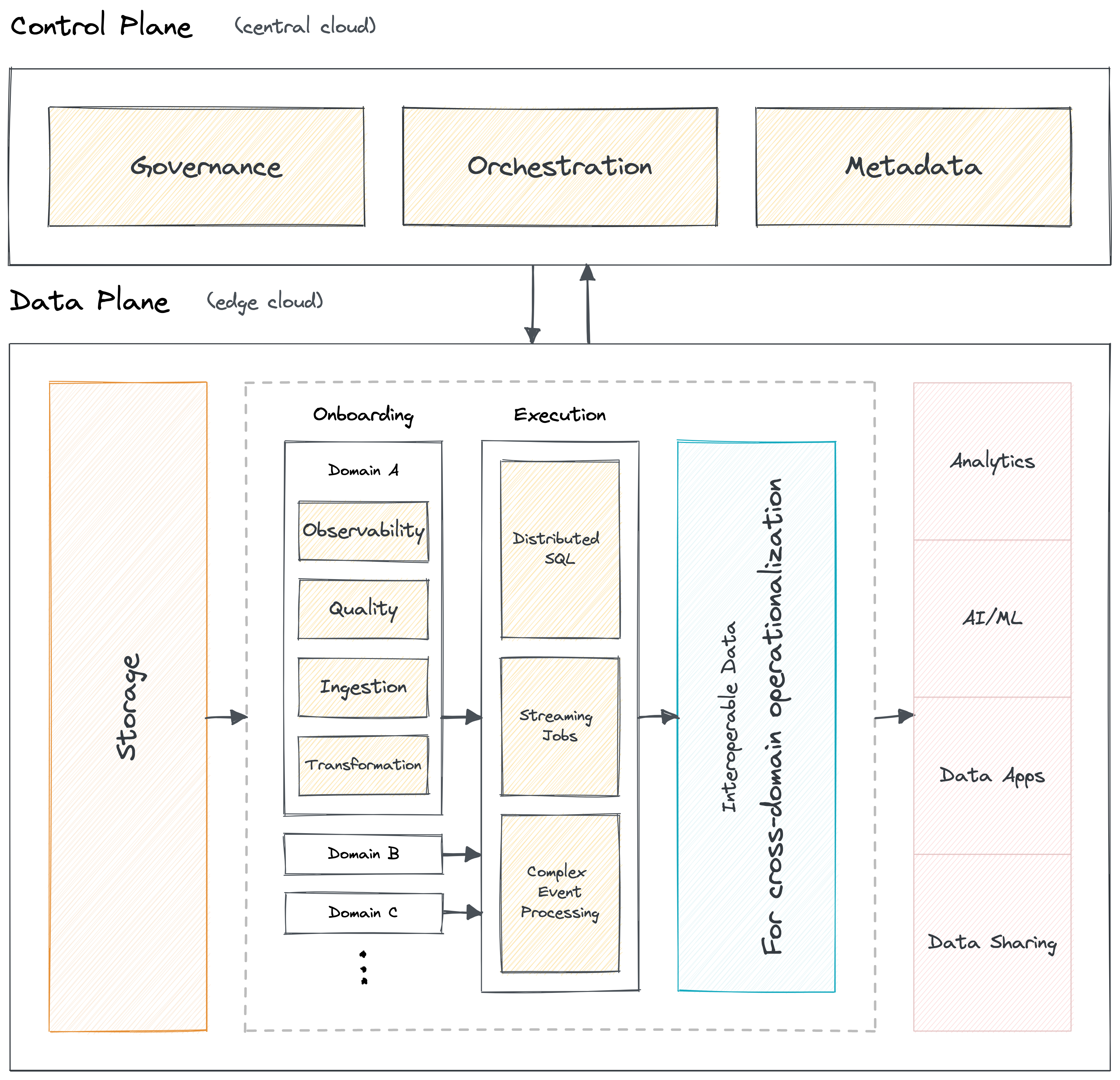
A DDP enables the flexibility to develop and enable any design architecture on top of it, as we discussed in a previous section. One such design is the ability to create the experience of multiple data planes. Why is a multi-plane experience important? Ability to decouple.
Our own philosophy includes two simple planes: The Control Plane and the Data Plane. Control & Data plane separation decouples the governance and execution of data applications. This gives the flexibility to run the platform for data in a hybrid environment and deploy a multi-tenant data architecture. Organizations can manage cloud storage and compute instances with a centralised control plane.
While the control plane cuts across all verticals and helps admins govern the data ecosystem through centralised management, a data plane helps data developers to deploy, manage and scale data products across individual verticals.
Given that we both have a couple of white strands, we have seen the rise and fall of countless technologies in the Data Space, especially during the last few years. This is why we stress the importance of a Data Developer Platform that can weather the storm of rapid changes in the field.
It is critical to, however, note that randomly installing a DDP is not THE solution that would suddenly fix all problems. It is critical to note how the DDP has been developed, the philosophy behind its build, how it works with prevalent business use cases, and how it enables your day-to-day tech stack.
Why do systems work so well in Hierarchies? I came across a brief fable in Thinking in Systems by Donella H. Meadows. Here’s a brief summary:
Hora and Tempus were two fine watchmakers with a long list of customers. But surprisingly, over the years, Hora became richer while Tempus became poorer. Hora had discovered the principle of hierarchy, while Tempus was ignorant of it.
The watches made by both consisted of about one thousand parts each.
Tempus put these parts together in such a way that if he had one partly assembled and had to put it down, say to answer the phone, it fell to pieces. He had to start all over again. Ironically, the more customer calls he had, the poorer he became.
Hora’s watches were no less complex than those of Tempus,
— But he put together stable subassemblies of about ten elements each.
—— Then he put ten of these subassemblies together into a larger assembly;
——— And ten of those assemblies constituted the whole watch.
Whenever Hora had to put down a partly completed watch to answer the phone, he lost only a small part of his work. So he thrived with more customers and more interruptions.
“Complex subsystems can evolve from simple systems only if there are stable intermediate forms. That may explain why hierarchies are so common in the systems nature presents to us among all possible complex forms. They reduce the amount of information that any part of the system has to keep track of.”
Even Amazon identified this necessary hierarchical pivot right before AWS became the Operating System for Developers to build applications. We can get a clear picture of that from a published interview with one of the core members of AWS.
“If you believe developers will build applications from scratch using web services as primitive building blocks, then the operating system becomes the Internet,” says Jassy (AWS Leader and SVP) — an approach to development that had not yet been considered. Amazon asked itself what the key components of that operating system would be, what already existed, and what Amazon could contribute.”
How about considering a pivot for the Data Landscape in the same spirit?
A well-rounded DDP is a cushion for trends. It was not long ago when data fabric was taking the world by storm, while today, most conversations are inlining toward the data mesh. Tomorrow, there might be a new data design architecture that CTOs and CFOs fancy. The harsh reality is no one data design architecture is non-disruptive or simple to implement. It takes dedicated time, effort, and investment.
Does this mean that every time a new holy grail is discovered, the entire stack needs to be ripped off and expended? Not if you have a DDP in place. Let’s say the DDP is the decryptor of all the complex scriptures in the holy grail. You place the cup in the socket, and the hall lights up.
A DDP developed after the core principles provides a set of primitives that the architect can compose together in any arrangement to enable higher-order complex design patterns. The primitives in the DDP are uniquely identified as non-negotiable atomic units of any data stack.
What’s more is, due to workload-centric development capabilities, this process becomes almost declarative, saving tons of resources, time, and money.
Implementing a DDP is not a challenge. Creating and establishing it as per the core principles is. It took us close to two years to establish our own flavour of the DDP, which goes by the name of DataOS or the Data Operating System.
While DataOS was our primary point of focus, given it is our flagship, a DDP is often not the core expertise or focus area for organisations in other domains. However, it stands true that every data-driven organisation or vertical benefits from the DDP construct, and it is always a strategic decision to either implement your native product or source a plug a pre-existing one.
However, a word of advice would be to always be careful about the choice of DDP while sourcing externally. It should never be another vendor lock-in trap or fluffy collection of tools that potentially breaks all the core principles of a true DDP. It is essential to always ensure freedom for your data and the ability to de-plug whenever necessary without a ton of disruption.
The ideal process would be to either have your own dedicated platform development team to build a native DDP or at least one subject matter expert who can analyse and provide a thorough breakdown of the credibility of externally sourced DDPs.
Since its inception, ModernData101 has garnered a select group of Data Leaders and Practitioners among its readership. We’d love to welcome more experts in the field to share their story here and connect with more folks building for better. If you have a story to tell, feel free to email your title and a brief synopsis to the Editor.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

.avif)


Animesh Kumar is the Co-Founder and Chief Technology Officer at The Modern Data Company, where he leads the design and development of DataOS, the company’s flagship data operating system. With over two decades in data engineering and platform development, he is also the founding curator of Modern Data 101, an independent community for data leaders and practitioners, and a contributor to the Data Developer Platform (DDP) specification, shaping how the industry approaches data products and platforms.

I am a passionate & pragmatic leader, architect & engineer. I use iterative architecture & lean methodologies to deliver software products with measurable value, aligned with goals & objectives, on time & with balanced technical debt.

Find more community resources

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.






