



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...
.png)

.png)

.png)

TABLE OF CONTENT




Interoperability is a necessity across different features of a data stack, such as cataloging, modeling, ingesting, governance, and more. This article is a straightforward piece specifically looking into the Governance angle and how interoperability weaves into it as a non-negotiable enabler.
But first, we need to take a brief detour to understand the essence of interoperability.
Interoperability is the ability of different entities in the data stack (platforms, tools, pipelines, policies, etc.) to understand each other and communicate and behave as if they were part of one system instead of acting as multiple systems requiring assistance to talk to foreign entities.
Interoperability reduces the cognitive overload of integration overheads and allows developers to have a unified experience, irrespective of the number of different systems in operation.
Becoming end-to-end interoperable is feasible with a unifying centerpiece that furnishes a common interface to enable any entity in a data stack to talk directly to any other entity without repetitive integration with each. This function is facilitated by data developer platforms.
Any data developer platform’s objective is to facilitate existing tools in the data infrastructure, add new platform-native capabilities, and facilitate standard interfaces for the new and existing entities to talk to each other. This omits integration, maintenance, and expertise overheads.
Consequently, interoperability plays a big role here by enabling the data platform to understand and derive context around existing data infrastructure. An interoperable data platform is able to integrate with existing infrastructure by interoperating with:
1. The data developer platform triggers events in entities outside the platform, say, pre-existing tools in the data stack.- One-Integration to Integrate with All: The platform furnishes a standard way/interface to share information with external entities. E.g.: Once an operator (channel) to an external tool is developed, any entity in the data platform (workflows, computes, services, contracts, etc.) and any other external entity integrated with the platform can interact with the tool without requiring repetitive integration with the tool.
2. Data developers can create, deploy, manage, and monitor the resources of external data entities (say, monitoring or cataloging tools) from within the data platform.
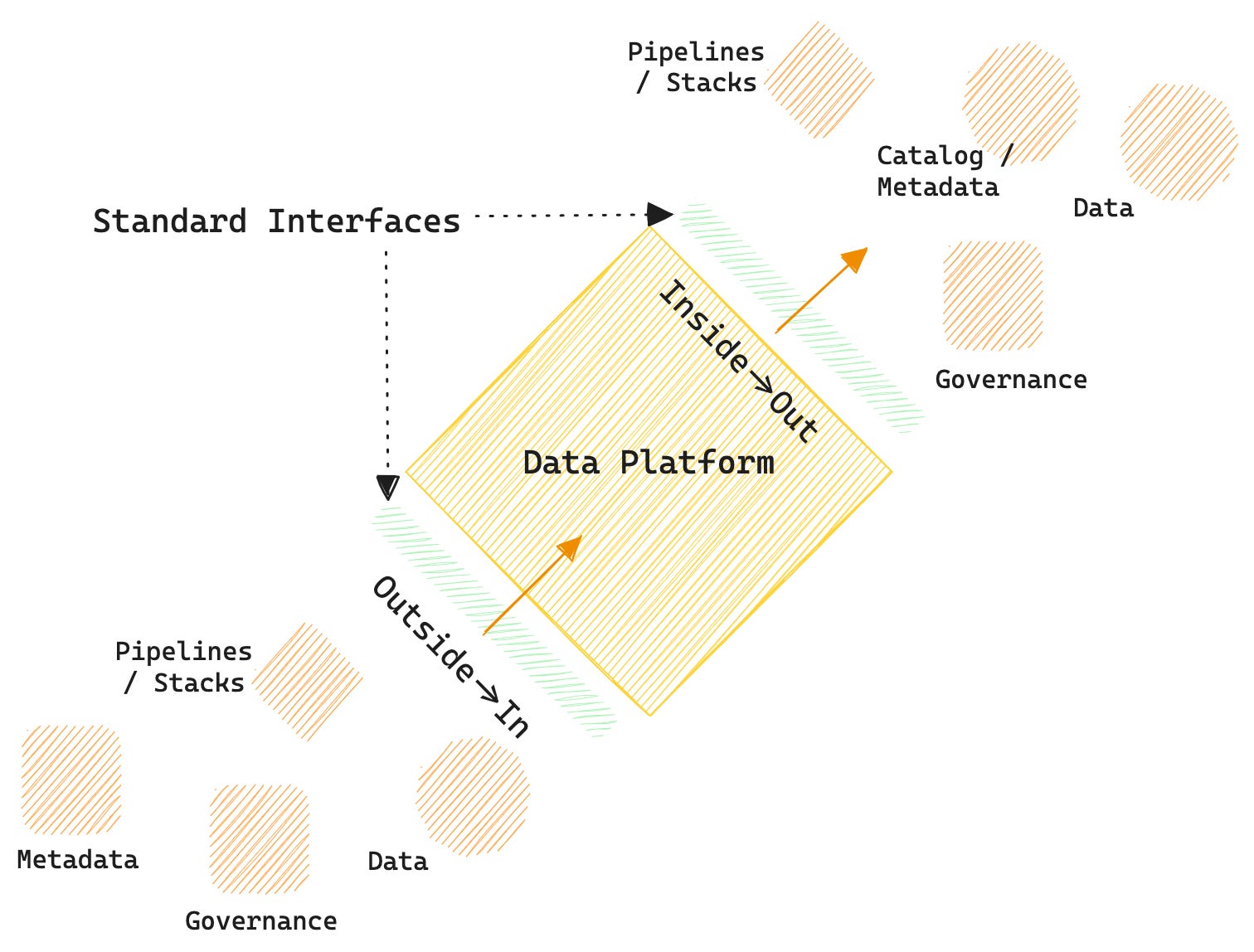
1. A standard way to consume information from external entities.
2. When a data platform is able to ingest and act on event triggers from outside the platform.
3. The platform furnishes standardised APIs that are compatible with external formats (events, data, instructions).
4. Data developers can invoke the data developer platform’s resources from outside the platform via event triggers.
Before mapping the power of interoperability with data governance, we need to first understand how Governance is implemented across the end-to-end data ecosystem through a unifying data platform.
Below is a sequence diagram explaining the flow of how access or data masking policies get implemented in a use case such as querying.
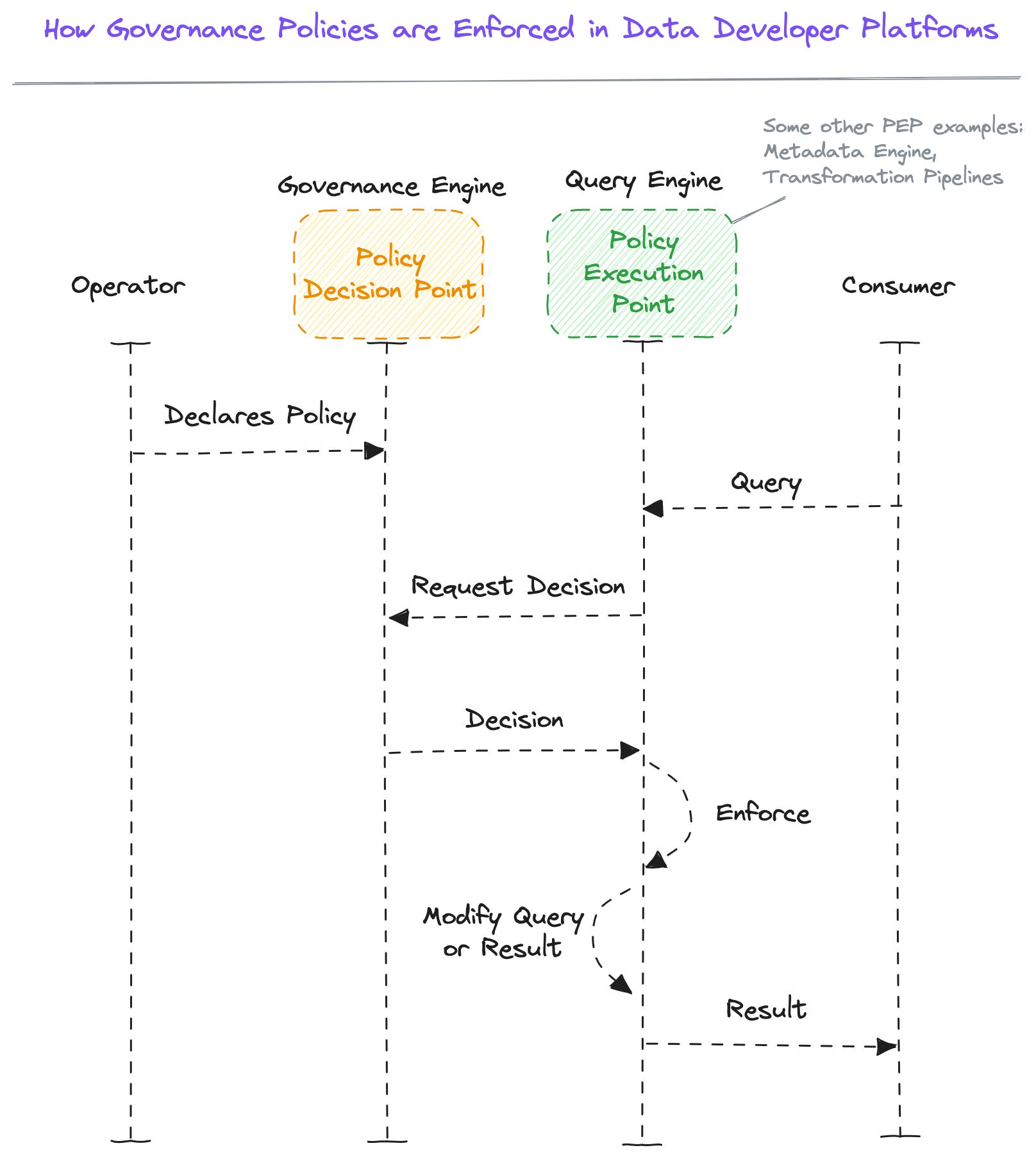
The data developer platform’s native data governance engine implements ABAC by acting as a PDP or a Policy Decision Point and transmitting decisions to PEPs or Policy Execution Points.
💡 A PDP or a Policy Decision point is where the system decides the course of action with respect to a policy. It is the central and only point of authority for any and all governance across the data ecosystem. A data ecosystem cannot have more than one PDP.
💡 A PEP or a Policy Execution Point is where the policy is implemented. A PEP can exist both internally as well as externally in the context of the data platform. There can be multiple PEPs operating in the data ecosystem based on whichever app, engine, resource, or interface wants to implement certain policies.
Any entity that wants to implement policies must first implement a PEP compatible with the chosen PDP. The platform’s native governance engine provides APIs for PDP, which can be leveraged by data app developers as a standalone governance engine as long as they implement PEPs in their apps.
Whenever a query or an application calls data or any other resource via a query engine or an API, the PEP sends a decision request to the governance engine (PDP), and based on the policy registered, the PDP sends out a decision.
The PEP is free to enforce the decision and consequently modify the query or the result as necessary to align with the policy decision. Example: mask or encrypt certain columns.
To enable governance for your entire data ecosystem, that is, across all internal and external resources and stacks, in an inside→out fashion, you need to opt for the data platform’s PDP.
All resources, interfaces, and engines native to the data platform inherently implement PEPs compatible with its governance engine. For external entities, the data developers need to implement compatible PEPs across the points they want to govern.
If customers already have a pre-existing governance tool, say Immuta, the default chosen PDP is the governance engine of Immuta. But there can only be one PDP. Therefore, the platform’s native governance engine does not play any role here.
If the data developers want to use the applications and interfaces of the data developer platform in a governed fashion based on the policies defined by Immuta’s PDP, the platform engineers need to make sure the internal entities such as the platform’s query engine, transformation stacks, and all-purpose catalog are able to implement PEPs which are compatible with the external PDP.
It’s important to understand why it’s necessary to have no more than one PDP for the entire ecosystem. As soon as you introduce two PDPs or two points of authority, you suffer the consequences of conflicting policies, which derails the integrity of the whole governance system.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



