

Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

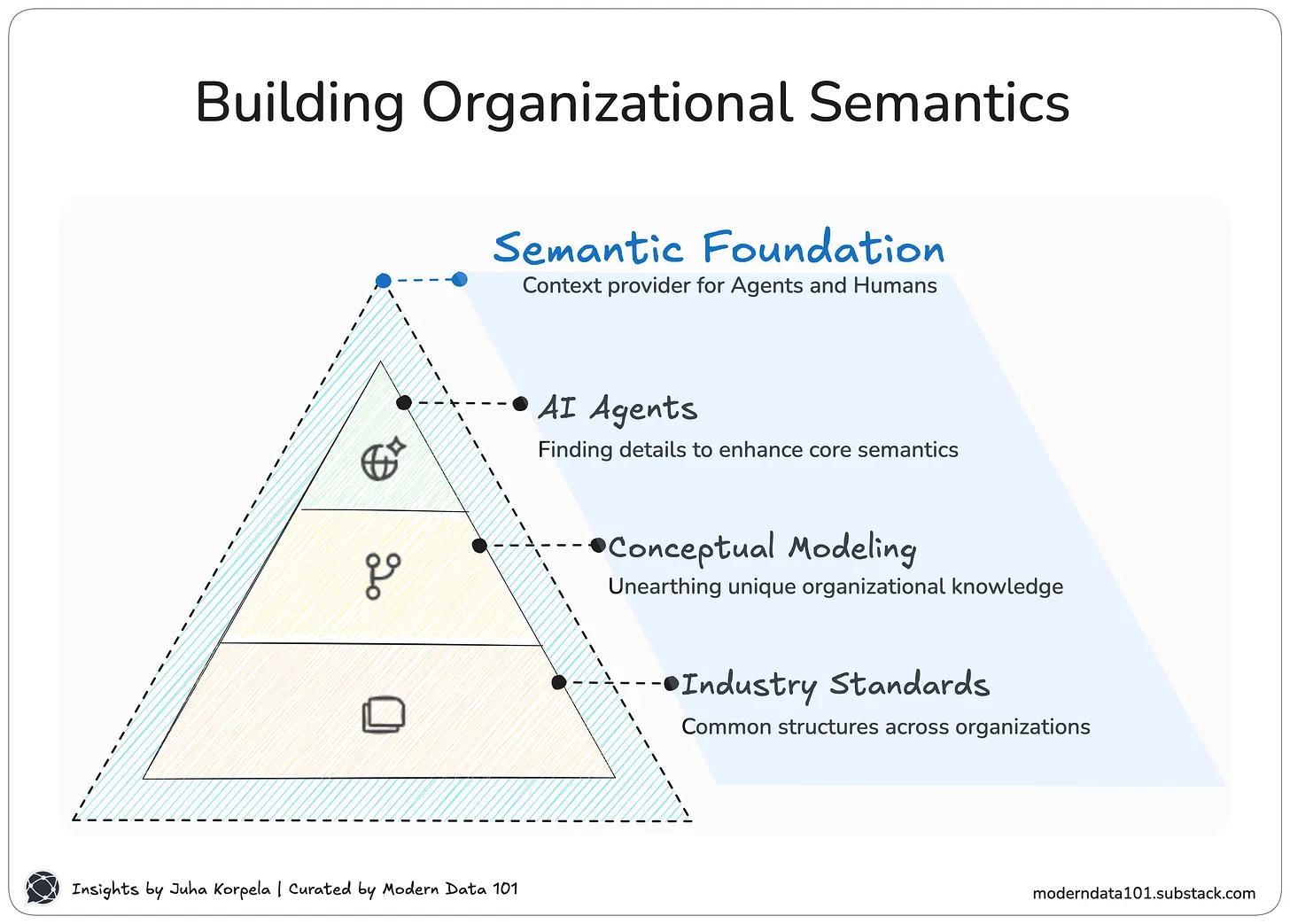
TABLE OF CONTENT



The data value chain has been fairly well-known over the years, especially since data was used at scale for commercial projects. The inception of the data value chain was to tackle data bias, a subset of data quality. And as we all know, even to achieve the singular objective of data quality, there are the whole nine yards of processes, tooling, and data personas involved. A data value chain strives to enable useful data with a unique combination of all three.
“Strives” would be the key word to note here because “valuable data” or the data product paradigm still seems like a distant dream, and I’m afraid it’s not just my sole opinion. I’ve had the opportunity to speak to a handful of folks from the data and analytics domain and found unanimous agreement that even data design architectures such as data meshes or data fabrics are essentially theoretical paradigms and, at the moment, lack clear implementation passages to practically enable data products quickly and at scale.
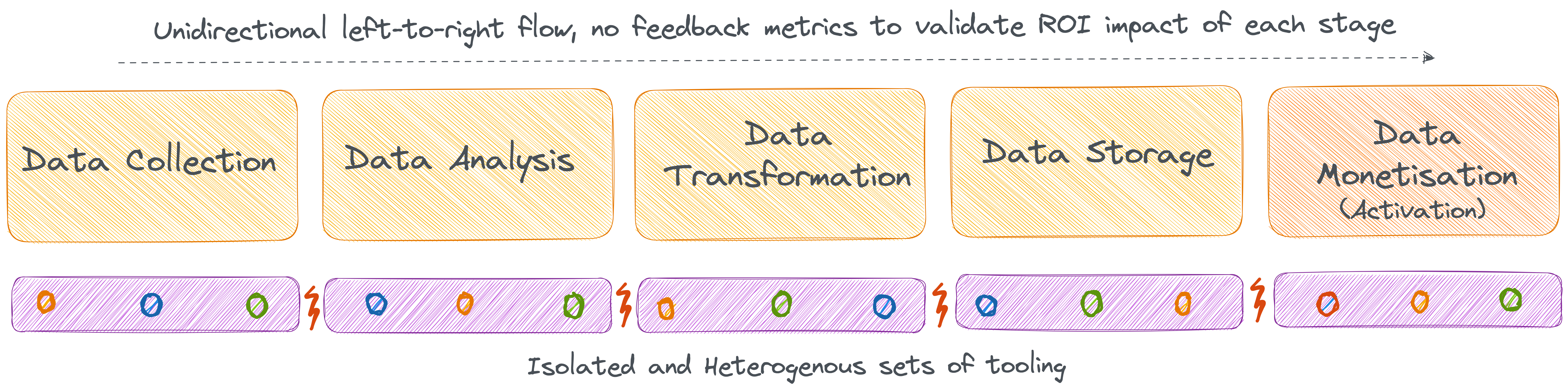
While the data value chain clearly demarcates the stages of the data journey, the problem lies in how data teams are compelled to solve each stage with a plethora of tooling and integration dependencies that isolate each stage, directly impacting ties with the business ROI.
To clearly understand how to re-engineer the data value chain and resolve persistent issues, let’s first take a look at the data value chain itself. In this piece, my objective is not to dive deep into individual stages. Instead, it is to highlight overall transformations to the framework’s foundational approach, such as, say, the unidirectional movement of data and logic.
A data value chain is simply a framework that demarcates the journey of data from inception to consumption. There are various ways multiple vendors and analysts have grouped the data value chain.
Historically, the five below stages have prevailed:

What’s missing in this existing value chain is how data monetisation is the last stage while all the stages before it is typically isolated, and there is no way for data teams or organisations to tie the value of operations in each of these stages with the final business ROI. Even though this is the regular practice across data teams and organisations, which has continued for well over half a decade or more, it is one of the largest contributors to leaking ROI.
The data value chain evolved over time along with the data industry to satisfy the growing demand for data-centric solutions as well as the growing volume of data generated and owned by organisations.
In hindsight, the path of evolution over the years was one of many paths that could have emerged. However, in my personal opinion, it was also one of the best natural evolutionary routes that benefited the data industry, even though the current state of the data value chain is a growing problem for organisations.
I say so considering the fact that the entire data stack was preliminary, adolescent at best. If data teams and leaders did not focus on maturing the underlying nuts and bolts, our learning as a data industry could have been stunted. Perhaps we would have never developed robust components or even understood the need for robust components in the underlying data stacks.
However, we cannot overlook the fact that in the current state of data overwhelm, the historical data value chain does more harm than good. It eats away the ROI of data teams in the following ways:

The solution is to re-engineer the data value chain and view it through a new lens made of the following five paradigms:
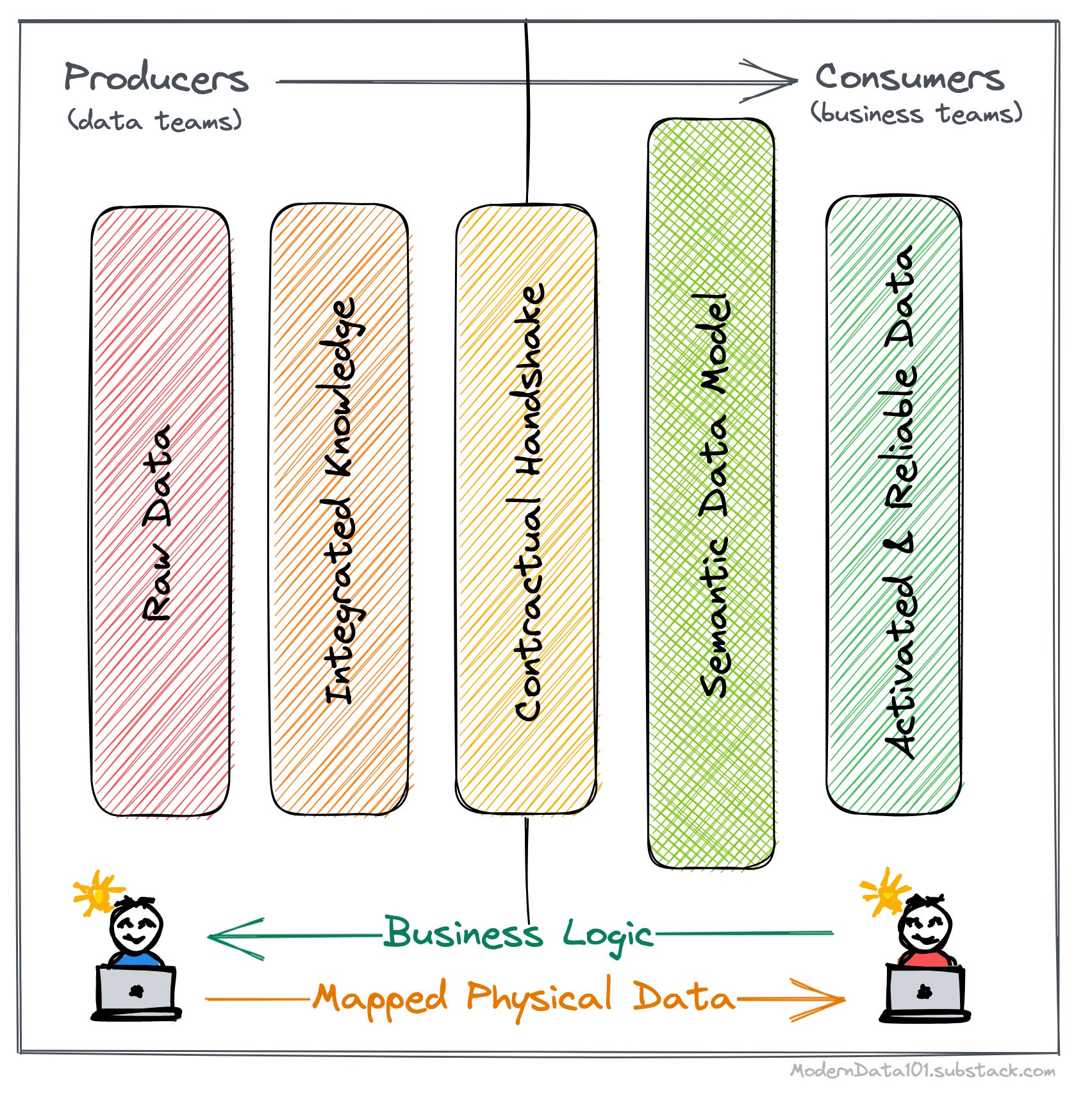
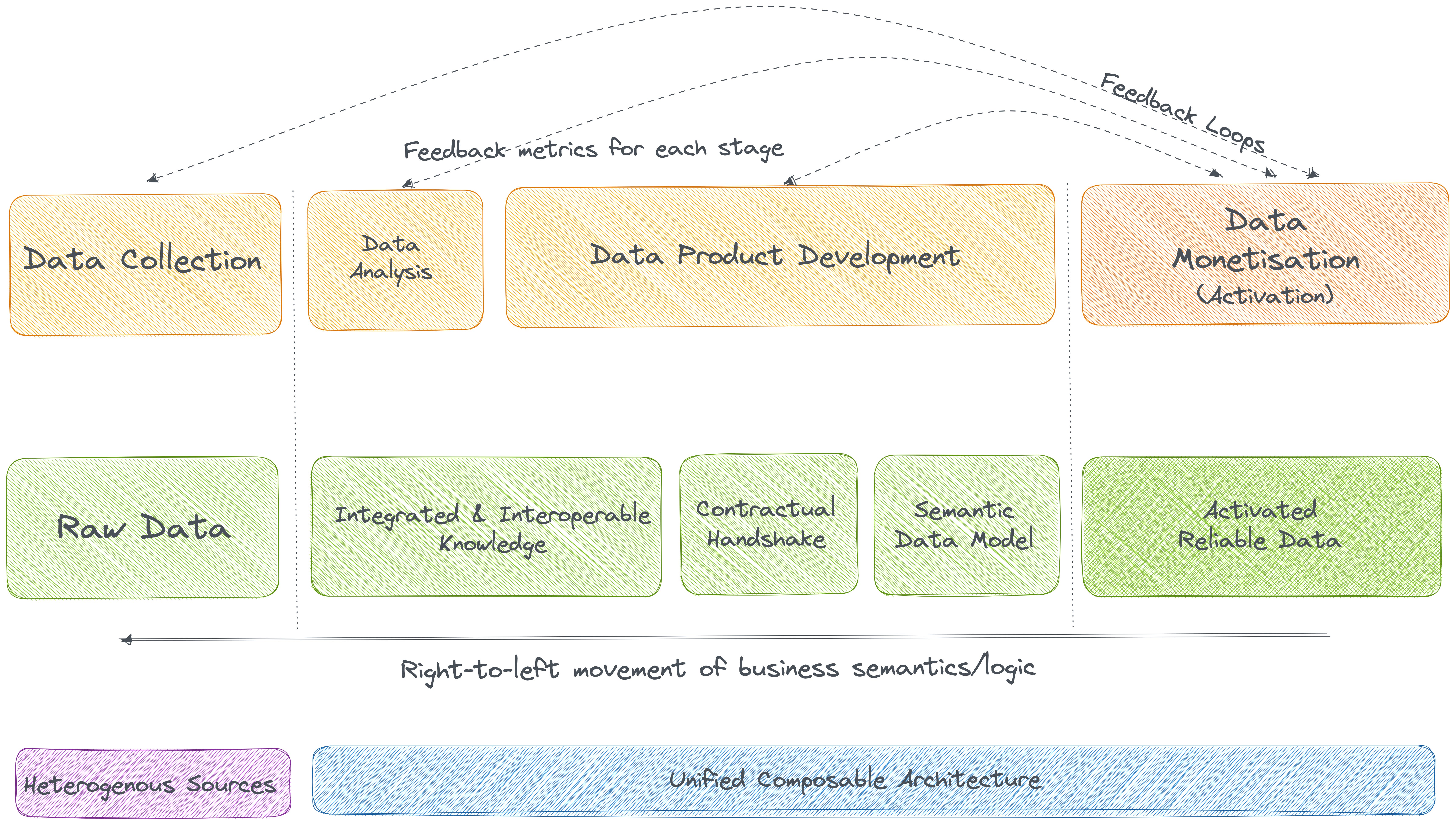
The above engineering, as well as conceptual shifts, are directly facilitated through the Data First Stack (DFS), which propones a unified architecture that is declaratively manageable with state-of-the-art developer experience. The impact of DFS is visible within weeks instead of months and years, unlike legacy modifications.
Data-first, as the name suggests, is putting data and data-powered decisions first while de-prioritizing everything else either through abstractions or intelligent design architectures. It would be easier to understand this if we look at it from the opposite direction - “data-last”.
Current practices, including MDS, is an implementation of “data-last” where massive efforts, resources, and time are spent on managing, processing, and maintaining data infrastructures to enable legacy data value chain frameworks. Data and data applications are literally lost in this translation and have become the last focus points for data-centric teams, creating extremely challenging business minefields for data producers and data consumers.
The Data-First stack is synonymous with a programmable data platform which encapsulates the low-level data infrastructure and enables data developers to shift from build mode to operate mode. DFS achieves this through infrastructure-as-code capabilities to create and deploy config files or new resources and decide how to provision, deploy, and manage them. Data developers could, therefore, declaratively control data pipelines through a single workload specification or single-point management.
Data developers can quickly deploy workloads by eliminating configuration drifts and vast number of config files through standard base configurations that do not require environment-specific variables. In short, DFS enables workload-centric development where data developers simply declare workload requirements, and the data first stack takes care of provisioning resources and resolving the dependencies. The impact is instantly felt with a visible increase in deployment frequency.
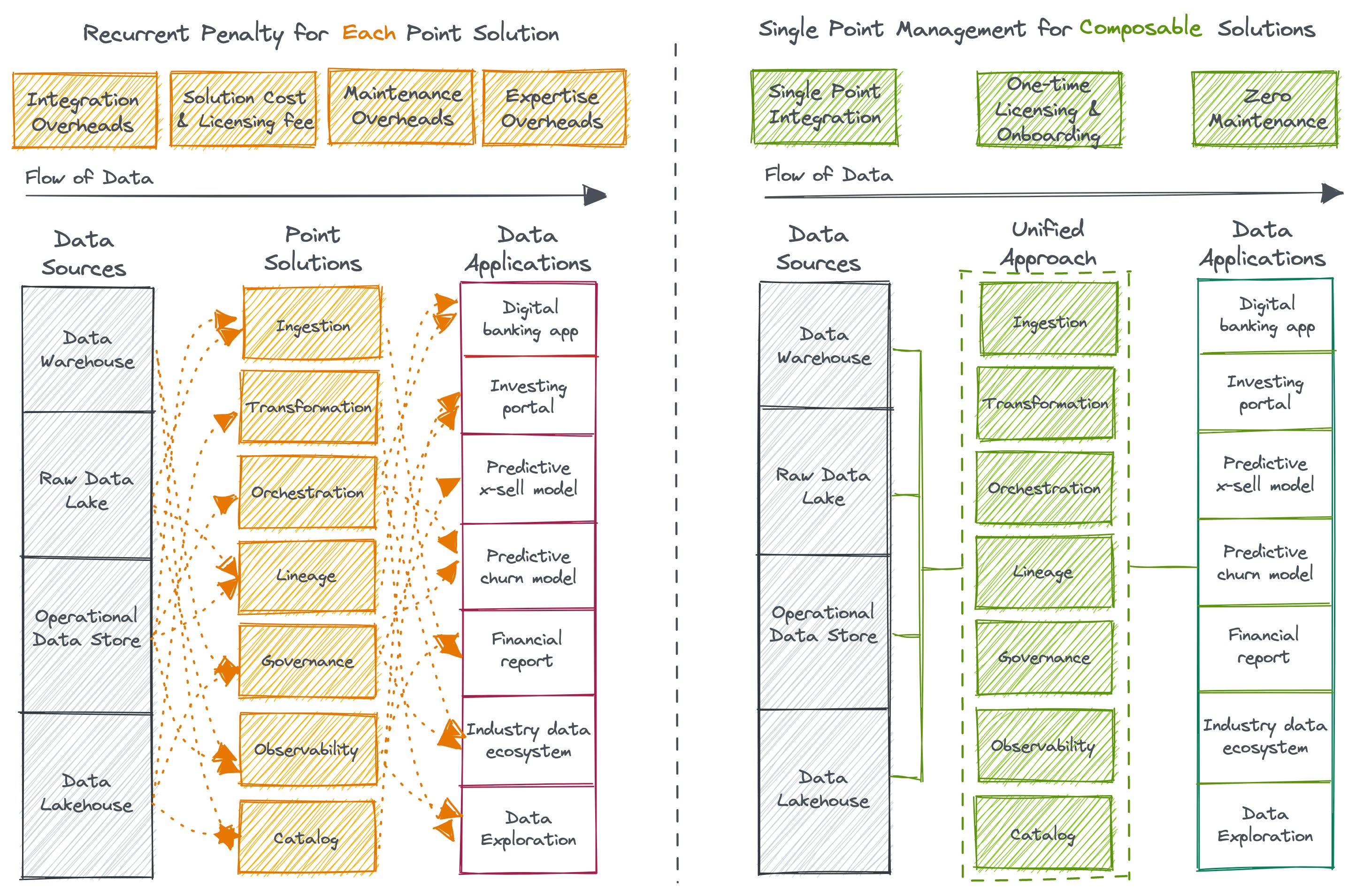
Consider all the values and benefits of DevOps duplicated by the data stack simply with a single shift of approach: Managing infrastructure as code. This is in stark contrast to going the whole nine yards to ensure observability, governance, CI/CD, etc., as isolated initiatives with a bucket load of tooling with integration overheads to ultimately ensure “DataOps.” How about implementing DevOps itself?
This approach consequently results in cruft (debt) depletion since data pipelines are declaratively managed with minimal manual intervention, allowing both scale and speed (Time to ROI). Higher-order operations such as data governance, observability, and metadata management are also fulfilled by the infrastructure based on declarative requirements.
In prevalent data stacks, we do not just suffer from data silos, but there’s a much deeper problem. We also suffer tremendously from data code silos. DFS treats data as software by enabling the management of infrastructure as code (IaC). IaC wraps code systematically to enable object-oriented capabilities such as abstraction, encapsulation, modularity, inheritance, and polymorphism across all the components of the data stack. As an architectural quantum, the code becomes a part of the independent unit that is served as a Data Product.
DFS implements data as a software paradigm by allowing programmatic access to the entire data lifecycle. It enables management and independent provisioning of low-level components with state-of-the-art data developer experience. Data developers can customize high-level abstractions on a need basis, use lean CLI integrations they are familiar with, and overall experience software-like robustness through importable code, prompting interfaces with smart recommendations, and on-the-fly debugging capabilities. Version control, review processes, asset and artefact reusability,
Data as a product is a subset of the data-as-a-software paradigm wherein data inherently behaves like a product when managed like a software product, and the system is able to serve data products on the fly. This approach enables high clarity into downstream and upstream impacts along with the flexibility to zoom in and modify modular components.
DFS makes life easy for Data Developers by ensuring their focus is on data instead of on complex maintenance mandates. The Command Line Interface (CLI) gets the second precedence since data developers have a familiar environment in which to run experiments and develop their code. The artefact-first approach puts data at the centre of the platform and provides a flexible infrastructure with a suite of loosely coupled and tightly integrable primitives that are highly interoperable. Data developers can use DFS to create complex workflows with ease, taking advantage of its modular and scalable design.
Being artefact-first with open standards, DFS can also be used as an architectural layer on top of any existing data infrastructure and enable it to interact with heterogenous components, both native and external to DFS. Thus, organizations can integrate their existing data infrastructure with new and innovative technologies without having to completely overhaul their existing systems.
It’s a complete self-service interface for developers where they can declaratively manage resources through APIs, CLIs, and even GUIs if it strikes their fancy. The intuitive GUIs allow the developers to visualize resource allocation and streamline the resource management process. This can lead to significant time savings and enhanced productivity for the developers, as they can easily manage the resources without the need for extensive technical knowledge. GUIs also allow business users to directly integrate business logic into data models for seamless collaboration.
The data-first stack is forked into a conceptual dual-plane architecture to decouple the governance and execution of data applications. This gives the flexibility to run the DFS in a hybrid environment and deploy a multi-tenant data architecture. Organizations can manage cloud storage and compute instances with a centralised control plane and run isolated projects or environments across multiple data planes.
The central control plane is typically charged with metadata, orchestration, and governance responsibilities since these components need to seep into multiple endpoints to allow holistic management. The central control plan is the data admin’s headquarters.
The data plane is charged with more data-specific activities such as ingestion, transformation, federated queries, stream processing, and declarative app config management. Users can create multiple data planes based on their requirements, such as domain-specific data planes, use-case-specific data planes, environment-specific data planes, etc.
The key transformation to the data value chain would be the inclusion of the data product paradigm. In this article, we focused on other aspects, such as the right-to-left paradigm, feedback loops or direct ties with business impact, unified composable architecture, and intelligent data movement.
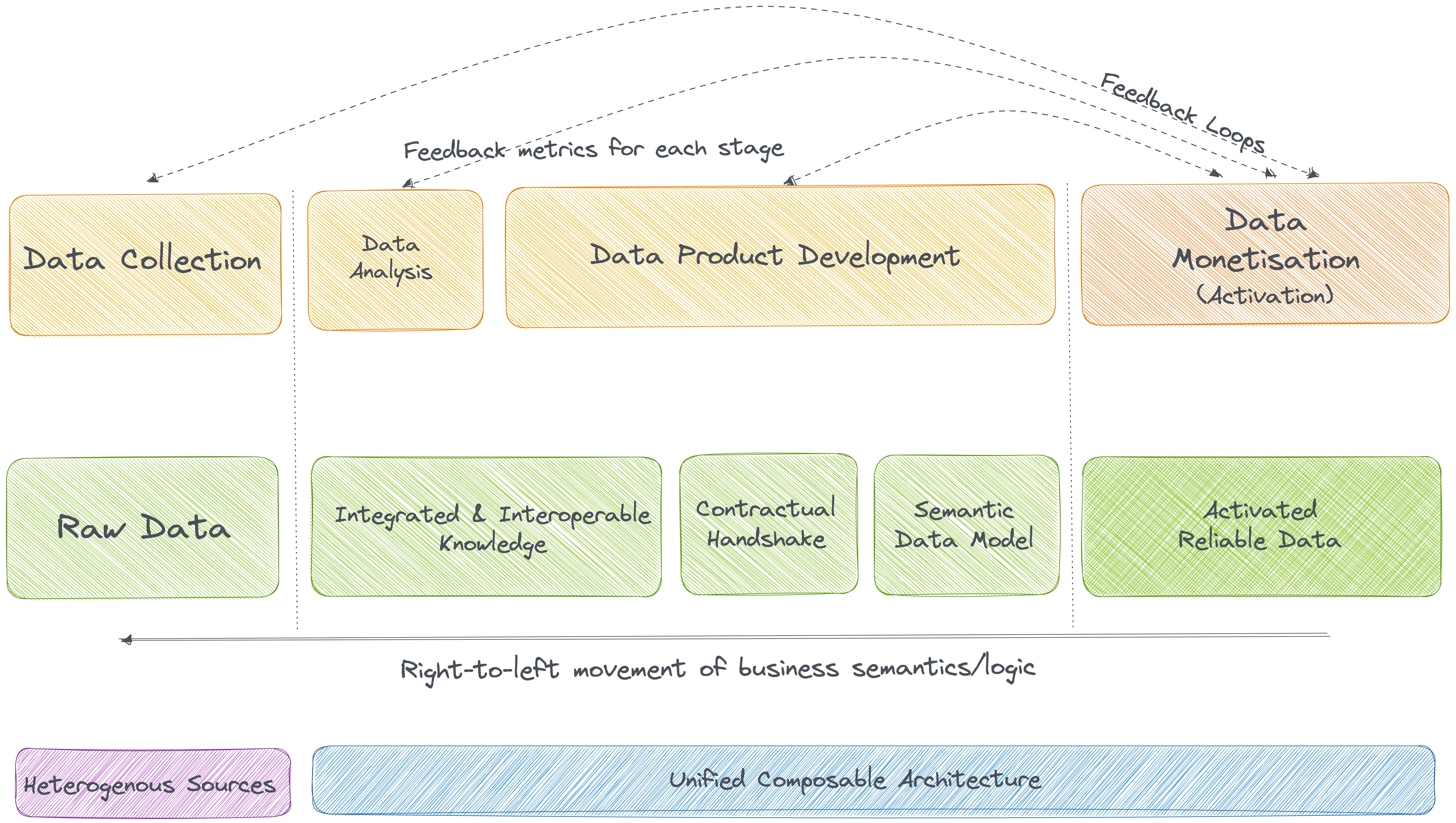
We also covered how the data-first stack enables the above transformational requirements through its technical topography:
The data product aspect is wider and requires a part 2 to dive deeper. It includes three components: Code, Infrastructure, Data & Metadata. In “Re-engineering the data value chain Part 2”, we’ll dive deeper into the data value chain and, consequently, into each of the data product components to see how it fits into the new framework. In part 2, a few more technical pillars of the Data First Stack will also surface, ones which especially help to converge data into data products.
Since its inception, ModernData101 has garnered a select group of Data Leaders and Practitioners among its readership. We’d love to welcome more experts in the field to share their story here and connect with more folks building for better. If you have a story to tell, feel free to email your title and a brief synopsis to the Editor.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

.avif)


Animesh Kumar is the Co-Founder and Chief Technology Officer at The Modern Data Company, where he leads the design and development of DataOS, the company’s flagship data operating system. With over two decades in data engineering and platform development, he is also the founding curator of Modern Data 101, an independent community for data leaders and practitioners, and a contributor to the Data Developer Platform (DDP) specification, shaping how the industry approaches data products and platforms.

Modern Data 101 Community

Find more community resources

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




