

Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...
.jpg)
.png)
.png)
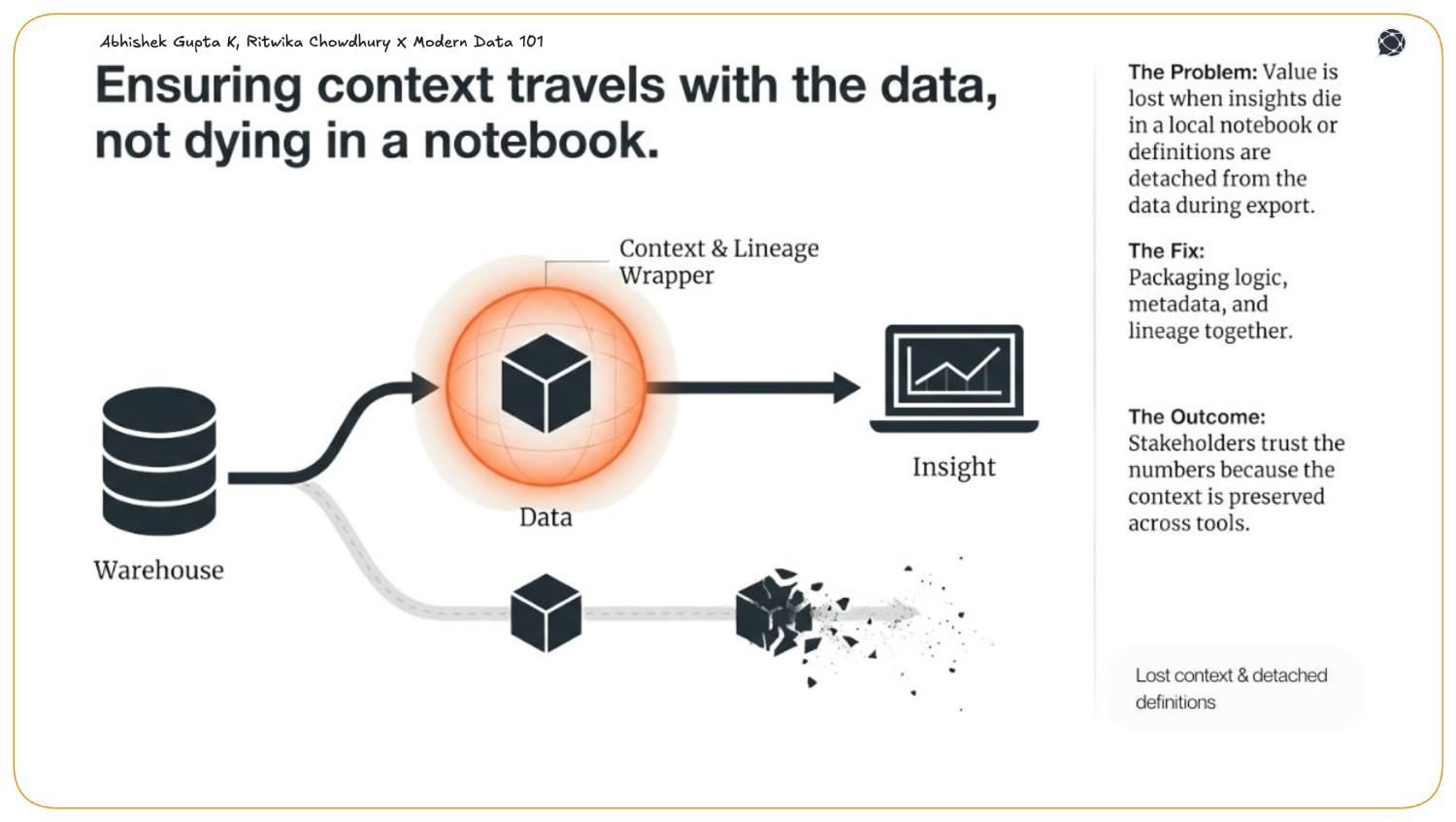
TABLE OF CONTENT




In a recent LinkedIn post, I pointed out the discord between data producers and consumers that is specifically ignited due to poor data modelling practices. The irony is data modelling goals are to be aligned with quite the opposite, i.e., it is supposed to break down the high wall between the two counterparts.
Given the vast head nods on that post, it was validation of the fact that it is not just an exclusive problem torturing the likes of me, my friends, or acquaintances, but it is, in fact, a devil for the data industry at large.

Let’s break down the problem into the trifecta of data personas.
Data producers are constantly stuck with rigid legacy models that reduced the flexibility of data production and hinder produce of high-quality composable data. Multiple iterations with data teams are often necessary to enable the required production schema and requirements.
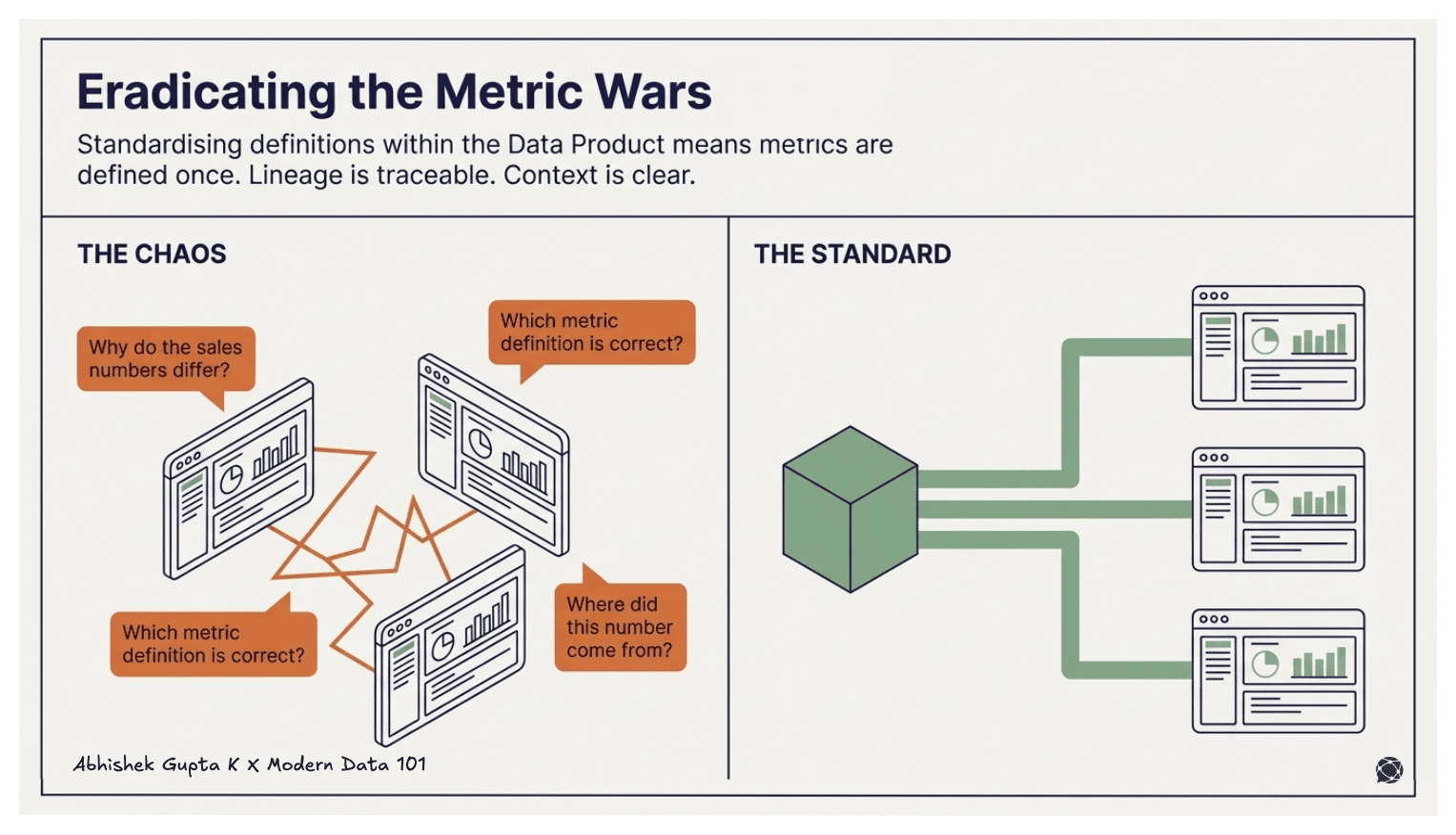
A hinderance to effective data modeling is that data consumers suffer from slow metrics and KPIs, especially when the data and query load of warehouses or data stores increase over time. Expensive, complex, and time-taking joins to make the consumption process littered with stretched-out timelines, bugs, and unnecessary iterations with data teams. There is often no single source of truth that different consumers could reliably refer to, and thereafter, discrepancies are rampant across the outcome of BI tools. Consumers are the largest victim of broken dependencies, and sometimes they are not even aware of it.
Data engineers are bogged down with countless requests from both producers and consumers. They are consistently stuck between the choices of creating a new data model or updating an old one. Every new model they generate based on unique requests adds to the plethora of data models they are required to maintain for as long as the dependencies last (lifetime). Grappling with data modelling complexities like updating models often means falling back on complex queries that are buggy and lead to broken data pipelines and a bunch of new requests because of those broken pipelines. In short, while figuring out the right approach to data modelling, data engineers suffer tremendously in the current data stack, and it is not sustainable.

In short, Data Models are creating a high wall between data producers and data engineers while their sole objective is to eliminate the gap between the two ends. However, it is not Data Modeling’s fault. Data Modeling has been and is one of the coolest ways to manage data. The problem lies in the way they are implemented, constantly making bottlenecks out of poor data engineers. Almost like any other approach in the data space, identifying the best practices that organisations should follow while building their data models can be the real solution for any obstacle created.
You can learn more about the best practices of data modelling and how it can help you address the inevitable siloes and bring back scalable and independent AI/ML.
Data Modeling: Resurrection Stone for Scalable and Independent AI/ML
The chaos goes back years and decades, but it has started impacting strategic conversations lately, especially due to the growing importance and volume of data for organisations. Data was only an afterthought before, used only for fundamental analysis work. But the narrative has changed, and how!
Today businesses that have a good grasp of data make the difference between winning and losing the competitive edge. Many data-first organizations, the likes of Uber, Airbnb, and Google, understood this long back and dedicated major projects to becoming data-first.
Contrary to popular belief, the modern data stack is a barrier to optimising the capabilities of data models. The primary reason causing the silo between data producers and data consumers is a chaotic bunch of tools and processes that are clogged into the system. Each somehow trying to make use of the rigid data model defined by someone possibly with no idea about the lay of the business landscape.
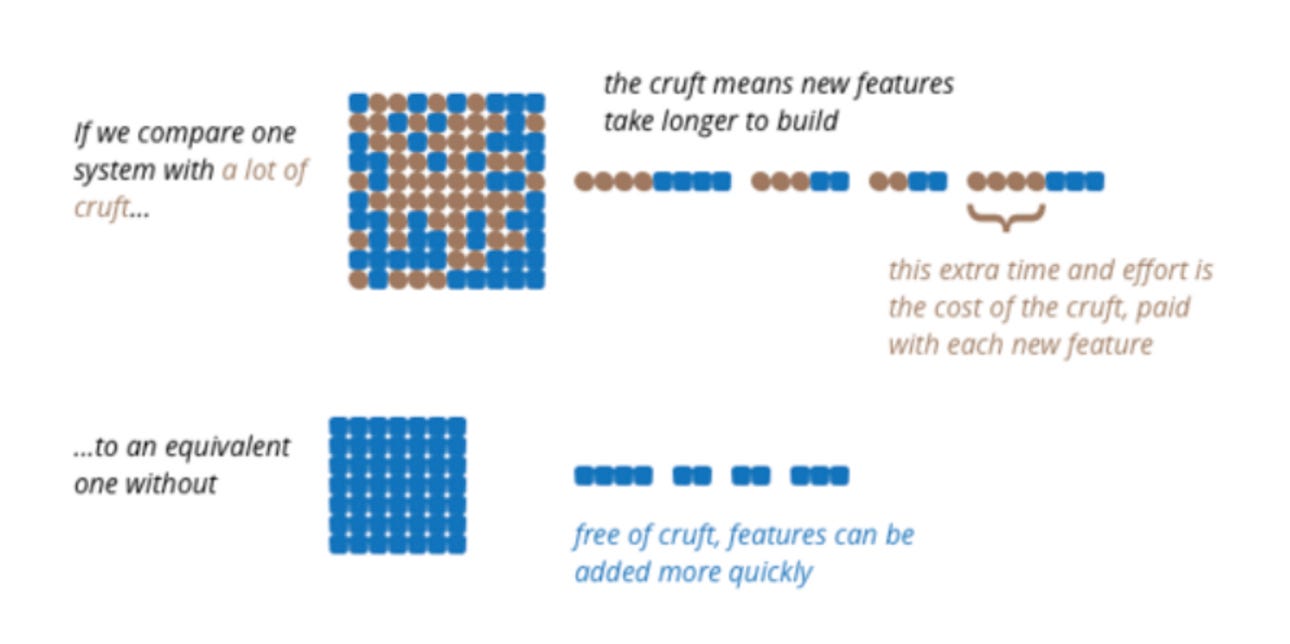
Spending more capital on one more tool is not a solution, but it's an additional layer on a chaotic base. More tools bring in more cruft (debt) and make the problem more complex.
As one of my idols, Martin Fowler, would say:
"𝘛𝘩𝘪𝘴 𝘴𝘪𝘵𝘶𝘢𝘵𝘪𝘰𝘯 𝘪𝘴 𝘤𝘰𝘶𝘯𝘵𝘦𝘳 𝘵𝘰 𝘰𝘶𝘳 𝘶𝘴𝘶𝘢𝘭 𝘦𝘹𝘱𝘦𝘳𝘪𝘦𝘯𝘤𝘦. 𝘞𝘦 𝘢𝘳𝘦 𝘶𝘴𝘦𝘥 𝘵𝘰 𝘴𝘰𝘮𝘦𝘵𝘩𝘪𝘯𝘨 𝘵𝘩𝘢𝘵 𝘪𝘴 "𝘩𝘪𝘨𝘩 𝘲𝘶𝘢𝘭𝘪𝘵𝘺" 𝘢𝘴 𝘴𝘰𝘮𝘦𝘵𝘩𝘪𝘯𝘨 𝘵𝘩𝘢𝘵 𝘤𝘰𝘴𝘵𝘴 𝘮𝘰𝘳𝘦. 𝘉𝘶𝘵 𝘸𝘩𝘦𝘯 𝘪𝘵 𝘤𝘰𝘮𝘦𝘴 𝘵𝘰 𝘵𝘩𝘦 𝘢𝘳𝘤𝘩𝘪𝘵𝘦𝘤𝘵𝘶𝘳𝘦 𝘢𝘯𝘥 𝘰𝘵𝘩𝘦𝘳 𝘢𝘴𝘱𝘦𝘤𝘵𝘴 𝘰𝘧 𝘪𝘯𝘵𝘦𝘳𝘯𝘢𝘭 𝘲𝘶𝘢𝘭𝘪𝘵𝘺, 𝘵𝘩𝘪𝘴 𝘳𝘦𝘭𝘢𝘵𝘪𝘰𝘯𝘴𝘩𝘪𝘱 𝘪𝘴 𝘳𝘦𝘷𝘦𝘳𝘴𝘦𝘥. 𝘏𝘪𝘨𝘩 𝘪𝘯𝘵𝘦𝘳𝘯𝘢𝘭 𝘲𝘶𝘢𝘭𝘪𝘵𝘺 𝘭𝘦𝘢𝘥𝘴 𝘵𝘰 𝘧𝘢𝘴𝘵𝘦𝘳 𝘥𝘦𝘭𝘪𝘷𝘦𝘳𝘺 𝘰𝘧 𝘯𝘦𝘸 𝘧𝘦𝘢𝘵𝘶𝘳𝘦𝘴 𝘣𝘦𝘤𝘢𝘶𝘴𝘦 𝘵𝘩𝘦𝘳𝘦 𝘪𝘴 𝘭𝘦𝘴𝘴 𝘤𝘳𝘶𝘧𝘵 𝘵𝘰 𝘨𝘦𝘵 𝘪𝘯 𝘵𝘩𝘦 𝘸𝘢𝘺.”
Contrary to the widespread mindset that it takes years to build a data-first stack, with new storage and compute tools and innovative technologies that have popped up in the last couple of years, this is no longer true. It is not impossible to build a data-first stack and reap value from it within weeks instead of months and years.
Referring again to Martin Fowler’s architectural ideology:
“High internal quality leads to faster delivery of new features because there is less cruft to get in the way. While it is true that we can sacrifice quality for faster delivery in the short term, before the build-up of cruft has an impact, people underestimate how quickly the cruft leads to an overall slower delivery. While this isn't something that can be objectively measured, experienced developers, reckon that attention to internal quality pays off in weeks, not months.”
In the journey of this data-first stack, we need to be ruthless about trimming the countless moving parts that plug into a data model. Chop down multiple tools and, with it, eliminate integration overheads, maintenance overheads, expertise overheads, and licensing costs that build up to millions with no tangible outcome.
A data-first stack is only truly data-first when built with the right ideology and in alignment with your internal infrastructure. This can be answered by understanding a data developer platform. Read about it more here: https://datadeveloperplatform.org/
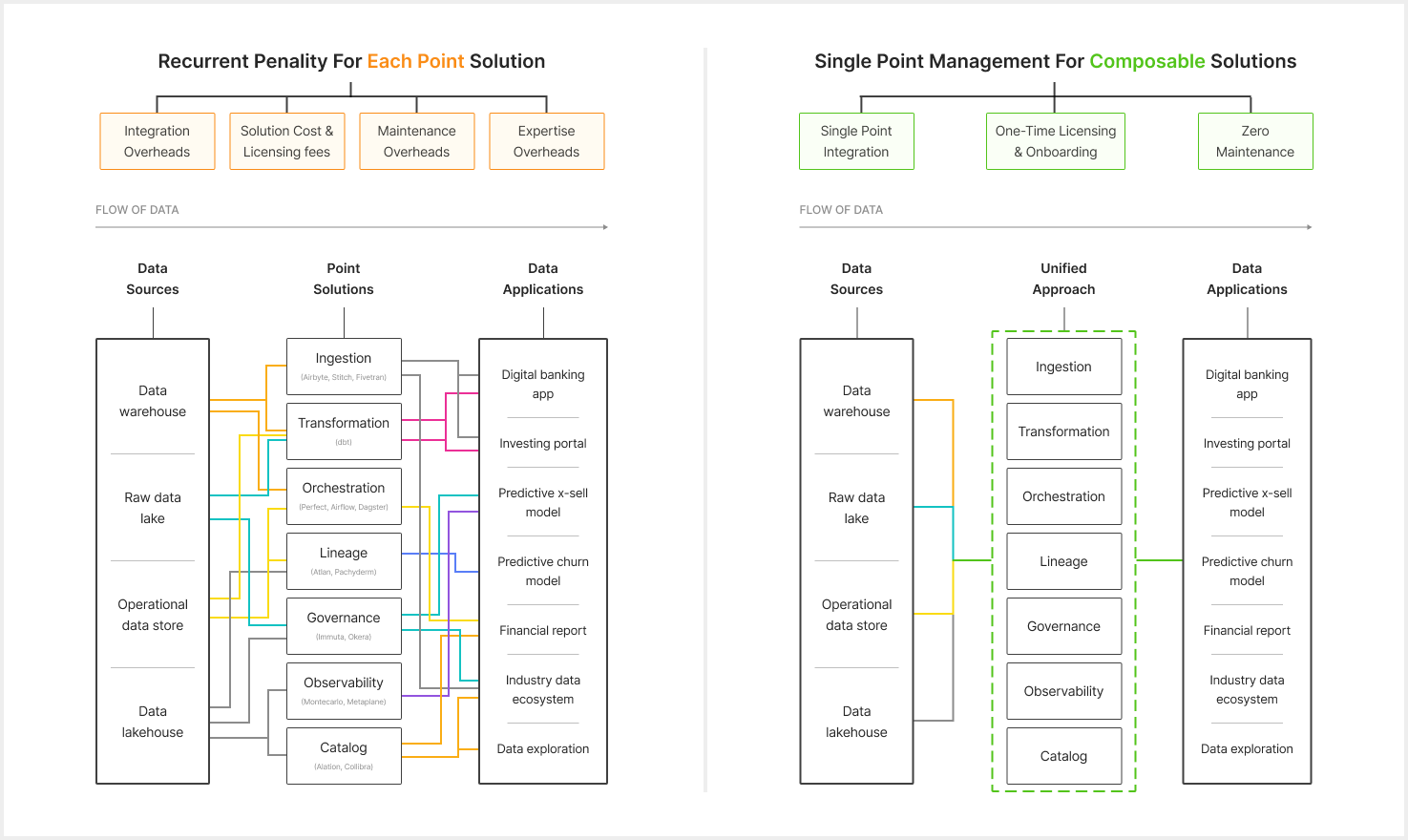
For a deep dive into the overheads of point solutions that make up the Modern Data Stack, refer to:

In the traditional approach, data teams are stuck with defining data models in spite of the fact that they do not have much exposure to the business side. However, the task still falls on them since data modeling is largely considered to be part of the engineering stack. This narrative needs to change.
The purpose of a data modelling is to build the right roadmap for data to fall into. Who better to do this than business folks who work day and night with the data and know exactly how and why they want it? This would give back control of business logic to business teams and leave the management to data teams and technologies. But how should this be materialised? Declarative and Semantic layers of abstraction.
Business teams would give a hard pass to complex SQLs, databases, or low-level data modeling techniques. It’s a tragedy that they are forced to deal with them, but if given the opportunity, they would choose the more intuitive and quicker path that impacts business at the sweet time and the sweet spot.
Moreover, such abstractions are not just for business folks exclusively. To make life easier for all (producers, consumers, and data engineers), we need to create a seamless way for business personnel to inject their vast industry and domain knowledge into the data modeling pipeline. Reduce the complexity of SQLs through abstractions that analysts can easily understand and operate. Omit the need for analysts to struggle with their double life as analytical engineers.
A semantic source of truth is different from what is usually referred to as a single source of truth for data. A semantic source of truth refers to a single point that emits verified logic that the organisation could blindly rely on.
“Blindly relying” is a big step, so we need the right system to enable optimal reliability. Surely you’ve heard of data contracts? Contracts are your one-stop lever to declaratively manage schema, semantics, and governance to bring harmony between producers and consumers (keep watching Modern Data 101 for more about Contracts).
Since its inception, ModernData101 has garnered a select group of Data Leaders and Practitioners among its readership. We’d love to welcome more experts in the field to share their story here and connect with more folks building for better. If you have a story to tell, feel free to email your title and a brief synopsis to the Editor.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

.avif)


Animesh Kumar is the Co-Founder and Chief Technology Officer at The Modern Data Company, where he leads the design and development of DataOS, the company’s flagship data operating system. With over two decades in data engineering and platform development, he is also the founding curator of Modern Data 101, an independent community for data leaders and practitioners, and a contributor to the Data Developer Platform (DDP) specification, shaping how the industry approaches data products and platforms.

Modern Data 101 Community

Find more community resources

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



