





TABLE OF CONTENT
This is part of the Data Product Lifecycle Series. If you’re new here, feel free to refer to:
Stage 1: Designing Data ProductsStage 2: Building Data Products
The deployment of data products is the crux of Stage 3 in the Data Product Lifecycle series. It is predominantly about facilitating the optimum developer experience for data developers and teams. In this stage, developers especially need the freedom to run experiments with workflows and transformation logic, make informative mistakes without dire consequences, test new routes, validate, and deploy iteratively.
The deployment stage emphasises the importance of self-serve data platforms where developers are able to taste a unified experience instead of managing change and configuration drifts for every deployment cycle that spans several iterations, tools, isolated code, and consumption points.
The core essentials while running deployments for data products involve:
- Seamless developer experience by eliminating delivery, access, and cognitive friction
- Declarative specs and deployments, abstracting underlying infra complexities
- Unified capabilities under one hood, even with third-party capabilities standardised through a common platform plane
- Isolated resource allocation and execution
- Iterative experimentation and validation without collateral damage
- Managing and triggering end-to-end workflows or Data Product DAGs, inclusive of native and external pipelines, SLOs and monitors, policies, and catalog updates.
Fundamentals
To grasp the concept of data product deployment well, we need to go over a few essentials first:
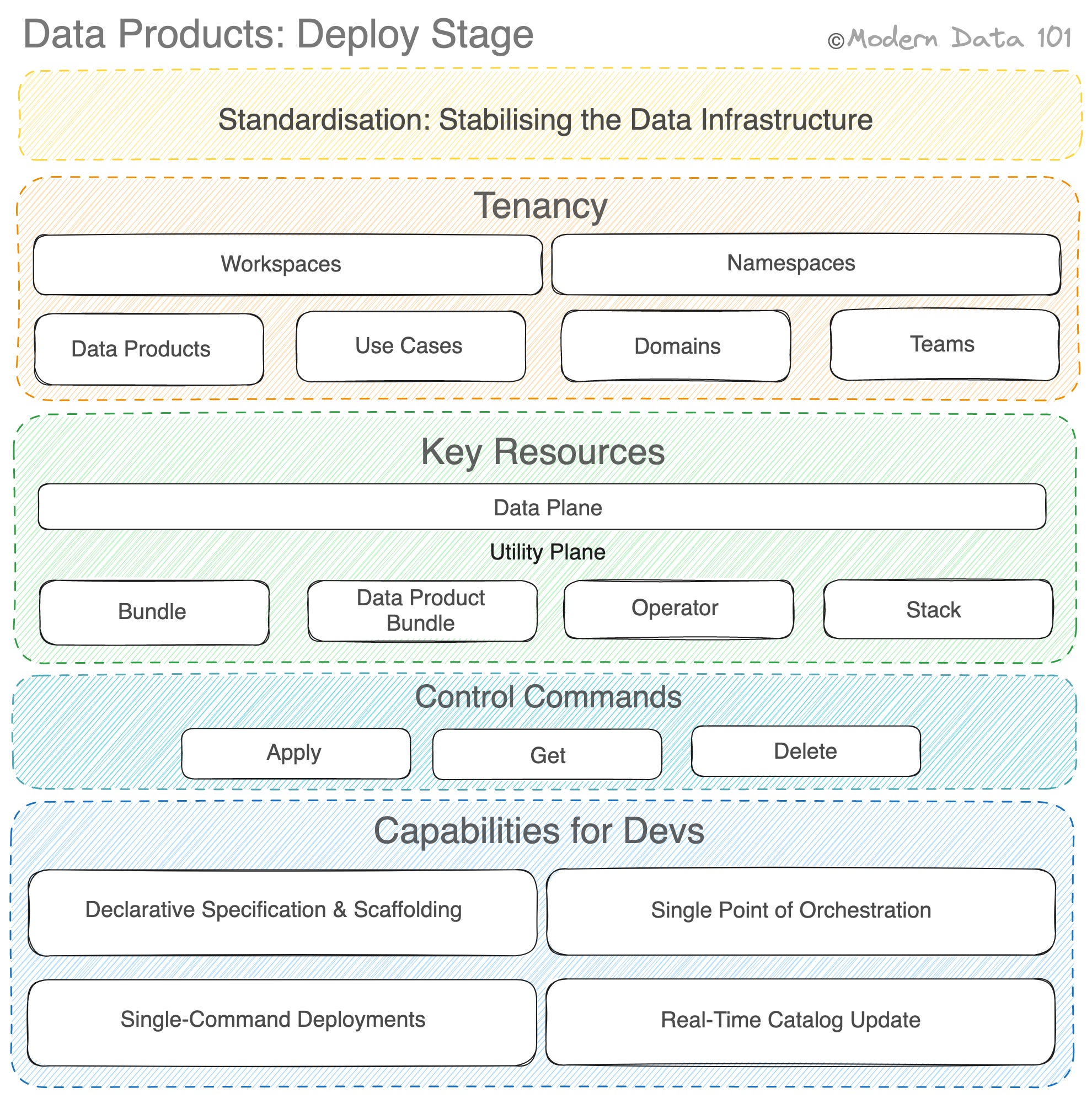
- Stabilising the Data Infrastructure
- Well-defined Boundaries or Tenancy
- Key Resources in the Context of Data Product Deployment
Stabilising the Data Infrastructure
A self-serve data infra helps teams and organisations to rely on a standardised data infrastructure which is free from the disruptions of frequent innovations, technologies, and tooling overheads. This is possible through the evolutionary architecture embedded in Data Developer Platforms, which takes the current and future states of the data infrastructure into account to enable swift transitions.
4D models, data-driven routing, and unit-test frameworks for deployment are some examples of how evolutionary architectures of data developer platforms shield data infrastructures from disruptive technologies while not losing out on the benefits of the same. If you want to learn more about evolutionary architectures, refer to Building Evolutionary Architectures by ThoughtWorks experts Neal Ford, Rebecca Parsons, and Patrick Kua. Here’s a TLDR of the same.
Well-defined Boundaries or Tenancy
One of the primary reasons behind transitioning into Data Product ecosystems is autonomy for business, data, and domain teams, which is currently not the case with severe bottlenecks across centralised teams and spaghetti pipelines.
To enable such autonomy, data products need to become self-dependent - from root to tip. That is, from the bottom-most layer of infrastructure resources such as compute, storage, governance, and deployment infra to the top-most layer of consumer-facing data.
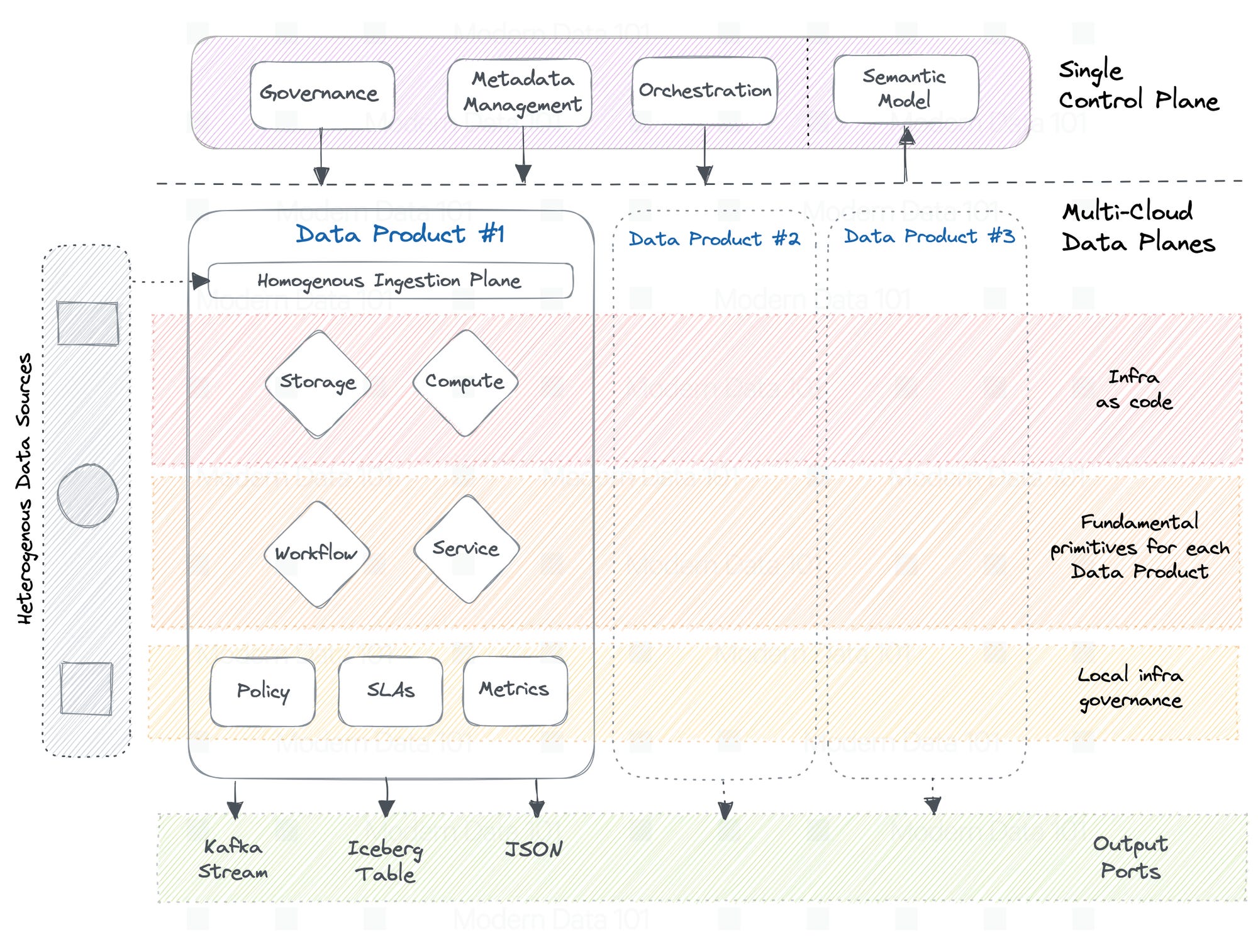
A tenancy pattern delineates access and authorization to specific groups of users to a specific data product (or set of data products). It does this by encapsulating isolations/namespaces on a common capability.
~Streamlined developer experience in Data Mesh (Part 1)
Due to the flexibility of isolation capabilities in Data Developer Platforms, data teams can also choose to isolate certain infra resources such as workflows or policies on use-case or domain levels. In DDPs, these isolations/namespaces go by Workspaces. Again, workspaces can be defined for data products, specific workflows and resources, dev and testing environments, domains, use cases, and much more. The structure is entirely up to the practices and comfort of the teams involved.
Key Resources in the Context of Data Product Deployment
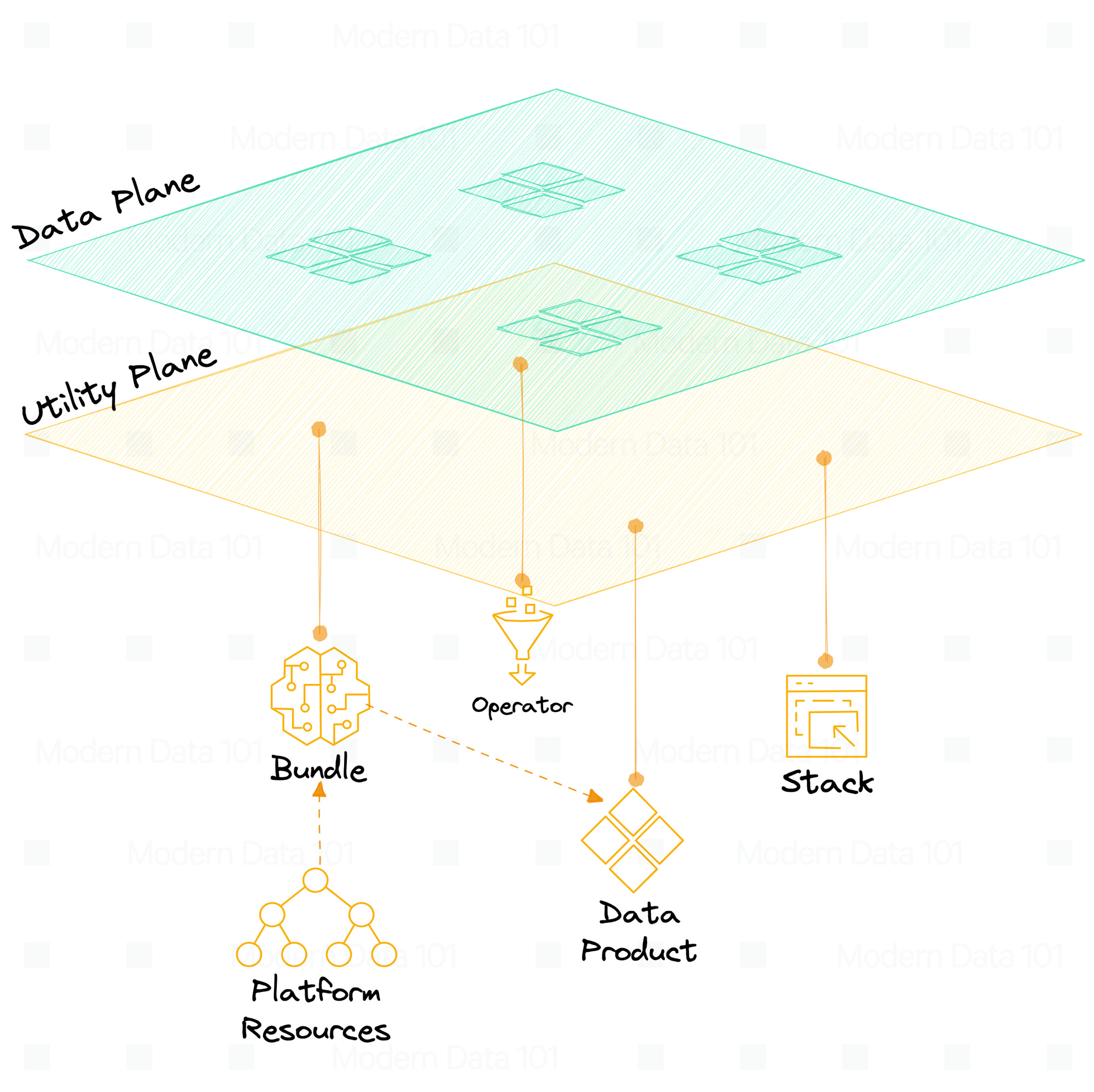
🧺 Bundle
A Bundle resource within a data platform serves as a declarative and standardized mechanism for deploying a collection of Resources, data products, or applications in a single operation. It empowers data developers with the capability to programmatically orchestrate the deployment, scheduling, creation, and dismantling of code and infrastructure resources linked to these data products and applications in a unified manner.
Deploy multiple DDP resources using a single resource anytime a dev wants to deploy and bring multiple resources and define dependencies between them. From the data product context, a bundle allows devs to loosely couple and tightly integrate code, infrastructure, and metadata together.
All resources necessary to build and run data products are brought together to deploy as a single bundle file. We will explain the properties and advantages of bundles in the context of deployment later in this article.
💠 Data Product
Data Product is the extension of the bundle resource into another resource so data developers can work in a data product native way with concepts of input ports, output ports, and other contextual info. It’s a sugar on top of the bundle and makes the basic code data product unit along with scaffolding abilities.
Consider it like a class extension on bundle: everything bundle plus additional info and scaffolding. The Data Product resource works and behaves in the same way and will be registered as a data product on the catalog as a first-class entity- you don't need to explicitly map which bundle is a data product.
🎯All data products are bundles, but all bundles are not data products.
A bundle could also be a simple collection of a few workflows or a couple of validation jobs. Hence a different construct to categorise data products exclusively and with the right terminology.
🔌 Operator
Your data product will likely sit across multiple tool stacks and interact with both internal and external touchpoints. Even though it is possible to build and orchestrate data products entirely within a self-serve data platform, DDPs understand the steep economic and political constraints behind hefty investments in various SaaS licenses and tools, scrapping which would incur negative ROI in the short term.
To work in sync with the pre-existing tooling ecosystem, DDP provides Operators so developers can build Data Products which are natively accessible (accessible by pre-existing and familiar tools in the domain). Operators enable you to orchestrate and monitor external engines like ADF pipelines and DBT workflows.
DDP’s core orchestration engine understands new routes and exposes APIs. After understanding the APIs of these external systems, you create operators and map them to the CRUD and observability patterns of those external systems.
🥞 Stack
Stacks are a suite of SDKs. Aside from the internal stacks of DDP, devs can also create additional stacks. For example, they can bring in pySpark, Flink, Soda, or any other programming paradigm - giving better control to devs to bring in tools they are comfortable with.
Examples of some internal stacks in DDP include declarative spark, stream processing, API exposure, containerised web applications, and more. You don’t need to integrate a stack such as Flink or Spark for every bundle or platform capability. Once defined, it becomes part of the definition from the utility plane itself. Reuse it in the data product plane any number of times. In other words, it’s like introducing external community apps as products in the data platform.
As a data platform dev, stacks reduce the effort to bring in more capabilities in the data developer platform. For every one-time integration, write the YAML, apply in the platform, and you are ready to use the capabilities of, say, soda, flink, or PySpark.
Where does Deployment fit into the picture*
- Bootstrap — this is where the platform provisions the underlying infrastructure for storage, compute, and access for each data product. As an output, scaffolding code and a default specification are provided for the developer to define the product declaratively.
- Deployment (or redeployment) — this is where the developer will provide detailed specifications, build data models and develop transformation logic.
- Retirement — This is when the data product can be removed from the existing infrastructure (typically because it’s out of date and no one uses it).
*Excerpt from a streamlined developer experience in Data Mesh (Part 2)
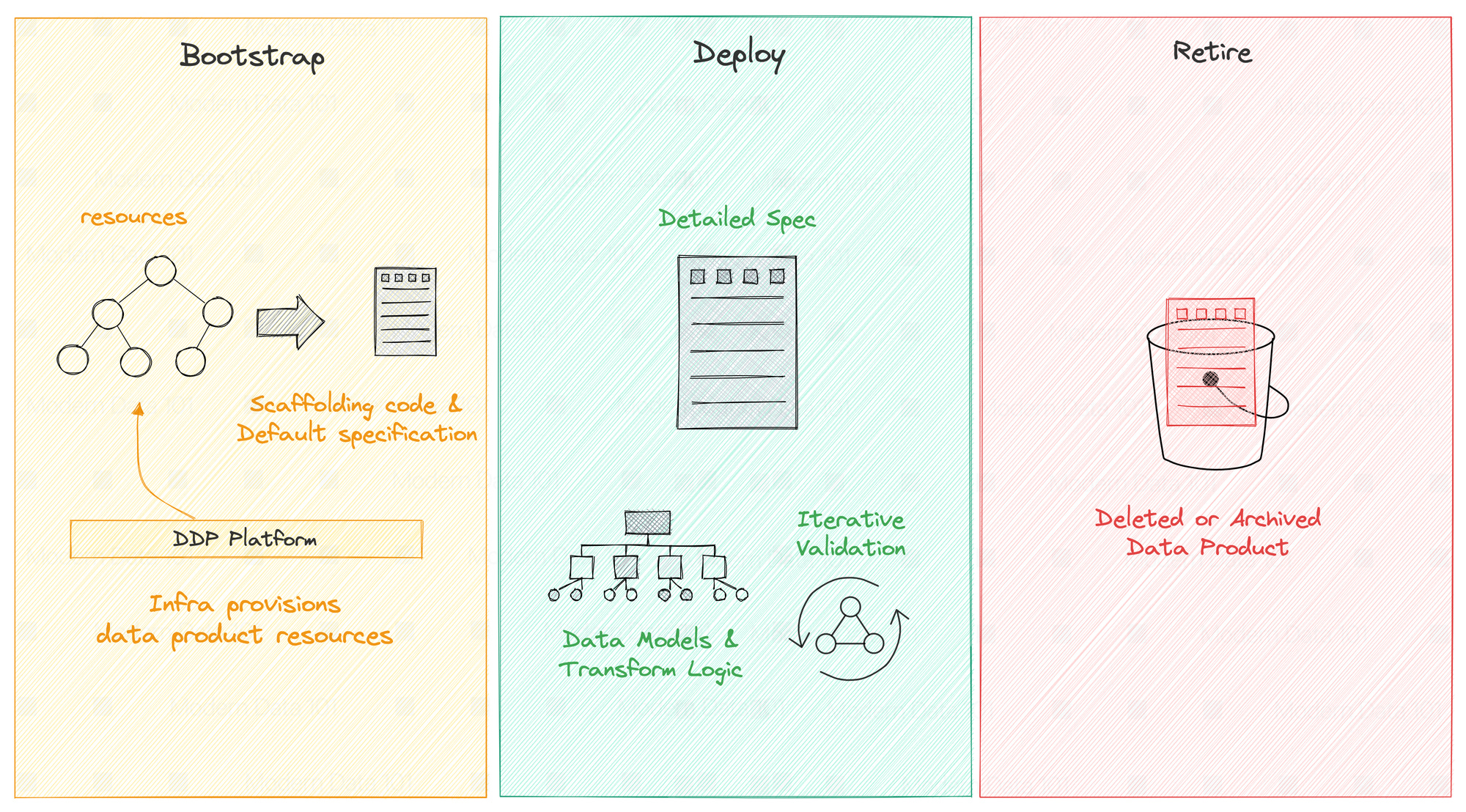
In essence, the deployment stage is, in fact, where the magic happens. You get to progressively validate resources through single-line commands in test environments until you’re certain about the data product bundle. On passing all the standard unit tests, you switch gears and move to production to deploy the data product, again, through one single command line.
Deploying Data Products on Self-Service Data Platforms
The utility plane of data developer platforms with a devX-focused design is the wizard behind seamless deployments. It has the following attributes which make such an experience possible.
- Declarative Specification & Scaffolding
- Single Point of Orchestration
- Single-Command Deployments
- Populating the Catalog
- Resource Isolation
Declarative Specification & Scaffolding
To truly optimise the production of data products, developer experience needs to be optimum. In prevalent processes and dynamics, developers are required to work across multiple threads to resolve a single objective. This can be solved through scaffolding, which is essentially templatisation, and declarative code, which enables developers to work on the strategy level instead of getting down to the complexities of infrastructure plumbing.
A scaffold is a framework, like the scaffolds you see during construction. It allows builders to quickly spin up architectural designs and deploy them quickly. In the context of data, it is a Data product resource (extension of the bundle) which acts as the scaffold with templates for the foundational structure of a data product: input ports, transformations, SLOs, and output ports.
Developers are only required to customise the parameters and make declarative code changes to build the data product for their specific use cases. This templatisation also allows devs to standardise best practices and tooling within the data platform and host external community apps as products in the data platform.
Single Point of Orchestration
The Data Product (Bundle++) also becomes your single-point framework to manage and reflect changes across the data ecosystem - all controls for the entire Data Product DAG rest within the Data Product Bundle. The single-point reference is not just from the pov of change management, but also for resource management.
Resources in a data platform are fundamental and unique functions. Examples: Compute, Storage, Cluster, Workflow, Service, Policy, Depot, and more. The data product bundle becomes the orchestrator of the entire data product DAG that weaves across all such resources.
It is important to note that the Data Product Bundle orchestrates such resources, which are both internal and external to the data platform. For example, a workflow can exist within the data platform as well as sit outside the platform, such as an ADF or DBT pipeline. This is where orchestrators come into the picture and enable:
- Outside-in: Ingest event triggers from outside the platform.
- Inside-out: Trigger events outside the platform.
Hence this can be automated by using the docker runtime of the dataos-ctl in any CI/CD tool. tmdc/dataos-ctl:2.9.29

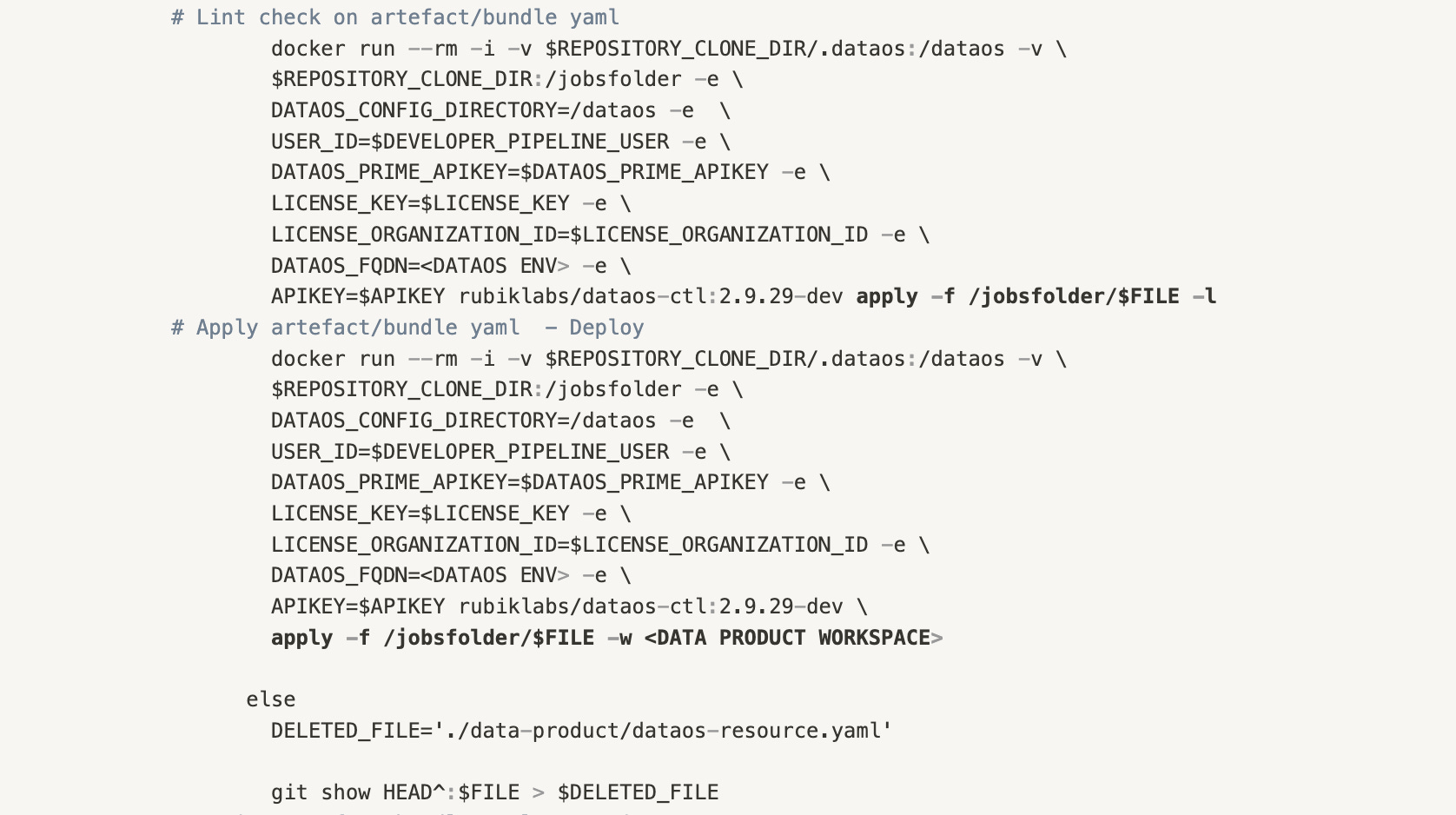
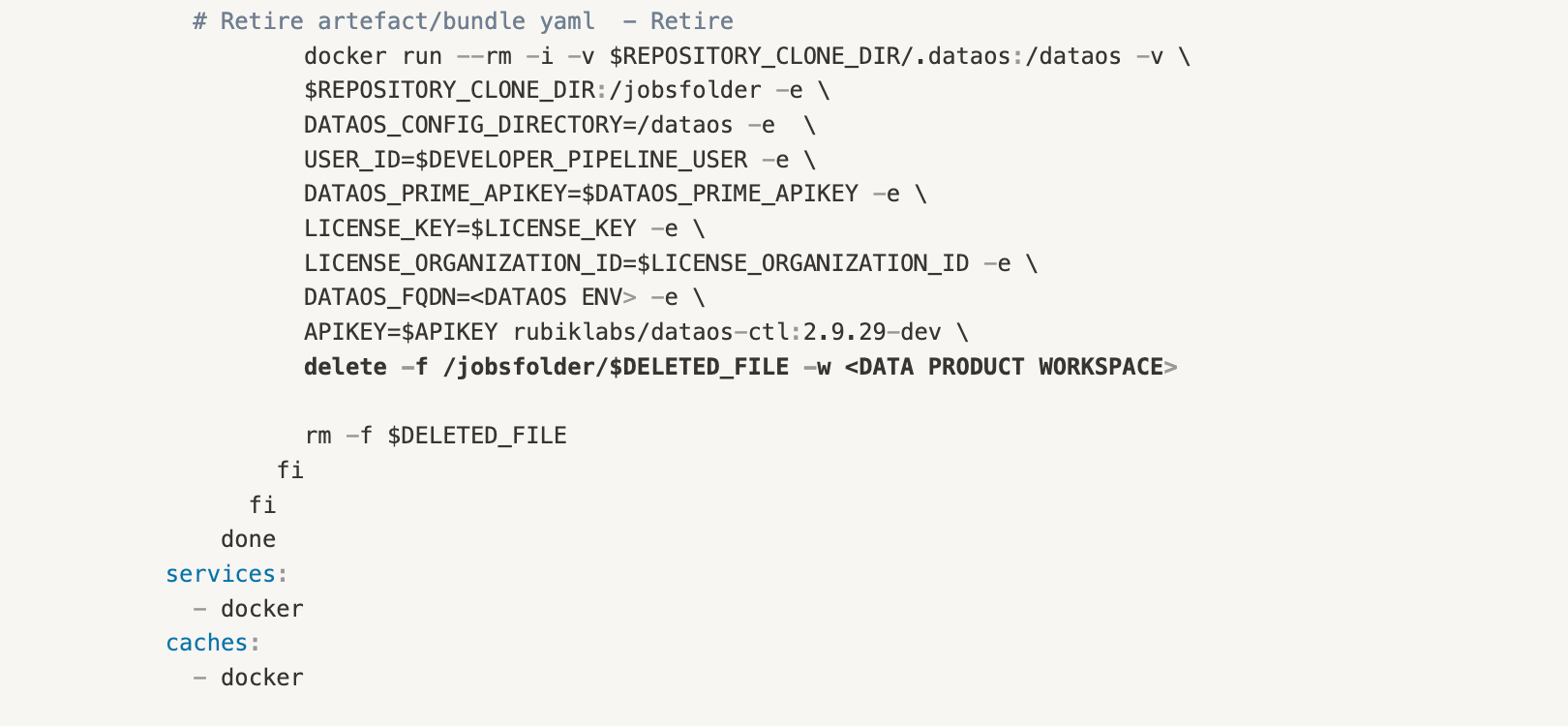
Similarly, developers are allowed to bring in external tools and code stacks as native products in the data platform, rendering devs free from integration complexities and overheads and strengthening the unified experience of data armoury.
Single-Command Deployments
The Apply, Get, and Delete commands are the heart of the deployment stage, enabling developers to experiment, validate, and launch resources in test and prod environments iteratively. These commands allow iterative validation and testing in both testing and prod environments. Users can go two ways:
- create and validate all the resources they would need to create and deploy the bundle
- start writing the bundle directly, adding and validating resources in an incremental fashion
Typically, you’ll not write an entire data product bundle in one go and need to say, figure out what the transformation looks like during experimentation or if there are any clashing quality conditions. This is why the ability to iteratively test and verify is of utmost importance. On the first run, you can verify all the depots (input ports); in the second, validate the workflows, third policies, and so on.
The Apply command is the single command to deploy a data platform resource, and the Get command allows devs to verify the status and health of the resources deployed. Every resource that is applied/deployed can be verified before moving on to the next dependent resource. If the bundle is applied as a whole, the health status of each resource in the data product bundle. can also be validated through the single Get command on the bundle resources.
As soon as a data product bundle is verified and deployed in the primary environment, it is available throughout the platform ecosystem. Analysts or devs can query it through the platform’s query interface, discover it and all its dependent resources on both the platform’s general-purpose catalog and external catalogs (optional), manage its resources on operations centre, and much more.
Populating the Catalog
The platform catalog is an open catalog which can introspect the existing ecosystem and not just be limited to the platform resources. External catalogs can be connected to the general-purpose platform catalog, so these catalogs can fetch info within the platform.
The general-purpose catalog logs information across all entities in the data ecosystem: Tables, Topics, Data Products, and Resources (workflows, depots, services, etc.). It can be used either directly or to push metadata to a centralised catalog that’s already in use by an organisation.
The catalog is populated with metadata on the resources as soon as the resources are deployed with Apply. Devs instantly become privy to workflow graphs, lineage information, provenance, and state-of-the-art metadata. Metadata attributes across data products and data projects are securely exposed, including schema, semantics (tags, descriptions, ontology), metrics, quality conditions, policies, and more.
Resource Isolation
Isolation for data products is not as black and white as we make it out to be. There are several low-level nuances when it comes to isolating resources that make up the data product. For example, while in theory, a data product should have its own isolated compute and query cluster, depending on certain use cases, it sometimes makes more sense to allocate clusters on a domain or use-case level- shared between different data products. This resolves interdependent SQL and catalog queries.
However, some use cases might work better with isolated resources for every data product. For example, to have a dedicated cluster specific to a data product, target depot for that data product and define specific compute for that cluster. This prevents other data products or data assets from sharing those resources.
In essence, a data product should have the flexibility to cater to such low-level differences in isolation designs. Isolation on a resource level depends on the purpose. A domain can have one dedicated cluster that should be used to query all data products within that domain or might want to share a cluster across all its data products. The same is true for other resources such as policies - you can have local policies pointed to individual data products and even global policies on a use-case or domain level.
For the same reasons, certain key resources such as compute, depots, and policies are not bound by a bundle workspace, which means it could be used by other data products as well. To restrict it to one data product, users can define access control patterns for these resources. A best practice is to create the framework as a template (use data product bundle scaffold) - a workspace gets tagged to all the resources defined in that specific data product repository, and a data product developer role inherits the same to ensure a smooth developer experience (not running in access issues and working in their own arch quantum).
Deploying a Data Product Bundle in Practice
We will create a demo data product bundle: dp transaction bundle, and write artefacts around it. We’ll refer to resource files as artefacts. On creating an artefact type bundle, bundle is going to create one or more workspace(s). As described earlier, a workspace is a logical isolation. Any resource that is defined inside a workspace will inherit workspace-level policies, which tie it exclusively to the data product vertical.
Every data product bundle is essentially a DAG of jobs, the first one being ingestion, for which we will create depots. Depots allow users to plug in data sources through a standardised ingestion plane, so they may query and process data from one homogenous source instead of optimising for every different source. There is no data movement involved.
Once my depot gets created, whose definition is residing in another artefact, I'll refer to it from dp transaction bundle. Next comes workflow(s). A workflow is also a DAG composed of jobs spanning across different artefacts in internal or external systems from the perspective of the data platform.
The workflow could also be created in a separate artefact and referred to in the bundle, or devs can directly write transformation jobs with stacks and operators in the bundle itself. All native stacks in a DDP are designed to be declarative. For example, the stack for declarative spark only requires you to write the source, steps, and destination for the transformation job. All the underlying infra complexities are taken care of by the platform.
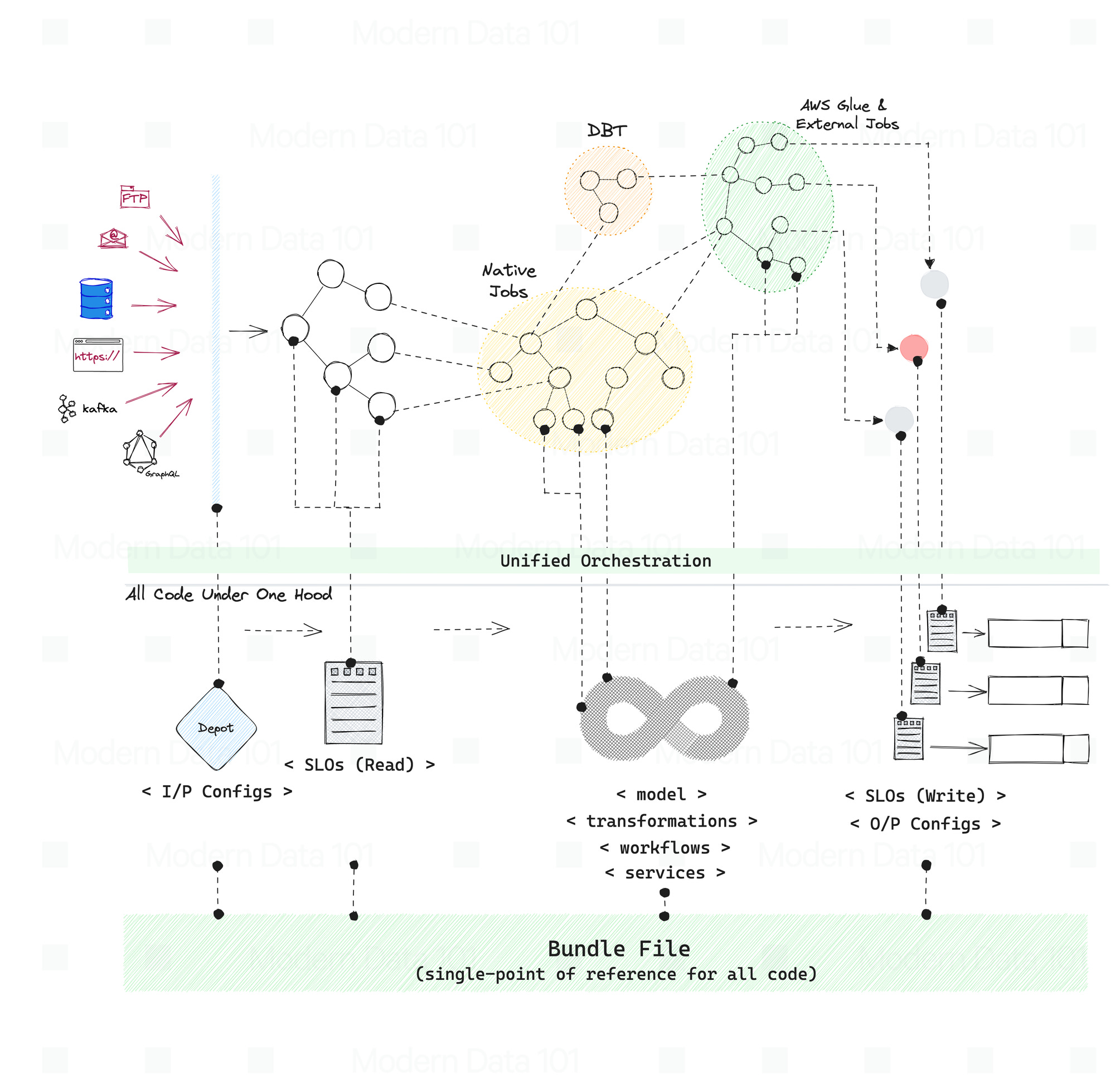
Similarly, you can create other resources, such as policies, depots, services, clusters, and more on the fly and refer them in the bundle. The code for all the artefacts is kept in the same repo allowing the developers to version control the artefact changes, revert if needed and manage releases independently for each data product. You can think of the bundle as the main() function, which calls upon other functions in the same or different files.
In other words, the bundle and resource constructs of a data developer platform gives you programmatic access and control over data.
In summary, we started with ingesting data from ext sources, added retries on top of that job, referred to the location of that artefact, ran a maintenance job on top of the data brought in, and then brought in two jobs, profiling and quality assertions. Similarly, you can create any other logic. All of these jobs are orchestrated with a workflow, and on top of the workflow and depot we created, we have a bundle.
Every resource is deployable and, therefore, testable in iterations. For instance, you can run depots and validate their status. In DataOS (which implements DDP), you validate every resource individually, followed by the validation of the entire data product bundle.
The Apply, Get, and Delete commands are the heart of the deployment stage, enabling developers to experiment, validate, and launch resources in test and prod environments.
Apply the Bundle
After creating the YAML configuration file for the Bundle resource, it's time to apply it to instantiate the resource instance in the platform environment. To apply the Bundle, simply utilize the apply command.

Verify Bundle Creation
To ensure that your Bundle has been successfully created, you can verify it in two ways.
- Check the name of the newly created bundle in the list of bundles created by you:

- Alternatively, retrieve the list of all bundles created in your organization:

You can also access the details of any created Bundle through the DataOS GUI.
Deleting Bundles
When a Bundle Resource is deleted, it triggers the removal of all resources associated with that Bundle, including Workspaces (if there are any specified within the Bundle definition).
Before deleting the Bundle, you must delete all workloads or resources that are dependent on it. This step ensures that there are no dependencies left that could cause issues during deletion. Once it's done, use the delete command to remove the specific Bundle from the platform environment:

🗣️ When deleting a Bundle Resource, the order of resource deletion is reversed from the order of applying. This is done to ensure that resources with dependencies are not deleted before their dependencies, preventing errors or inconsistencies.
Some sample commands and their respective results
The Apply Command
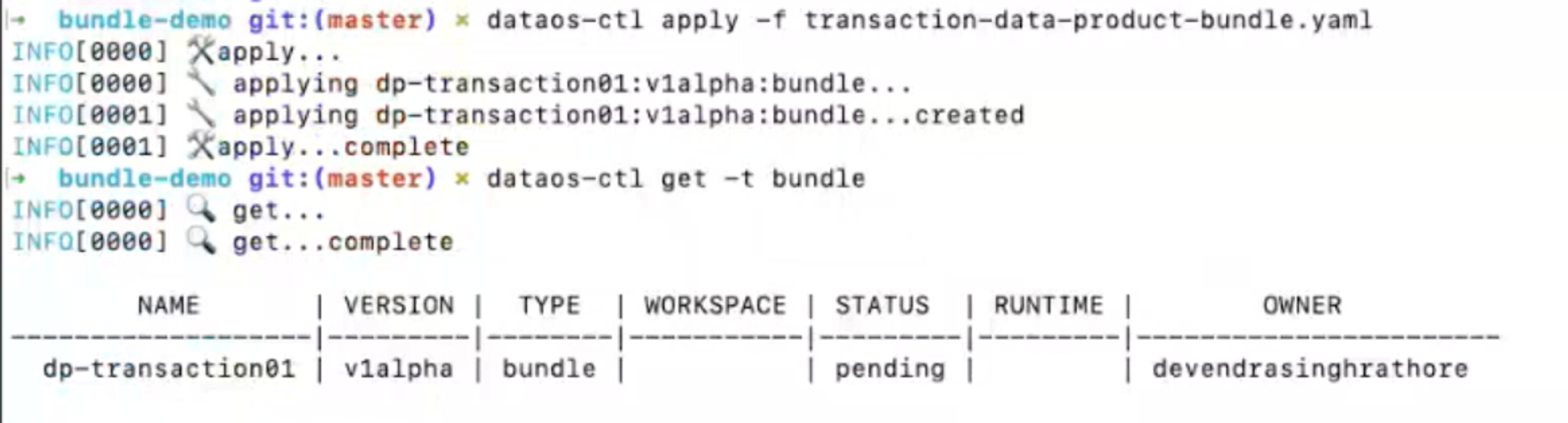
Validating the status of a newly created depot for data ingestion. On applying the bundle, it created one depot since the depot was referenced in the bundle file. Depot is consequently available in a running state.

Similarly, you can check the running and success status of workspaces. See a list of workspaces or all the resources which got created in a workspace.

Similarly, you can check for workflows. Here, one workflow is in a succeeded state. All subsequent resources were orchestrated after submitting the bundle definition.

For bundle:

Surfacing Data Products on the Catalog
The purpose of the demo bundle was to create a source-aligned data product. On deploying the bundle, all the basic details are captured in the catalog. Examples:
- Platform layer used to deploy the bundle: user or system
- Version of manifests
- State of bundle
- A DAG which got curated from the definition
- Resource utilisation, memory, RAM, etc
- Run History
- status of each run (successful, aborted, in progress etc.)
- logical plan of that workflow in every run.
- Job History
- go to a successful run and see the jobs that were running in the workflow
- Status of every job
- go to a specific job and see the topology/ontology or logic used in that job
- basic details of the job to monitor
Such info is available at two levels- workflow and pod level.
A quick demo of how deploying data product bundles instantly populates the catalog with relevant metadata around all the above attributes and more. This enables instant discovery. The catalog is also populated with other resources when they are deployed in isolation or as part of a bundle.

Final Note
The deployment phase is designed to benefit both data engineers/data developers and the end users. To optimally leverage the capabilities of the deploy stage in data developer platforms, we need to be mindful of some approaches to harness the true developer experience in both technical and cultural aspects.
- Adopt product thinking for technical products and platforms (it’s key to understand the responsibility of data product developer and data platform and how they interact)
- Understand your developers’ journeys to identify what limits them in doing their job.
- Shorten feedback loops for developers to improve frequent workflows
- Enable collaboration to eliminate inefficient silos and foster mutual understanding
To learn more about these approaches, refer to Five proven approaches for a better Developer Experience in your organisation by Jacob Bo Tiedemann and Tanja Bach.
Data developer platforms enable you in this journey by giving you the tools to create an environment of high satisfaction for developers. The abilities of DDPs in the context of the data product deployment can be summarised as follows:
- Streamlined Deployment Process Engineer a streamlined deployment process, leveraging containerisation and automated CI/CD pipelines for one-command deployment.
- AI-enhanced Metadata Enrichment Leverage AI to enrich metadata descriptions, tags, and documentation, enhancing data product discoverability and context.
- Dynamic Infrastructure Orchestration Implement infrastructure orchestration for dynamic resource provisioning, accommodating both immediate and future scalability needs.
- Multi-interface Exposition Develop interfaces (e.g., JDBC/ODBC, APIs) for exposing data products addressing diverse consumption patterns.
- Access Controls and Security Design access controls and security mechanisms to safeguard sensitive data, ensuring authorised access only.
- Product Metrics Publication Create mechanisms for data product developers to publish metrics, facilitating ongoing monitoring and iterative improvements.
To learn more about data developer platforms, log onto datadeveloperplatform.org.
Co-Author Connect
We are glad to co-author this piece with Manisha Jain, Lead Consultant at Thoughtworks. She has been a relentless collaborator, and we are delighted to be able to share her expertise with you.








