



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)

TABLE OF CONTENT





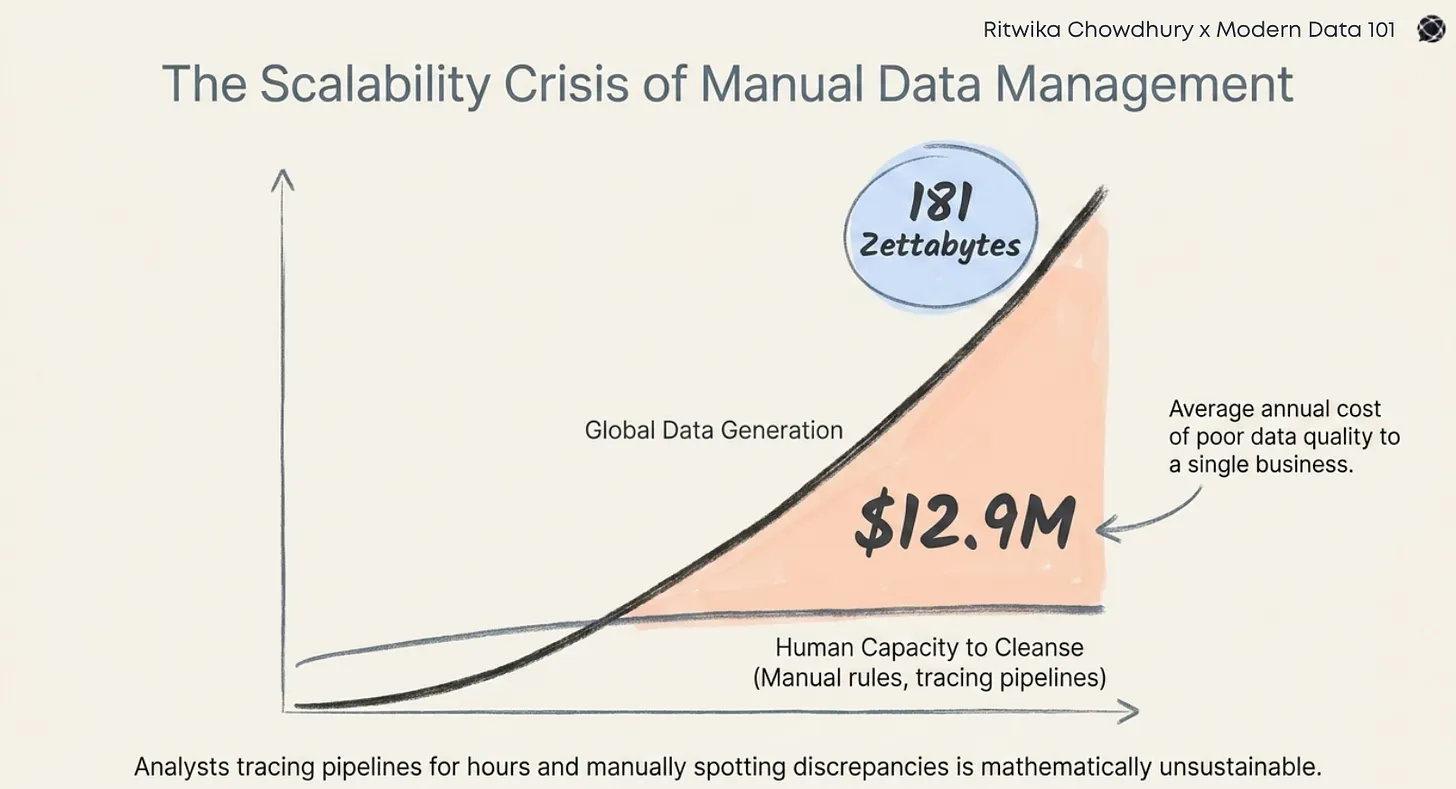
As 2022 drew to a close, ChatGPT burst onto the scene, redefining the boundaries of GenAI and LLM intelligence.
Across industries, this LLM proved to be a boon in no time.

Today 65% of orgs regularly utilise Gen AI . This overarching number indicates a heavy reliance on Gen AI products including the popular LLMs and different enterprise LLMs as well.
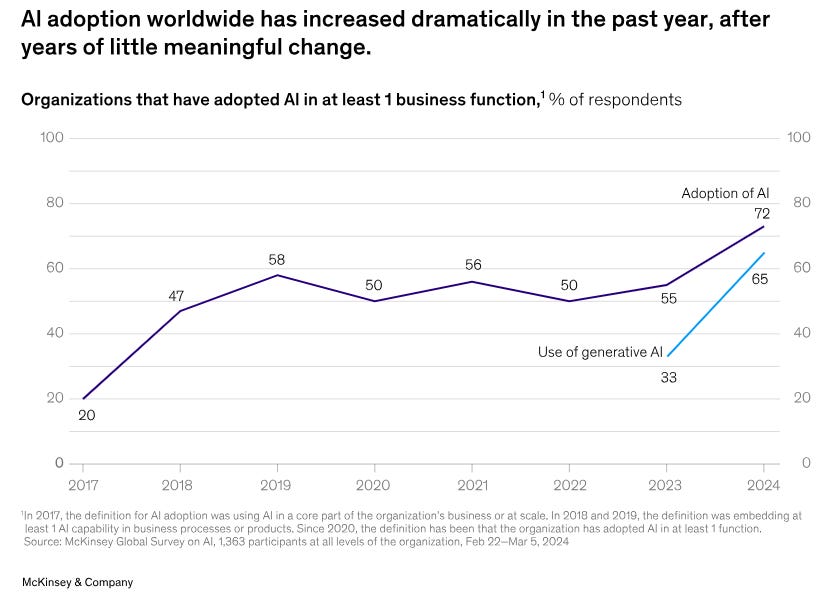
While several public and internal LLMs eased a lot of clerical tasks and fine-tuned tasks across different industry domains, it simultaneously witnessed a rising curve of critical reviews about their poor performances.
Especially when enterprises aim to build their own LLMs, they witness grave issues like a lack of domain-specific context and biased responses.
But should the conventional architectures stop us from building more accurate and reliable LLMs?
No.
It’s time we show the door to the limitations of the LLMs with a new design approach to leverage AI to its most and improve decision-making for businesses.
That’s what we tend to bring to the table with this article.
Through this article, we aim to provide a deeper understanding of why the common LLM challenges occur and how the semantic layer can enhance/improve their performance and reliability.
Most organisations have been investing in these LLMs to revolutionise their customer interactions, optimise and streamline operations, and enable new business models for heightened business growth.
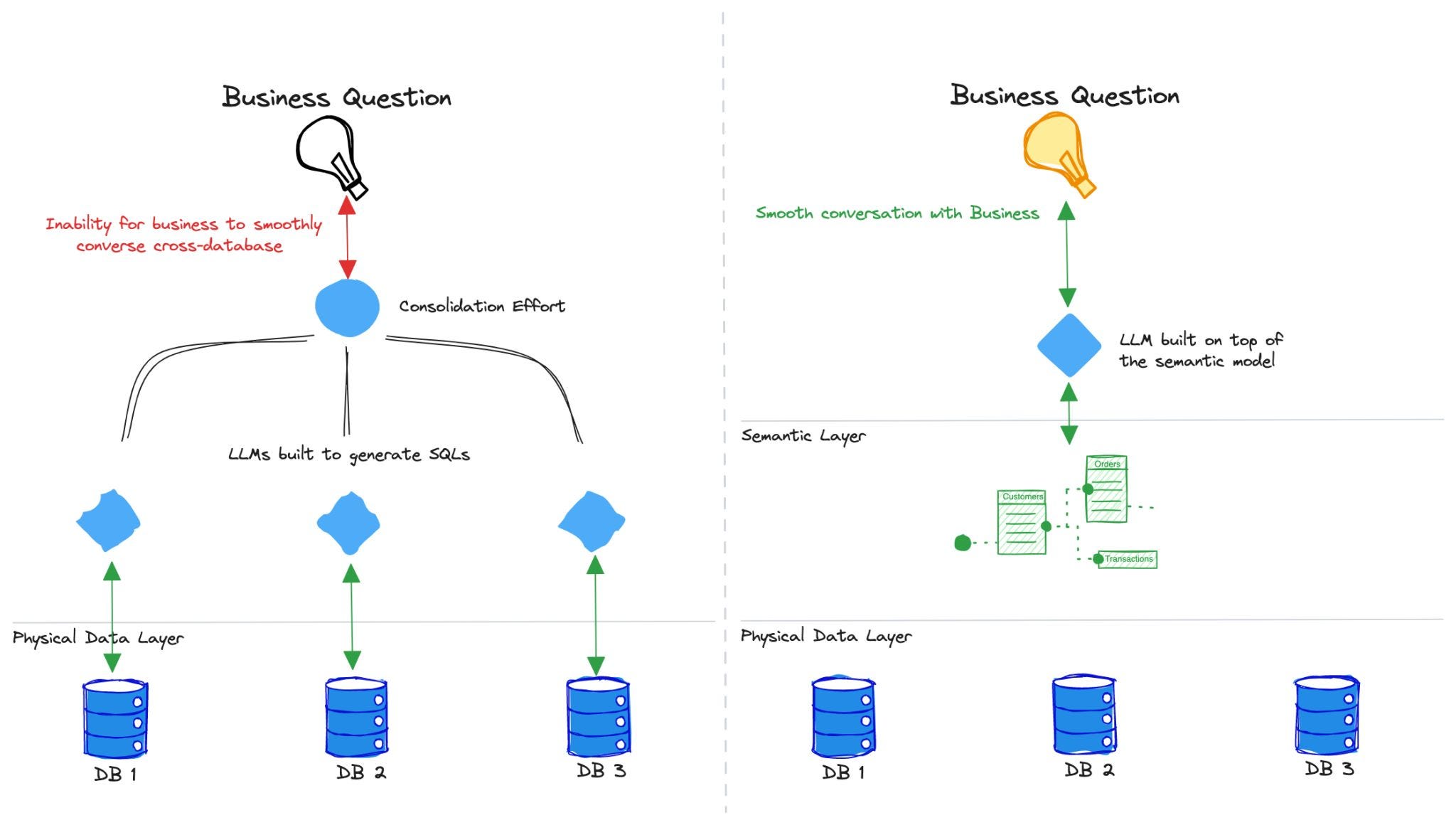
We’ll portray two scenarios while discussing the challenge.
Often, organisations give LLMs access to the vast pool of unorganised data with the assumption that AI will seamlessly do the computing and offer responses to users.
Organisations can approach LLMs in an alternate way where they organise the data into proper catalogues with defined schema and entities. Here, it is easier for the LLMs to understand from where and how to search for the data.
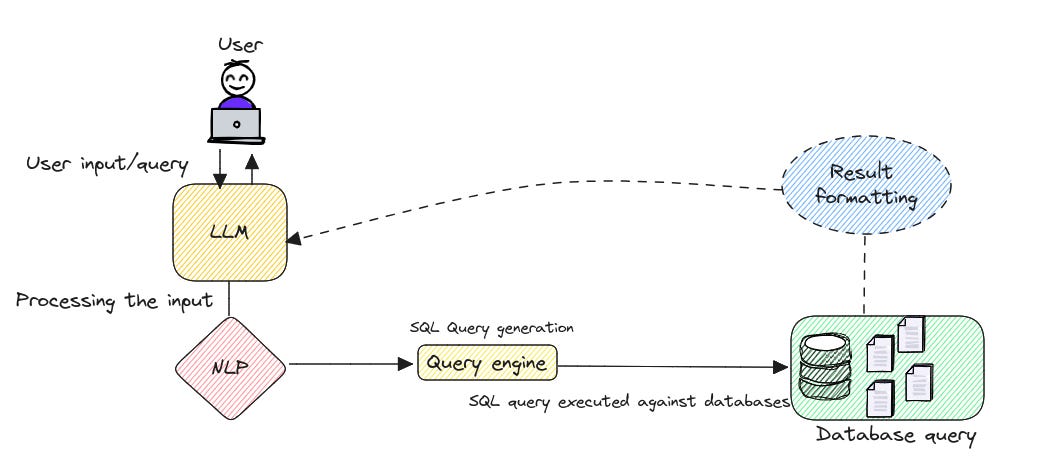
In both scenarios, the LLMs often function like SQL envelopes, generating SQL queries on the data layer that are not precise or optimised for the specific database schema, leading to inefficient queries and poor performance.
These scenarios lead to a number of challenges like:
The garbage-in and garbage-out problem has been at its peak, leading to LLM hallucinations. In scenarios where humans are confused due to inconsistent data and poorly organised data, LLMs will only be even more confused and render incorrect responses.
Unfortunately, more often than not, physical tables lack heavily in context/semantics. For example, cryptic SAP table names such as TRDIR and D010TAB, or domain- or team-specific jargon only comprehensible to a handful of data producers. Without context, an AI is as good as an ignoramus and would inevitably present faulty results with confidence.
As your LLM translates the user input into a SQL and queries the data warehouse there is a lack of context and semantics about the data it consumes. As the LLM fails to comprehend the metrics, dimensions, entities, and relational aspects of the data, users often receive unsatisfactory and vague responses. In several scenarios, LLMs like ChatGPT understand no logic and use pattern recognition to guess the next word, and this leads to severe accuracy issues.
Feeding an LLM with a database schema alone won't yield correct SQL. For accurate and reliable execution, the LLM needs context and semantics about the data. It must understand metrics, dimensions, entities, and their relationships.
If you trail back to scenario 1, you’ll see us talk about orgs that rely entirely on the LLM to deal with the large data sources and do the computing itself. But this AI computing is extremely expensive. The LLMs need to explore all the data, make assumptions, create queries based on their assumptions, and provide responses.
Even when organisations catalogue their data to be used as the LLM’s data interface (as discussed in Scenario 2), there is a huge upfront cost. Often, organisations deal with terabytes of data being generated every minute.
As a result, there is an increased upfront cost for managing such big datasets, algorithms, and compute. Not just the cost but immense time consumption follows.
If you try to drill into the challenges we discussed about LLMs, you’ll notice each of them sprouts from the underlying data layer.
However much you improve the quality of your data and ensure consistency and reliability, the contextual gap triggers inaccuracies in responses and thereby becomes a roadblock in operations.
The crux of the problem is building LLMs directly on top of the data layer.
The LLM's design or positioning needs to be changed as a solution.
The architecture that will solve the contextual problem is to build the LLM on top of the semantic layer instead of the data layer.

This semantic layer powering the LLM organises the data into meaningful business definitions and enables querying these definitions instead of directly querying the database.
Shifting the LLM a layer up in the architecture will not only address that contextual gap but also make the LLMs future-proof as and when developers start leveraging non-SQL interactions.
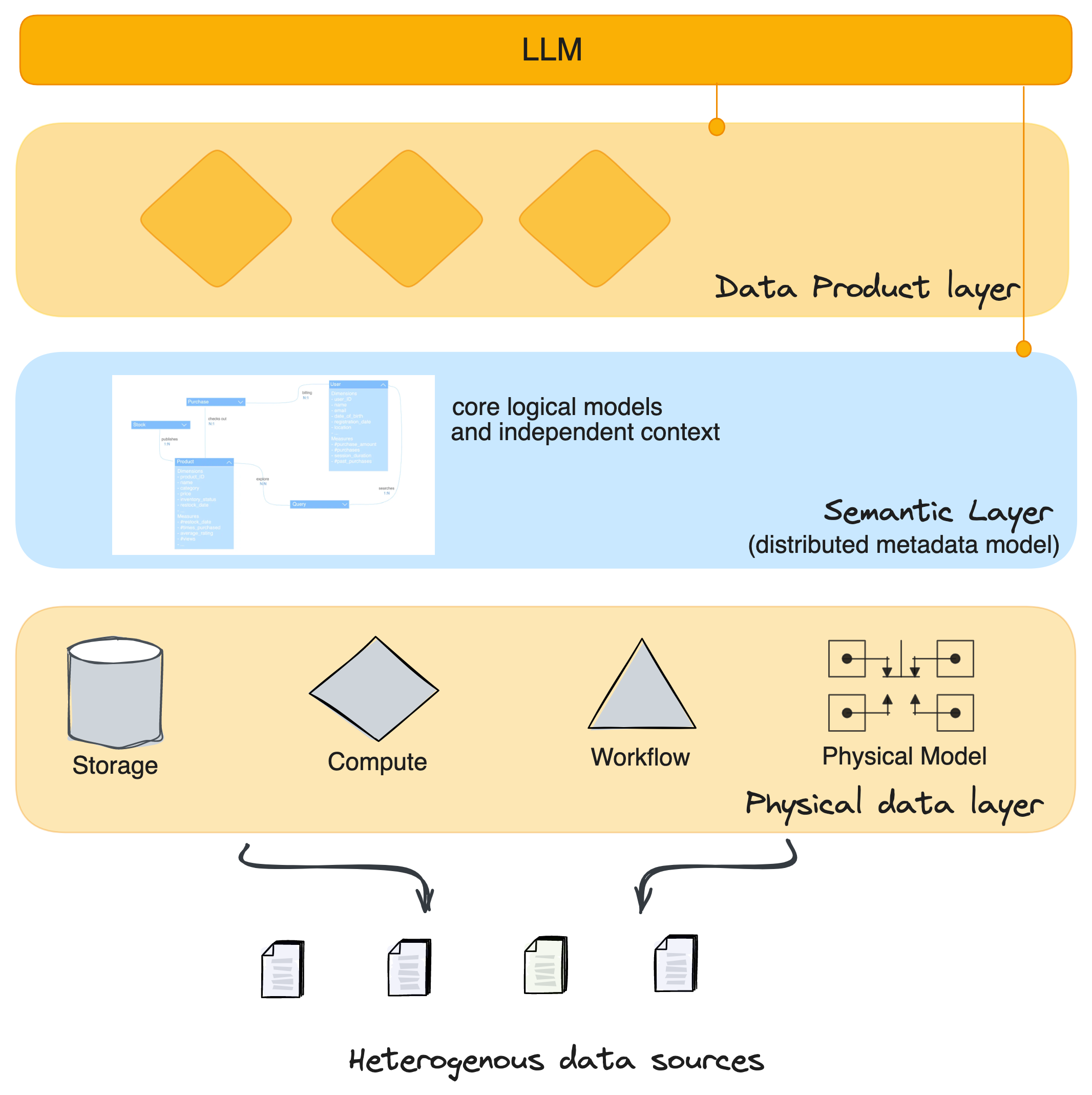
We need the LLM to understand the metrics, measures, dimensions, entities, and different relational components of data that powers response-accuracy. These are all powered by the semantics that adds meaningful business definitions to data and enables querying the definitions or the database directly.
The concept of introducing the semantic layer beneath LLMs is key to improving understanding of LLMs and offering improved responses to users. The semantic layer is positioned right above the physical data layer and below the data product layer, which serves as a data use cases layer.
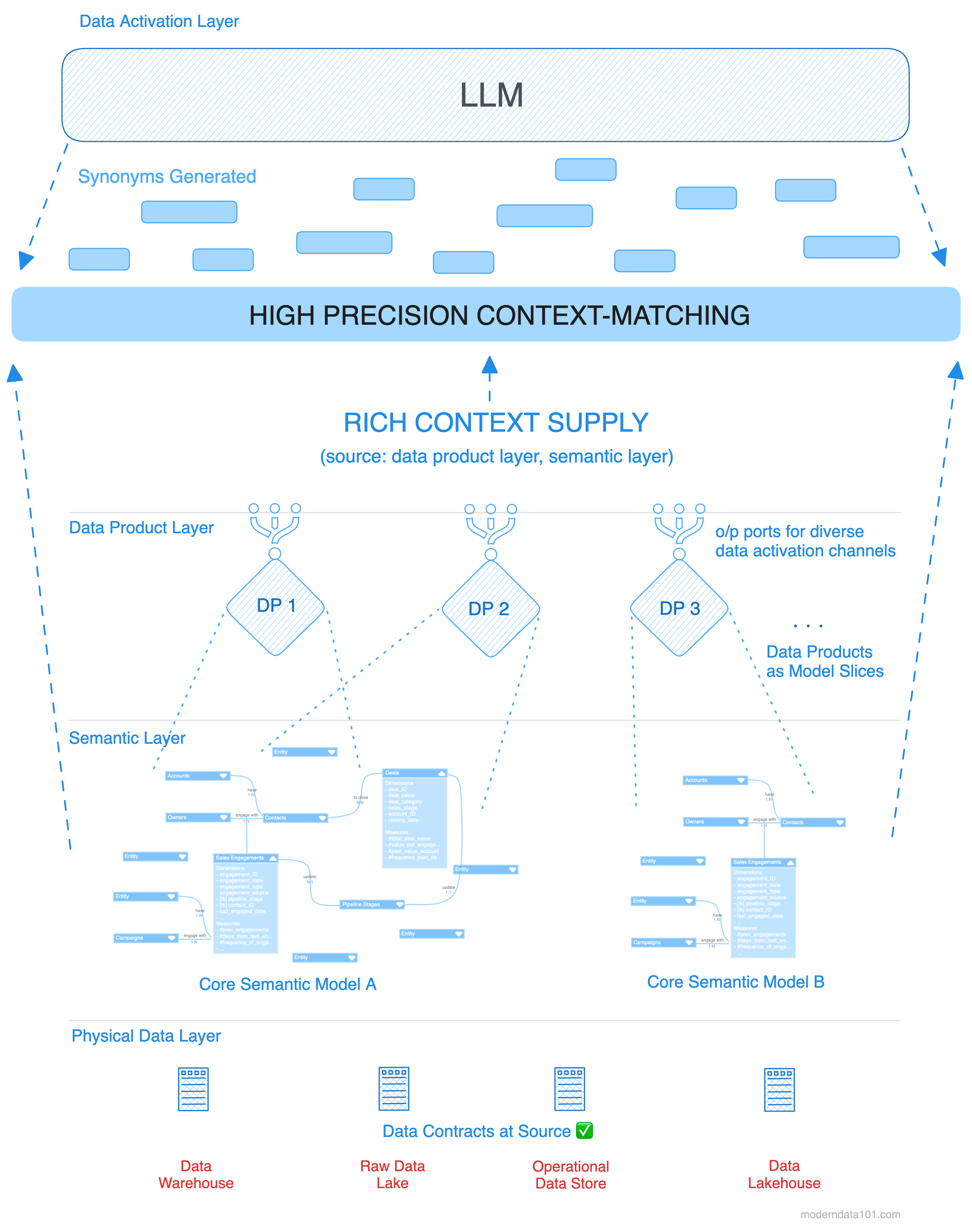
Let’s see how this architecture enables improved LLM outcomes to reduce hallucinations and inaccuracies.
The semantic layer serves as the transition between the data layer and the data activation layer with the help of synonyms and tags. These help users gain an improved search experience with improved accuracy. Let’s see how.
For instance, a customer database might have a field called customer_id, but users might refer to it as Client ID, Cust ID, or Customer Number. The semantic layer can map these synonyms to the actual field, enabling users to query the database without needing to know the exact column names.
Synonyms allow users to interact with the data using familiar terminology. These are implemented through alias mapping, where each business term (synonym) is linked to the corresponding technical field in the database schema.
This mapping is typically defined in metadata repositories or configuration files.
The first step of the language model, interestingly, isn’t to process the data or the semantics. Instead, it receives the input from the user, say which includes a table/entity name, and generates potential synonyms which may or may not apply to the actual table names in the physical data layer (however, it mostly likely is included as context in the semantic layer)
This does two incredible things:
Aligned with the proposed stack? Debate it with your peers! Share
As we know, the Data Product Layer and the Semantic Layer are more parallel and two-way instead of consecutive (or one on top of another). Data Products are built with a model-first approach where the niche model (including entities, metrics, measures, and dimensions) is built to serve specific business goals.
This data product model is derived from heavier core logical models → borrowing entities and context and extending on the same as per the requirements of the use case. This is additional context (say, more consumer-friendly synonyms or descriptions) for the AI model and context that is closer to the consumption/data activation layer.
Therefore, in the architecture, we have shown how the LLM is able to not only interact with the broader semantic layer, but also with the data product layer for richer context and understanding. It is important to note, however, that the data product layer caters to a slice of data (adding richer context), while the semantic layer is broader and is a bridge to the entire physical data layer.
Synonyms are often added as tags, but tags can do much more in the semantics layer to improve the experience of language models and even data consumers. Tags can hold a lot of meaning, including synonyms, related concepts, key impact points (metrics it affect), categories, and more.
Tags help categorize and organize data in meaningful ways. For example, tagging sales data with tags like revenue, profit, and quarterly report helps users quickly identify and access relevant data sets for their analyses.
By tagging data elements with related concepts, the semantic layer can highlight relationships between different data sets. For instance, tagging customer data with high-value customer or repeat buyer helps in identifying key customer segments and performing targeted analyses.
Browsing or running search algorithms with tags as a navigator emphasizes key contextual aspects like descriptive details, offering users or AI a quick overview of the required data results.
The synonyms, tags, and associated descriptions offer semantic information with precise and context-aware results.
For instance, let’s take a simple question: How much revenue did our online store generate last month from US customers?
Possible inaccuracies here when an LLM is asked to interpret this query:
The LLM might—
Commonly, there will be complex SQL queries which may include multiple JOINs
The semantic layer acts like a centralized plane where different entities, measures, dimensions, metrics, and relationships, custom-tailored to business purposes, are defined.
With the semantic layer, the LLM will function with the pre-defined contextual models and accurately project data with contextual understanding, and in fact, even manage novel business queries.
Instead of misinterpreted entities or measures, the LLM now knows exactly what table to query and what each field means, along with value-context maps for coded values.
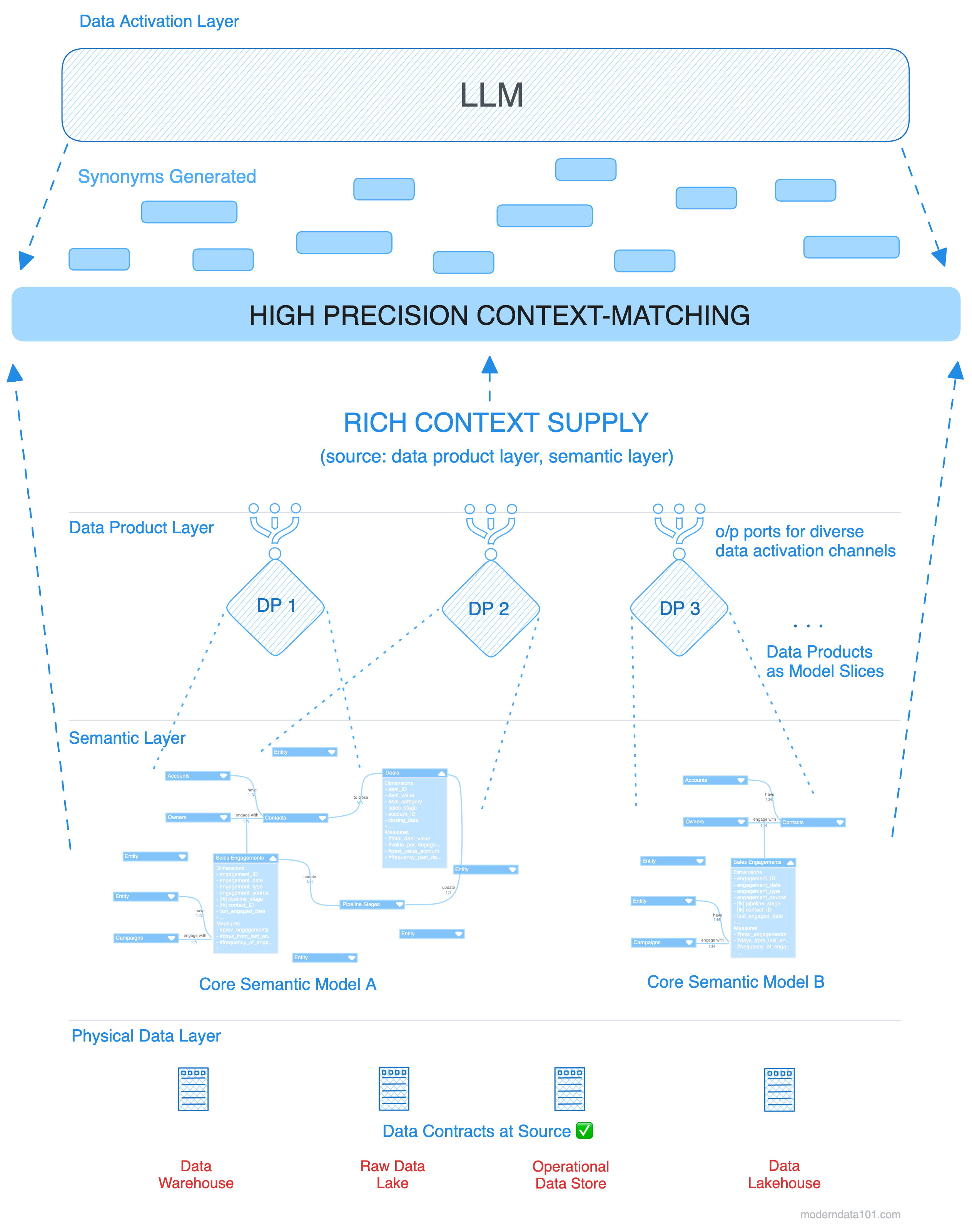
The LLM moves on to generate a precise query for the data analyst (we recommend LLMs not running the queries directly for efficient governance, where policies are best paired with user tags).
The resultant query isn’t a confident assumption but a highly precise query with spot-on hits on the physical data layer.
The interesting angle is that the query generated is cushioned by the semantic layer - it hits the semantic model or the data product instead of the physical layer. These logical models have already consolidated how different core entities of the business are built (from which source tables and through what source transformations), what measures and dimensions each has, and how they are related to other entities.
So now, instead of complex queries with countless JOINs, complex field names, and 100s of lines of costly sub-optimized queries, the LLM, in fact, generates a clean and brief query (easy to understand and validate if necessary) to query the semantic models or the data product.
Example of such a query:
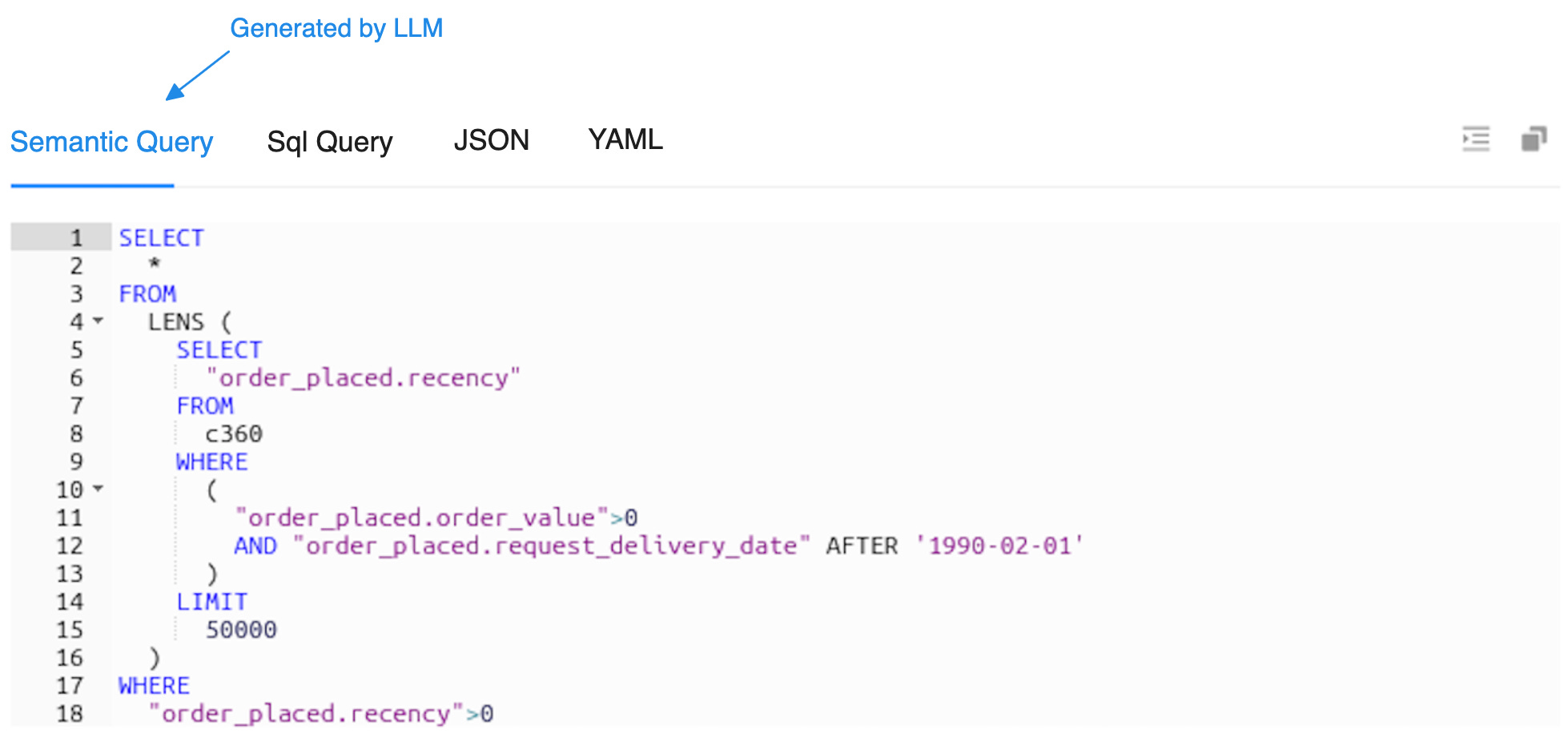
The same is then accurately expanded by the semantic model to establish a bridge with the physical data layer.
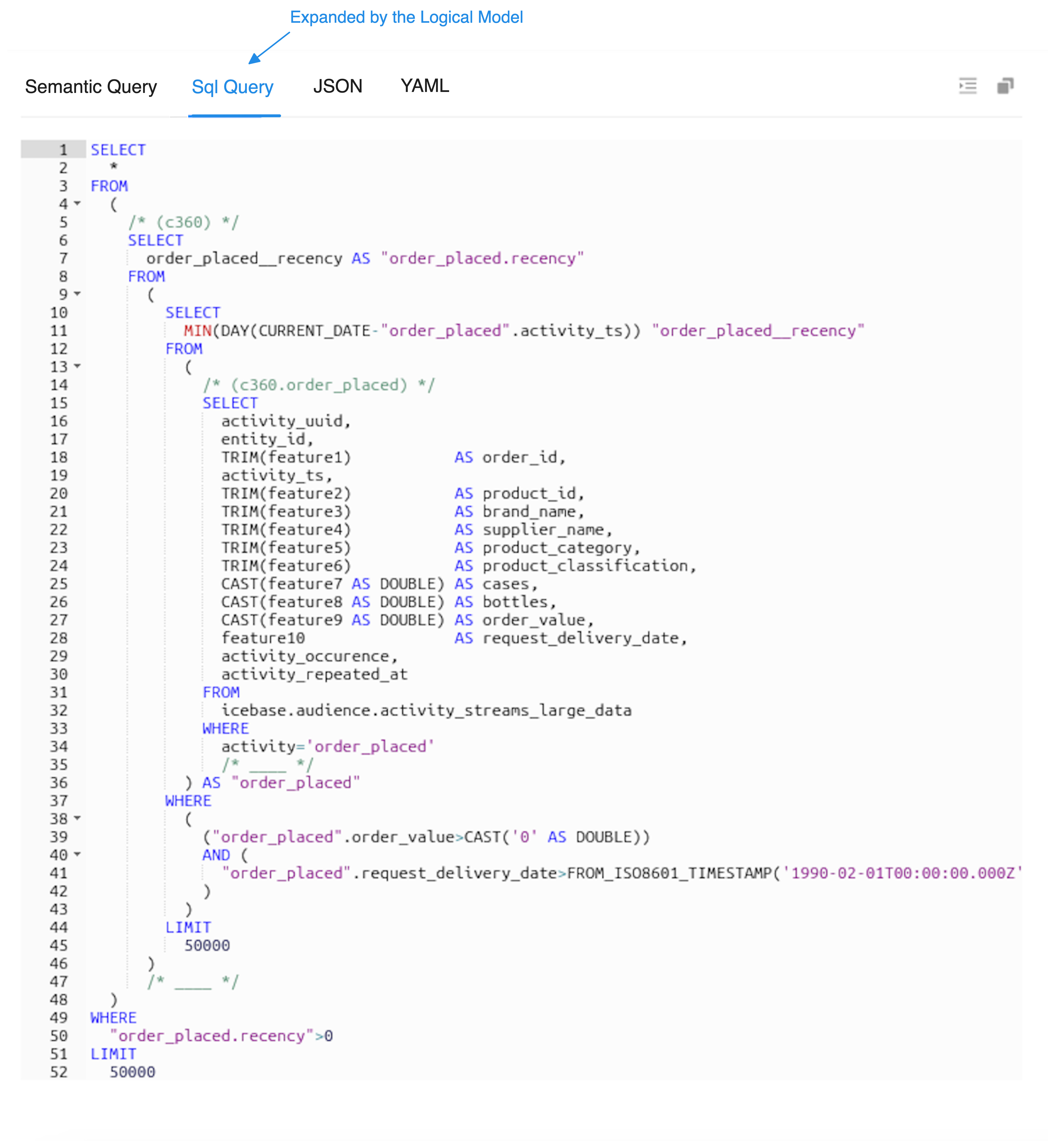
Note the volume of inaccuracies and misinterpretations if the LLM was tasked to directly generate such complex queries by sitting on top of the physical data layer.
🏆 Instead, now the analyst can comfortably slide into their chair and have a smooth conversation with the LLM interface regarding any business query that would help their day’s tasks or catalyse their goals - without having to worry about potential faults or validations coming up.
Not just limited to the LLM space, but the semantic layer is reforming the entire data modelling picture today. The semantic layer is a two-way street where users/data consumers/domain experts can add or modify contextual information, which offers the flexibility to customise the logical models much before feeding the real-world data and validating the results.
With predefined metrics and entities, feedback can be directly incorporated into the semantic model, ensuring LLM responses align with user expectations. Additionally, the semantic model can be updated based on feedback, allowing the LLM to continuously improve its understanding and accuracy.
With LLMs working atop semantic layers, more queries can be handled quickly and accurately. This reduces reliance on data teams for each request, allowing them to focus on strategic and complex tasks.
Integrated LLMs and semantic layers provide fast, accurate data results, enhancing decision-making across all departments with reliable insights. This improvement enables faster responses to market trends and more informed strategic actions, optimizing organizational outcomes.
Relying on LLMs built with a semantic layer helps to cut significant compute costs otherwise required for organising datasets. LLMs can directly access curated data, minimizing redundant computations and speeding up data retrieval processes.
If you trail back to the second scenario we discussed, orgs end up cataloging datasets and organise it properly to improve search for the LLMs. But with the semantic layer, you don’t need to move your data. Your data remains untouched in the database while logical models are built on them to fuel any application, in this case, the LLM. This again leads to cost optimisation.
Generating raw SQL and executing it directly in a data warehouse can lead to erroneous results. Moreover, AI introduces an additional risk by potentially generating arbitrary SQL, posing a security vulnerability when directly accessing raw data stores. Utilizing the semantic layer for SQL generation ensures robust implementation of granular access control policies, effectively mitigating these risks.
Your marketing or sales team, which once heavily depended on data analysts and scientists for analytics, now have the ability to independently access and interpret data. This accelerates decision-making processes and boosts overall efficiency.
One of the most extensive drills for conventional LLMs in the business intelligence space has been the contextual understanding or the business-specific context.
For example: terms like ‘visitors’ and ‘order category’ might have different interpretations based on specific business requirements. Incorrect representation of data from here on can lead to poor business decisions. The LLM powered by a semantic layer turns this around!
Irrespective of from where this data is pulled from or how it is interpreted, a semantic layer adds a standardized meaning based on precise business context of different domains. This reduces the dependence on data teams and allows the business teams to seamlessly integrate their BI tools with LLMs to obtain tailored business context.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.


Find me on LinkedIn

Find me on LinkedIn
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



