



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.png)

TABLE OF CONTENT




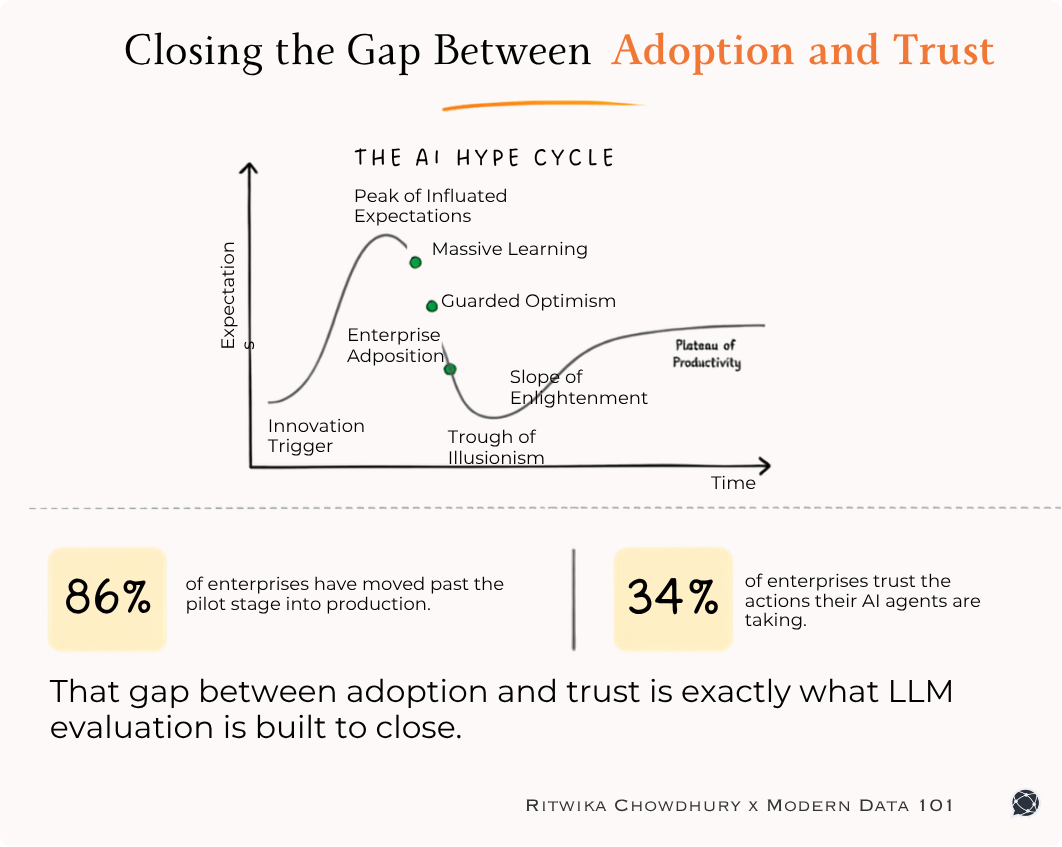
The objective of data products in itself is purpose-driven, which means every data product is built to cater to a business problem or purpose, and in fact, involves ‘outcome-first’ modelling where the business goal is set forth as a north star and then the rest of the pieces are put together to bring life to the product.
Delineating the purpose first automatically bridges the gap between business needs and data initiatives. It consistently designs your processes to be customer/user-centric. Model-First Data Products utilise the power of semantic modelling to add context to the data, ensuring it aligns with that defined purpose.
This targeted communication fosters a deeper understanding of the information and empowers data products to deliver true customer-centric solutions. Let’s see how this purpose-driven ability of data products can help purposes like cost optimisation and improved revenue flow.

Implementing the right strategy for building data products involves identifying the primary business objectives, or what we often call the North Star goals. These guide us until the end of the cycle, when we can evaluate whether and how the data product was a success.
Metrics like ARR and Revenue, no doubt, are prime North Star Goals for any business. Every function/domain strives to pump these goals by enhancing their distinct north stars or functional metrics like %Target Achieved for Sales, #MQLs for Marketing, or NPS for Product.
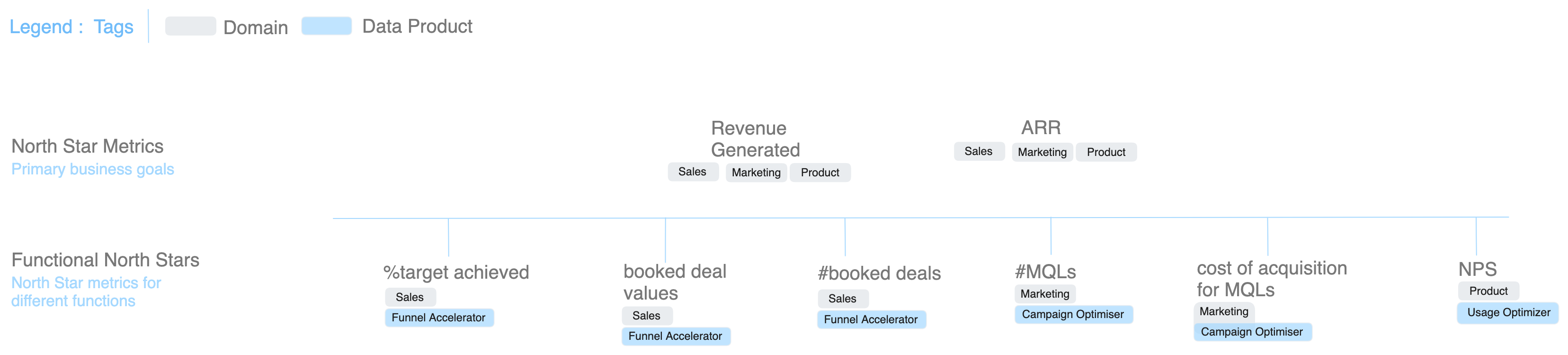
With the goals defined, come the questions that take you a step closer towards the goals. These core questions enable the data product developers to find a way to build their data products to meet the business objectives. And finally, the answers to these questions take a quantitative shape to become the metrics.
For instance, let’s consider a company with two key domains: Product Development and Customer Success. Their common goal might be to reduce customer churn.
Teams might be asking questions about the following:
To answer these questions, the product development team can run analytics to identify features used by less than x% of users and features raising y% of tickets. Eliminating these features can help reduce the number of tickets and increase overall product usage %. On the other hand, sentiment analysis of support tickets could identify customers expressing frustration (sentiment score). Proactive outreach to these customers can decrease the churn rate.
This can help delineate metrics like feature usage rates, support ticket volume, customer churn rate, customer sentiment score, and others.
This brings us to the granular metrics that pump the functional metrics of different domains. For example, a higher usage rate, lower ticket volume, and a positive sentiment score help raise the NPS score governed by Product-led data products.
📝 Editor’s Note
Learn more about Metric Dependency Trees (North Stars to Granules) here
Now that we have an idea of how to dig up metrics from North Stars to Granules, it’s important to note that it’s not a one-time process. With more business questions that highlight new goals, the metric tree would grow and evolve (with the Data Product). Does that mean Data and Analytics Engineers need to drop everything and spend modeling efforts every time a new query comes up (as is usually the case)?
This is where Model-First Data Products come in to quench the unending business curiosity.
Metrics-Focused Data Strategy with Model-First Data Products | Issue #48
Consider you’re a FinTech firm building an AI feature for your clients that helps them predict their customers' payment dates. This feature does well with a data product that collects customer data from different sources hosted by the client, runs quality checks, applies policies, and projects the transformations demanded by the prediction model.
Now the same solution is demanded by a couple of new clients. All you need to do is extract the data product template and feed in new parameters that are not already similar (new or different sources, SLOs - quality & policy, transformation steps), and you have a ready-to-go data pipeline that feeds reliable data into your prediction models. It’s especially a huge time saver, given how it replicates the underlying tech stack (infra + code) in a new instance. Think environments, dependencies, resources, and so much more.
Consider a situation where one of your existing data products becomes of direct utility to a client, or maybe a data product you have built for your internal purposes but can be accessed by a tier of your clientele who find your DP useful for them.
Let’s picture this!
You have a data product built to optimise the performance of a fraud detection application and improve the customer experience. This product utilises data from disparate sources to analyse customer behaviour, purchase history, and various data points to identify and prohibit fraudulent transactions. Your company will significantly reduce the number of fraudulent transactions, saving millions of dollars annually and ensuring a more secure experience for legitimate customers.
📝 Editor’s Note
Learn more about internal data products here
But while the initial purpose was internal, these functionalities, combined with the anonymised historical fraud data, could be highly valuable to other companies facing similar challenges. You could now create a new data product specifically for external clients. This product might be sold as ‘Fraud Detection as a Service (FaaS).’
For the other company, subscribing to FaaS is likely more cost-effective than developing and maintaining their own in-house fraud detection system. Data products can be sold directly to customers through subscription models, pay-per-use pricing, or one-time purchases. This allows you to capture the value of your data and directly generate revenue streams.
Traditionally, data monetisation focused on selling raw data sets or access to data pipelines. However, a new wave of data product offerings unlocks direct monetisation opportunities. Here, data products themselves become the revenue driver, directly consumed by external users.
Being metric-first and starting the approach by modelling the user requirements first takes you a step closer to meeting your customers’ expectations. In traditional data management systems, organisations usually rely on centralised data and ownership.
With approaches like data mesh and their core components like data products, the strategies involve decentralisation and distribution of responsibilities on the basis of the proximity of a team towards the customer or data consumer (customer-facing teams). With this shift in approach, organisations tend to revise data ownership, which helps them avoid the gap between dynamic business changes and data efforts.
Data mesh architectures are a cost-effective way to serve data products to a variety of endpoint types, with detailed and robust usage tracking, risk and compliance measurements.
Data products, in nature, are discoverable entities. A commonly arising challenge of most analytical data architectures is the resistance and high cost of discovering, understanding, accessing, and leveraging the quality and real value of the data.
A data product holds three integral components:
Of these, the metadata slice enables discoverability by offering the users the required information to discover the data products and all embedded artefacts, of course, with necessary governance policies (e.g., masking from certain users).
The common practice within a data platform is to maintain a catalogue or a central registry for all data products, providing key details like ownership, source, lineage, and sample data. This facilitates discoverability for engineers and data scientists, allowing them to find relevant datasets easily. Each domain’s data product should register for inclusion, ensuring comprehensive coverage and a single source of truth.
Thus, the anticipation of the high cost of discovering and using data is eliminated. Additionally, with data silos being removed, there is improved resiliency and scalability that helps address the cost of operation.
A Self-Service Infrastructure (SSI) has a significantly impactful role in bringing any data product to life. Self-service = having resources ready to use based on the user requirements (from analytics engineering in this case). Example: The analytics engineer only declares i/p o/p locations and transformation steps for data mapping, and the SSI furnishes ready-to-use workflows, services, secrets, i/p & o/p connectors, monitors, and other such resources to run the transformation.
Examples of some self-serve resources in a self-serve infrastructure are workflow, service, policy, monitor, secret, compute, cluster, contract, and others. The analytics engineer needs to only write declarative references to the resources to put together the four pieces of the product generator (i/p & o/p ports, SLOs, transforms).
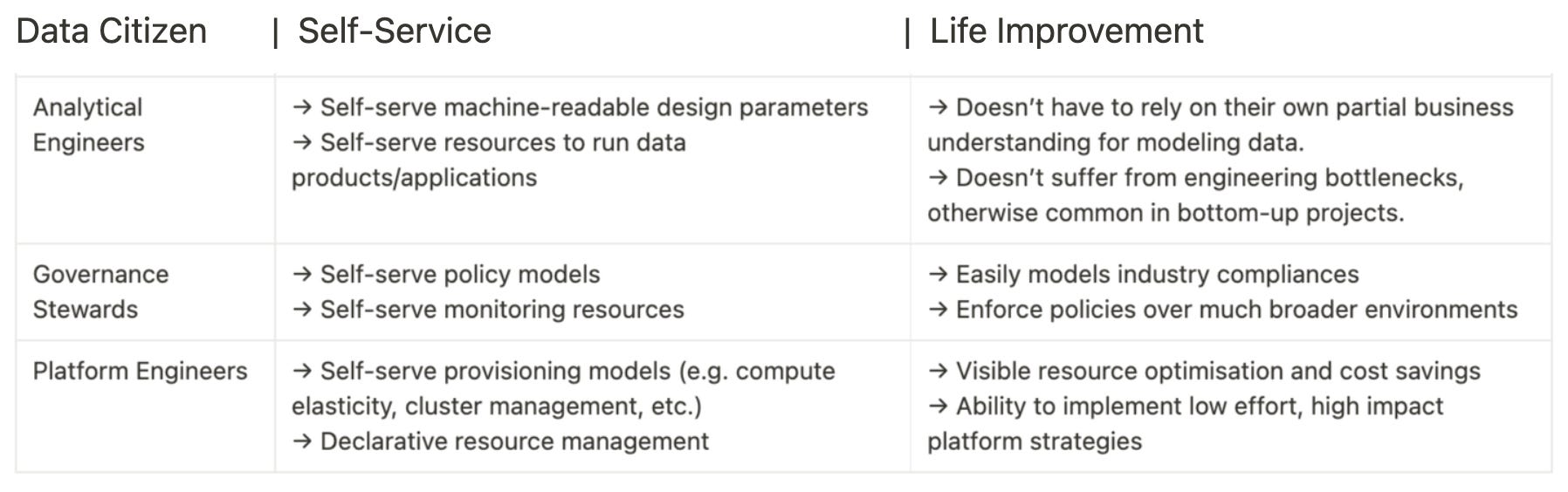
This enables effective cost optimisation in terms of reusable resources, reduced effort in building pipelines and configuring resources from scratch, and configuring deployments & environments which are otherwise reproducible in data product ecosystems.
The importance of making decisions is everywhere, even in businesses. Businesses run on decisions; their revenue, clientele, brand reputation, and industry position are not about luck but the innovative plans they have laid and the rock-solid decisions they have made around executing their ideas.
Becoming data-driven doesn’t mean data will make your decisions, instead, it will power the decisions YOU make. When the concept of data products first emerged in the data space, its disciples were hopeful that these could improve business decision-making. And they did so!
By focusing on metrics and domain ownership, data products have enabled organisations to optimise data strategies and make better investment strategies. The data-first approach offers crucial insights into user behaviour and improves user adoption while enhancing resource allocation.
This has largely helped businesses make better data-driven decisions to optimise the value of their data assets while ensuring compliance. The insights and analytics provided by data products, by improving data-driven decision-making, also allow for the reduction of costs of wrong decisions while improving overall business performance, which in turn again generates increased revenue.
Now that we understand how data products enable organisations to improve their revenue growth, we need to understand the elements needed to build effective data products. At the core, a great data platform is modular, extensible, interoperable, and customisable.
You can read more about the fundamentals of a data platform here.
The Essential "Personality Traits" You Need in Your Data Platform | Issue #40
Data platforms are the makers of your data products—from data ingestion to processing to building, deploying, and evolving them based on user needs and market trends. This comprehensive functionality ensures that data products reach their full potential, delivering the insights and capabilities that drive revenue growth and propel businesses forward. By fostering a data-driven culture and leveraging the power of data products built on a strong data platform, organisations can unlock a treasure trove of revenue opportunities and gain a significant competitive edge in today’s data-centric world.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


