




TABLE OF CONTENT
AI/ML injected itself visibly into mainstream enterprise use cases not more than 4-5 years ago. During the initial phases, all the departments and “AI Leaders” were mercilessly focused on delivering valuable proof of concept (POC) projects in record time to onboard paying customers.
This meant customer data was loaded by the organization on an ad-hoc basis when the need arose to target and solve specific problems by the promised hour. This led to a couple of problems which were managed in silos to maintain the promised metrics and uptimes.
Now let’s fast forward 2-3 years after those POCs when these very organizations had onboarded a significant group of customers for their AI/ML sidecars. While the AI/ML suites scaled, the problems that resulted from ad-hoc practices scaled at twice the rate. And “twice the rate” would just be an expression; the problems, in fact, scaled at a much more significant rate.
Miscommunicated change
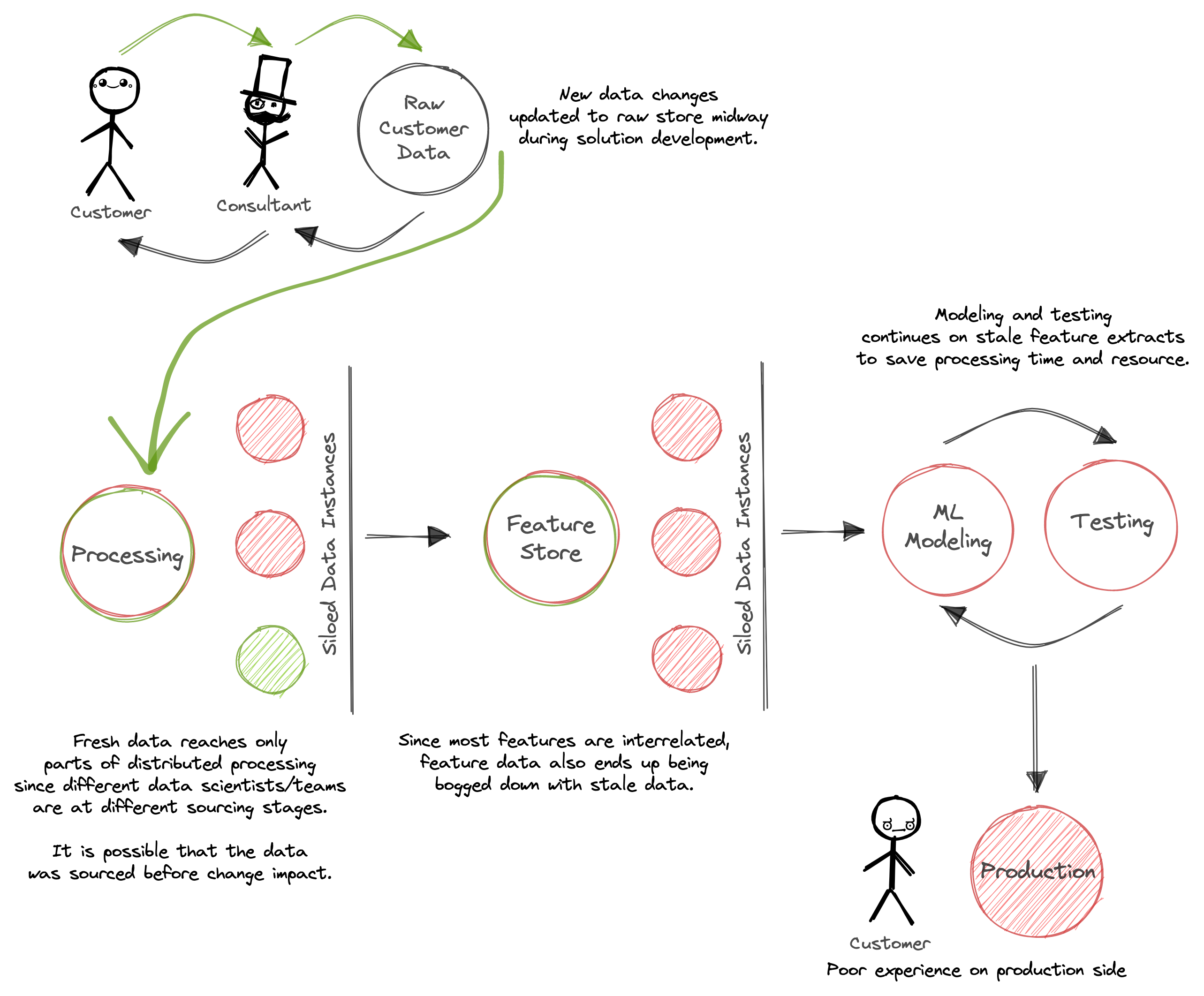
Data for AI/ML use cases were mostly sourced by Consultants who had to-and-fro communication with the customers. They were the ones tagging the data with taxonomy and meaning. However, this is never a one-time process.
The nature of organizational intelligence is dynamic and keeps evolving, but with every iteration of change, the information diffs weren’t distributed uniformly. Primarily because of siloed data and secondly because of no system in place that could perform the feat.
This led to data teams moving far ahead with their solutions with stale data and then having to come back again to repeat the process with the fresher version that would go stale again.

Differing Taxonomies and Mismapped data
Every team had a way of identifying data and tagging it in their respective dialects. A perfect and simple example of this confusion would be transactional data. ‘Credit’ and ‘Debit’ could mean one thing for the collection department and the opposite for the payments department.
The problem was that initially and even today, all the data from across departments channeled into the hands of data engineers and, consequently, the ML teams. If the points of difference for such use cases weren’t carefully communicated, one can imagine the mess.
Especially when every data asset wasn’t typically governed by central authorities or systems and came right to junior data scientists or engineers whose sole task was not to question the integrity of the source but to process what was at hand.

Siloed experiments and Versioning Casualties
AI/ML solutions have a tendency to get naturally siloed due to the nature of the solutions. This happened especially during the feature generation and modeling phases when scientists prefer to work on prepped data instead of devising feature functions that would refresh features with the latest data. This is done to save processing time because certain feature calculations could take a few minutes to a few hours.
Due to such unavoidable siloes that are stretched out for significant durations (ML modeling experiments could be endless), key changes to data meaning or schema are easily missed. ‘Lost in translation’ across countless versions of features and models.

Fragile production environment
When a working model is launched into production, it doesn’t take much time for the data to get stale, and this is a problem when data is available in ad-hoc servings, disconnected from the primary bloodstreams. An ML model that was performing brilliantly in the testing and validation phases suddenly starts defaulting to subpar results as soon as it’s uploaded in production. And the emphasis is the fact that “as soon as” is not an understatement.
The customer has to bear the brunt of this and be completely exposed to ungoverned data, disparate changes, and thereafter, unreliable results that directly affect their revenue and relationships with their clients.

How can Data Modeling Resurrect the Situation?
Data modeling is not a new notion in the world of data, but that isn’t really the case when it comes to the AI/ML space. Due to how the field developed on top of the pre-existing corporate infrastructure - on the fly to serve demands triggered by the ML bubble to stay on top of racing competition, ad-hoc and siloed data was common, resulting in the flood of problems we discussed above.
If you asked any data scientist during the first 2-3 years of this boom, they would be stuck in the narrow loop between customer data extracts to ML model production. But what about the gigantic data management layer? Or what about the quality and governance of that data? Most of them would have no idea.
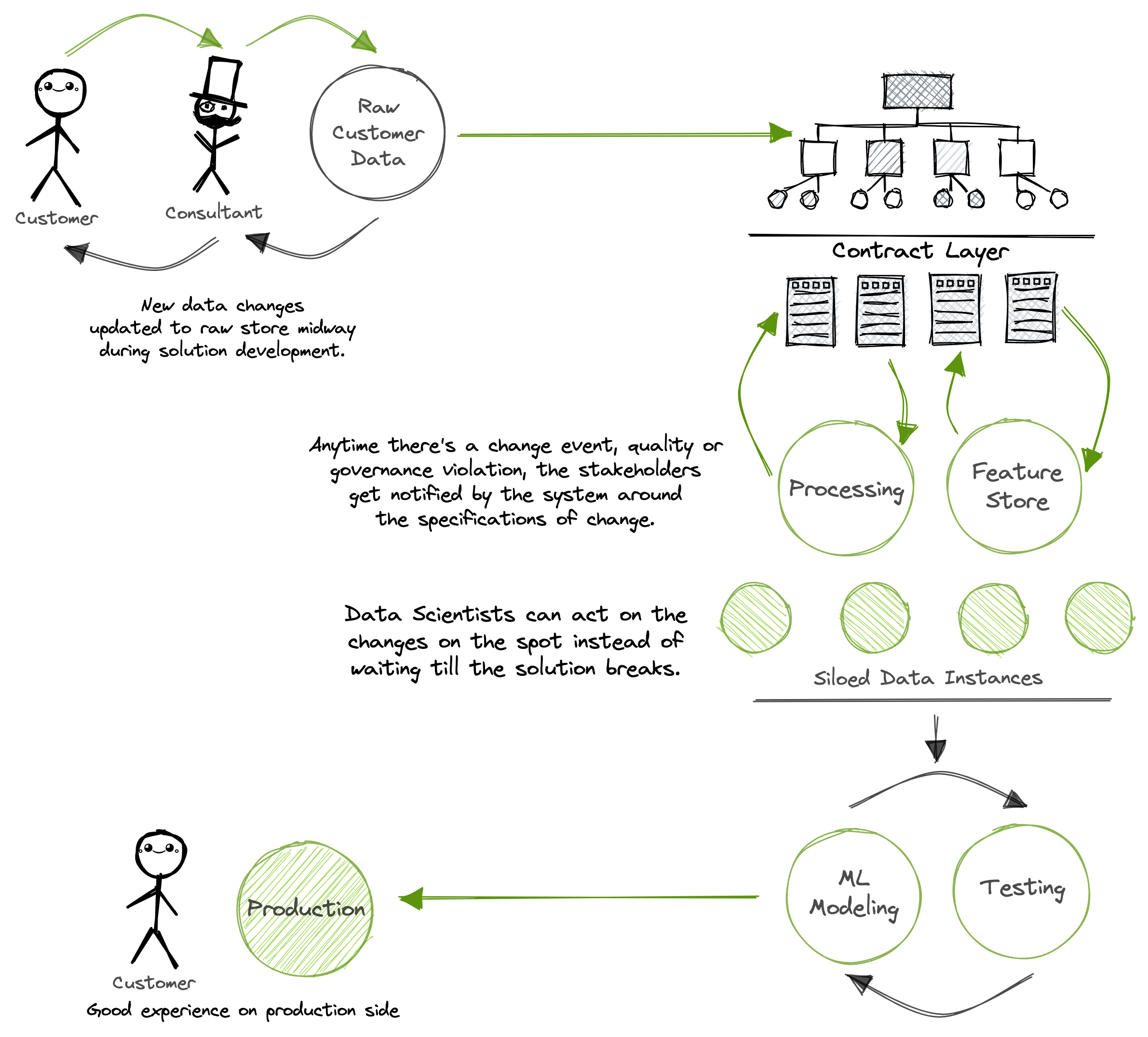
Data Modeling in unison with contractual handshakes could be a game changer in tackling the problem of unavoidable silos by ensuring that stakeholders working on isolated data are alerted around:
- Schema changes: Changes in column names or data types
- Quality changes: Changes in the integrity of the data. Eg.: missing value checks
- Change of business logic: Changes in business assertions or conditions for the data
- Policy changes: Changes in access or masking requirements
And all of it without having to run frustrating iterations with business teams and consultants. The system creates a declarative padding to capture and distribute the evolving data across the right endpoints.
Causal Intelligence
Above all, data models enable clarity around causal relationships. Causation is key to ML feature development, and having a web of all potential triggers for a desired outcome, which is the data model, enables ML scientists to discover causation and double down on powerful features.
Data models also ensure cross-domain interactions to narrow down the right set of potentially triggering events. This is feasible declaratively without the need for physical teams to establish separate communication channels that are iterative and buggy in nature.
Sourcing the right data
ML teams have the capability to define all the data requirements to solve a specific use case even before the data is sourced by consultants from the customer side. The consultants could refer to the demands of the data model and accordingly interact with customers to get data according to the specifications.
In common scenarios, consultants do not have much visibility into the specific low-level requirements. They might come up with a requirements doc, but when data is collected on that ground, several iterations follow to ensure the ML team has the breakdown of derived data or additional columns that add more color to the use case.
Transparency of change
A data model ensures that the right relations and metrics are highlighted among entities. Any upstream change event can be quickly traced back, and the consequent downstream impact will instantly surface.
ML teams can then either model their process accordingly with no delay caused due to lagging communication, or they can push back the change to consultants to reverse the impact. Customers can also be involved to have more clarity on the change and send data accordingly.
Prevention of data swamp
As we discussed above, over the years, ad-hoc or siloed data can mount up to create a data swamp where rich data is stuck and unused just because there’s no semantic information around it. Semantic information could include provenance, lineage, business context, and general metadata.
With data models in place, as defined by AI/ML teams, the data is integrated with an underlying knowledge base that keeps track of all the integration and exchange points to ensure the story does not get lost in a swamp.
Contractual guarantee
Contracts are the pillars of data quality and governance. Any ML team will unanimously agree that even state-of-the-art models would fail if the data is not state-of-the-art in the first place. There are not many practices in place today that guarantees quality and security for such data that channels into ML use cases.
Enter contracts. Contracts offer a way to enforce specifications that are expected from the data. These expectations can be in the form of business meaning, data quality, or data security. Think of them as guidelines or an agreement between data producers and data consumers that documents and declaratively ensures the fulfillment of data expectations.
Universal taxonomy
Data models and contracts are a way to neutralize discrepancies in data tagging without introducing barriers to data operationalization. Data modeling could be considered the SSOT (single source of truth) - not for the data, perhaps, but for the logic and taxonomy governing that data.
Contracts allow a way to enforce the universally defined and accepted semantics in the data model. Deviations from the taxonomy standards accepted by the organization will be flagged or obstructed based on the contract configuration.
Stabilizing “unavoidable silos”
Due to the computationally expensive processes around the data required for ML solutions, running operations in silos is unavoidable at times. However, while the data is siloed, the stakeholders working on it are not. The sources, such as the processed store or the feature store, are not siloed.
Any change or discrepancy noted in and by these resources through data modeling and contractual practices goes a long way to save weeks to months of wasted efforts and time. The production phase arrives faster, is more stable with minimal maintenance requirements, and finally, most important of all, the customer is not frustrated.

Since its inception, ModernData101 has garnered a select group of Data Leaders and Practitioners among its readership. We’d love to welcome more experts in the field to share their story here and connect with more folks building for better. If you have a story to tell, feel free to email your title and a brief synopsis to the Editor.






