



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...
%20(1).png)
.png)
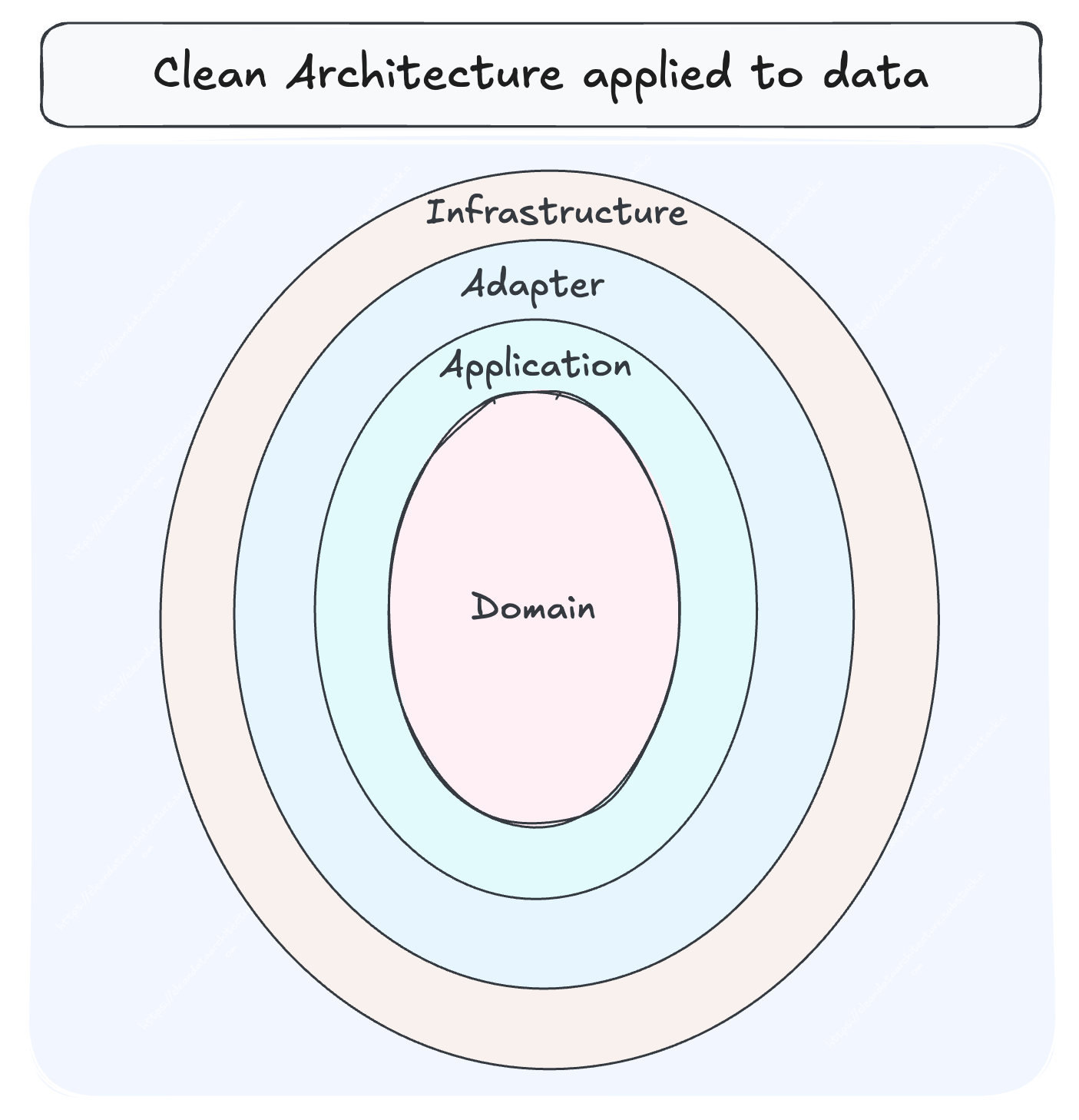
TABLE OF CONTENT




Big Picture at a glance
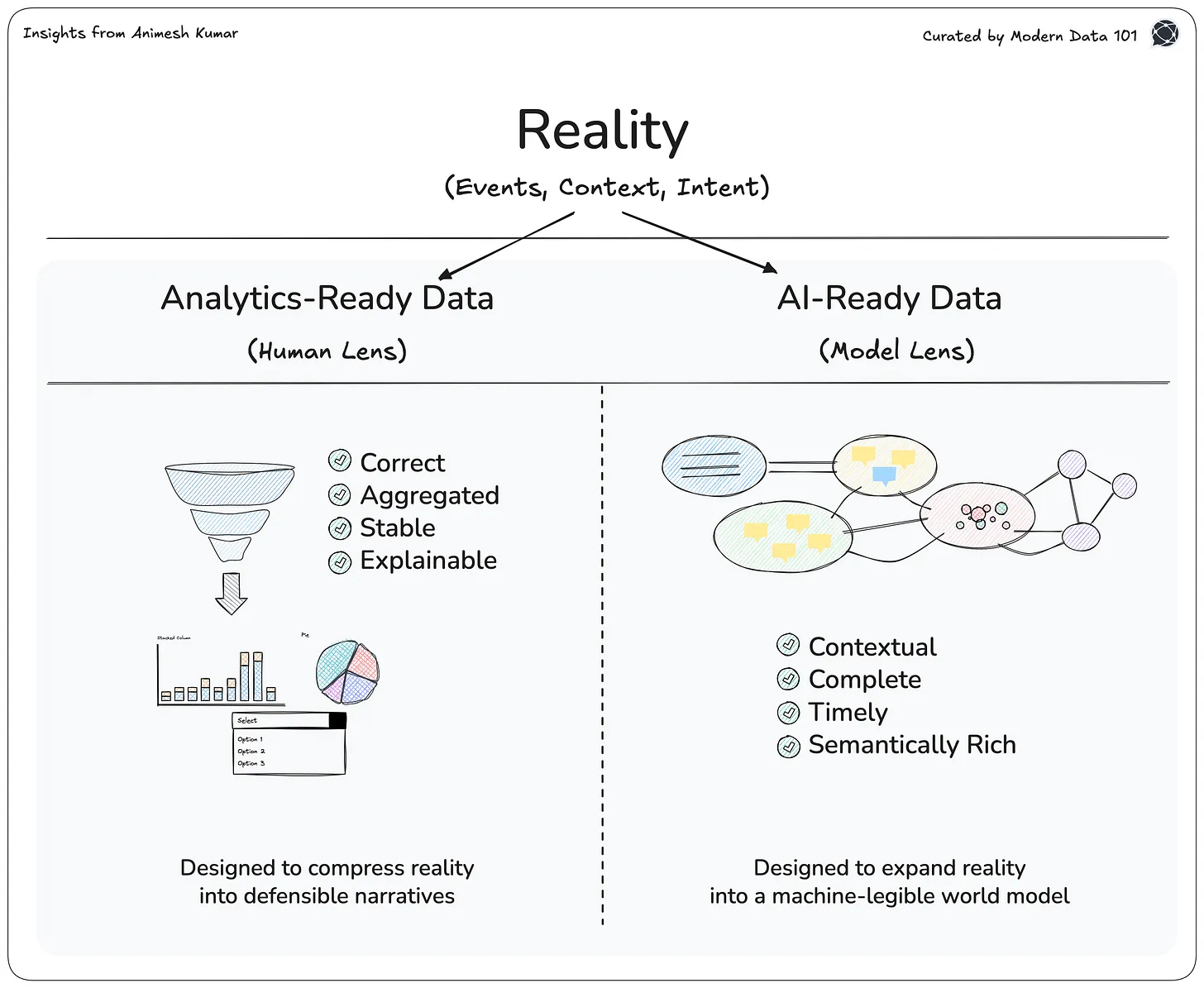
What is the job of a data model
Understanding Data Product as a solvent for Modeling Challenges
- What is a Data Product
- Visualising Data Products on a DDP Canvas
- How Data Products resolve challenges in data modeling
Let’s not deny it; we’ve all been consumed by the aesthetic symmetry of the Data Product. If you’ve not yet come across it, you’re probably living under a rock. But don’t worry, before we get into any higher-order solutions, we’ll dive into the fundamental concepts as we always do.
On the other hand, data modeling has been an ancient warrior, enabling data team to navigate the wild jungle of increasingly dense and complex data. But if data modeling was the perfect solution,
→ Why are organisations increasingly complaining about poor ROI from their data initiatives?
→ Why are data teams under an ever-increasing burden of proving the value of their data?
→ Why are data models increasingly clogged and costlier than their outcome?
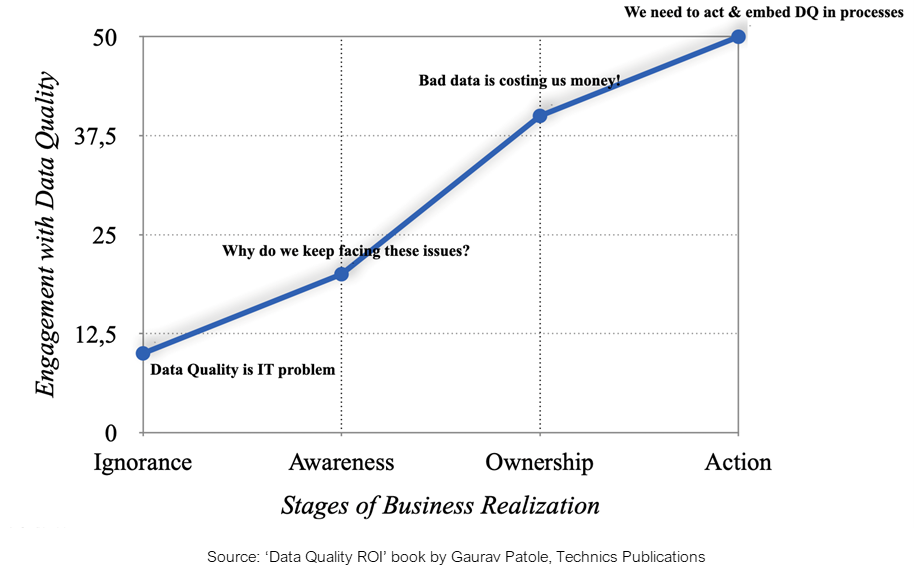
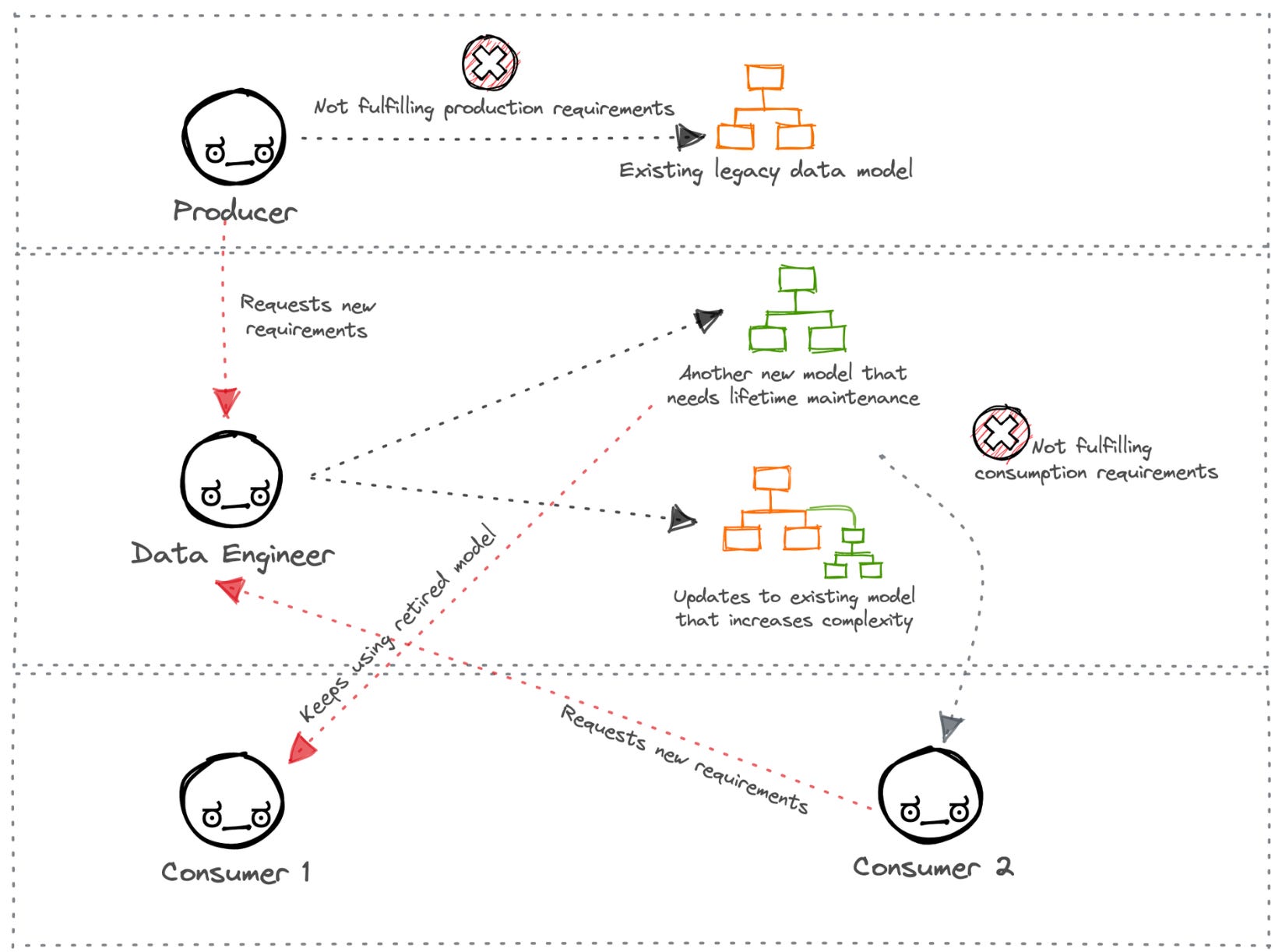
Well, the answer is we haven’t been doing data modeling right. While data modeling as a framework is ideal, the process of constructing a data model suffers from weak foundations.
It lacks consensus and transparency between business teams that own the business logic and IT teams that own the physical data. While one side restructures even mildly, the other side is thrown into chaos and left to figure out how to reflect the changes delicately enough not to break any pipeline.
In this article, we’ll briefly illustrate an overview of data modeling, data products, solutions that the data product paradigm brings in with respect to modeling, and enablers of the same.
This piece is ideal for you if you lead a data team or are in a position to influence data development in the team or organisation.
Data modeling is not the sole pillar that bears the weight of raging data. In fact, it comes way later after several pillars across the data journey. To understand the problems associated with data modeling, we must have a high-level understanding of all the laters that come before it.
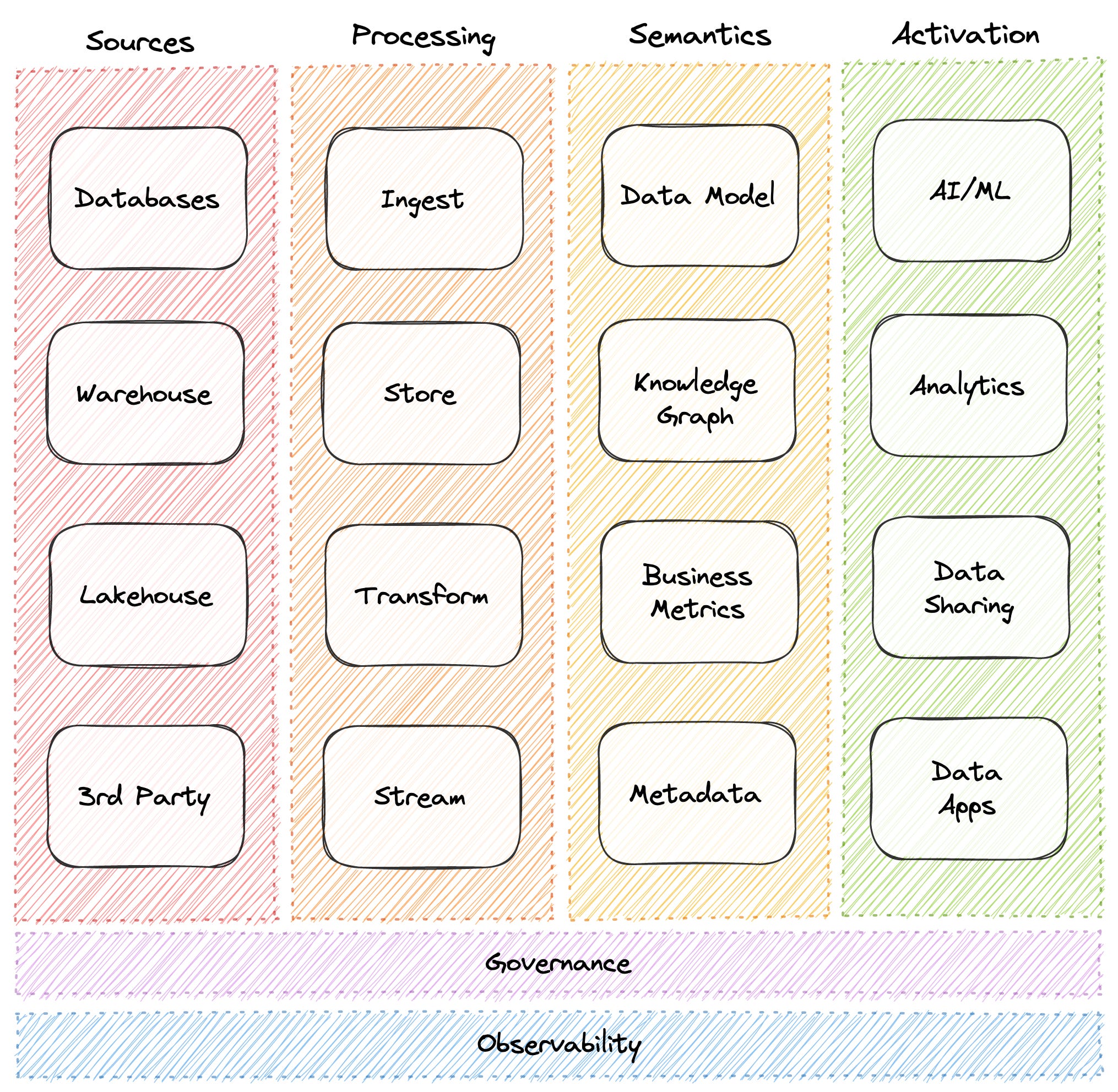
Data Modeling sits almost the far end in the semantic layer, right before data gets operationalised for disparate use cases.
Now that we know approximately know where a data model sits in the enormous data landscape, we’ll look at the role of the data model and what it is able to achieve from its office on the semantic floor.
If you were a data model, you would essentially become a librarian. You would need to:
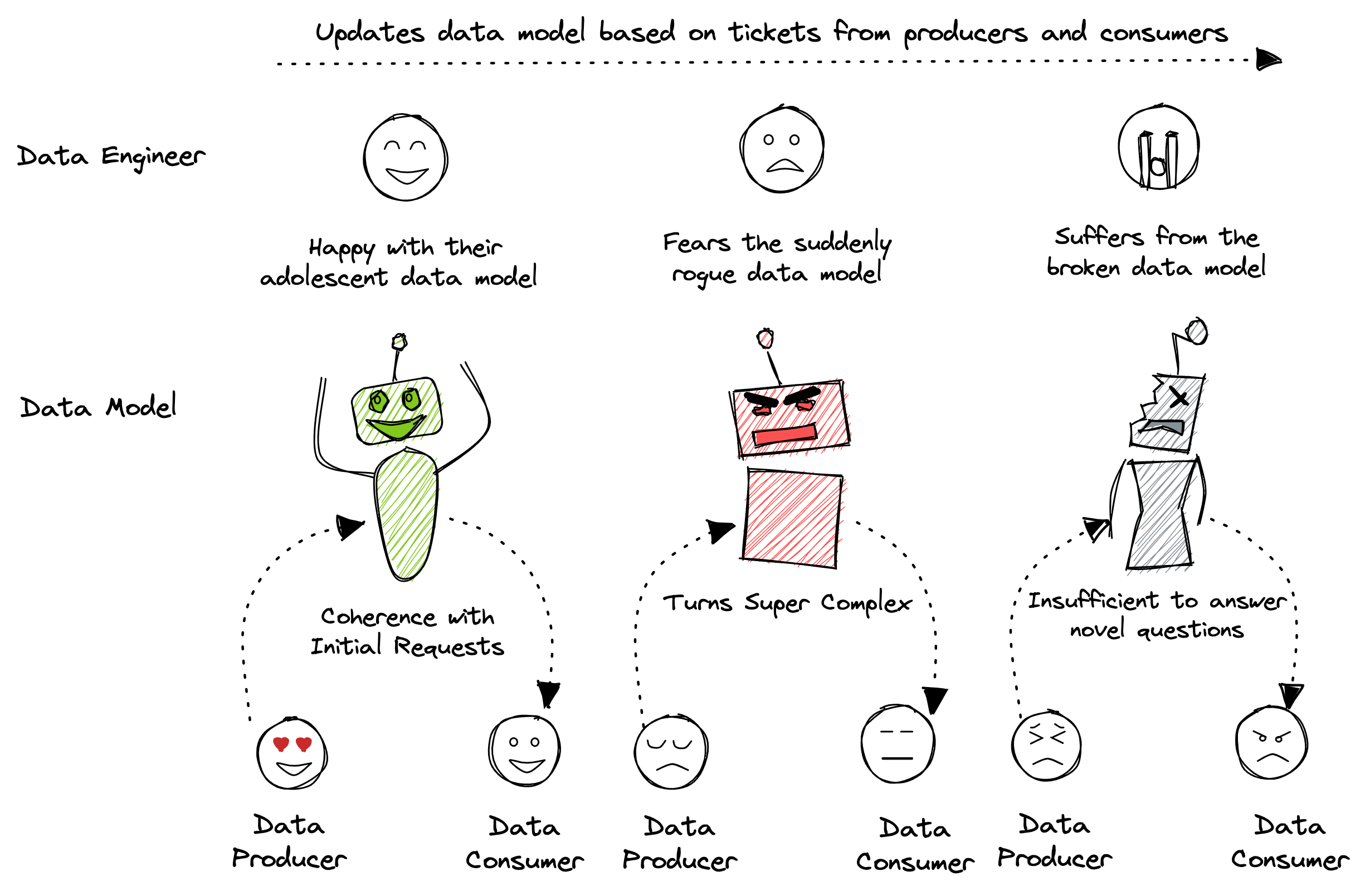
But as we saw in the introduction, data models do not scale well over time in prevalent data stacks, given the constant to and fro with data producers and consumers. This image should summarise the push and pull and highlight the burden it imposes on the central data engineering team and the anxiety it results in for producers and consumers.
In this spiel, we’ll get an overview of:
Understanding Data Products
Visualising Data Products on a DDP Canvas
How Data Products Resolve Challenges in Traditional Modeling
I feel the need to clearly call out what a data product is across most pieces where I mention Data Products. While it feels redundant while writing, it is essential since the phrase “data product” has been unintentionally bloated across the community.
I find that tons of brands in the data space are somehow sticking a “data product” tag to their narratives, and when you open up the product, you find little to no resemblance to data products as it was intended.
A data product is definitely not just data. It’s the data, along with the enablers for that data.
🗒️ Data Product = Data & Metadata + Code + Infrastructure
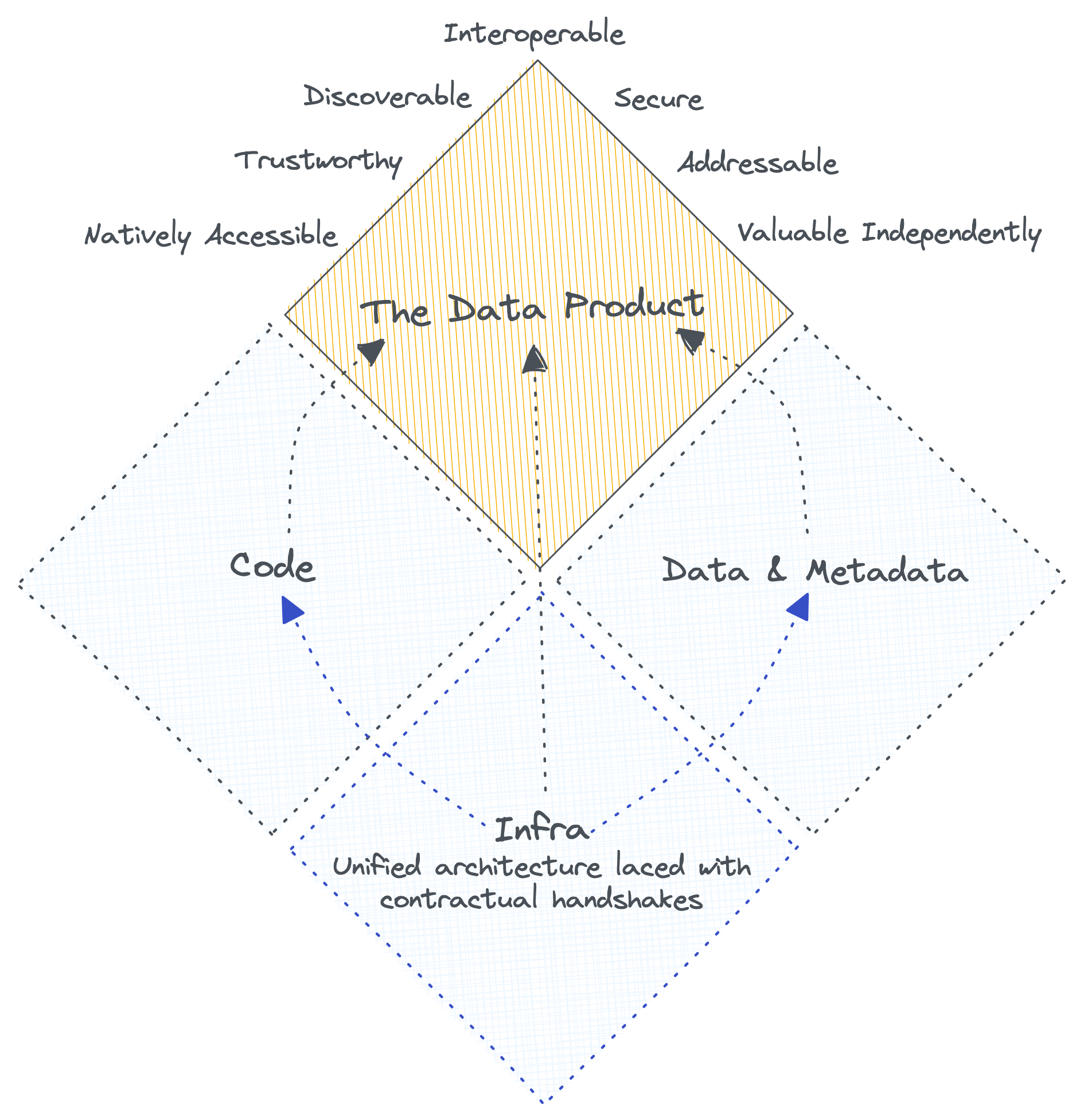
This blurb should give more clarity around each of these components and how they are associated and enabled: “Data First Stack as an Enabler for Data Products” →
Now that we are somewhat clear on what makes up a Data Product let’s visualise it in terms of the data landscape.
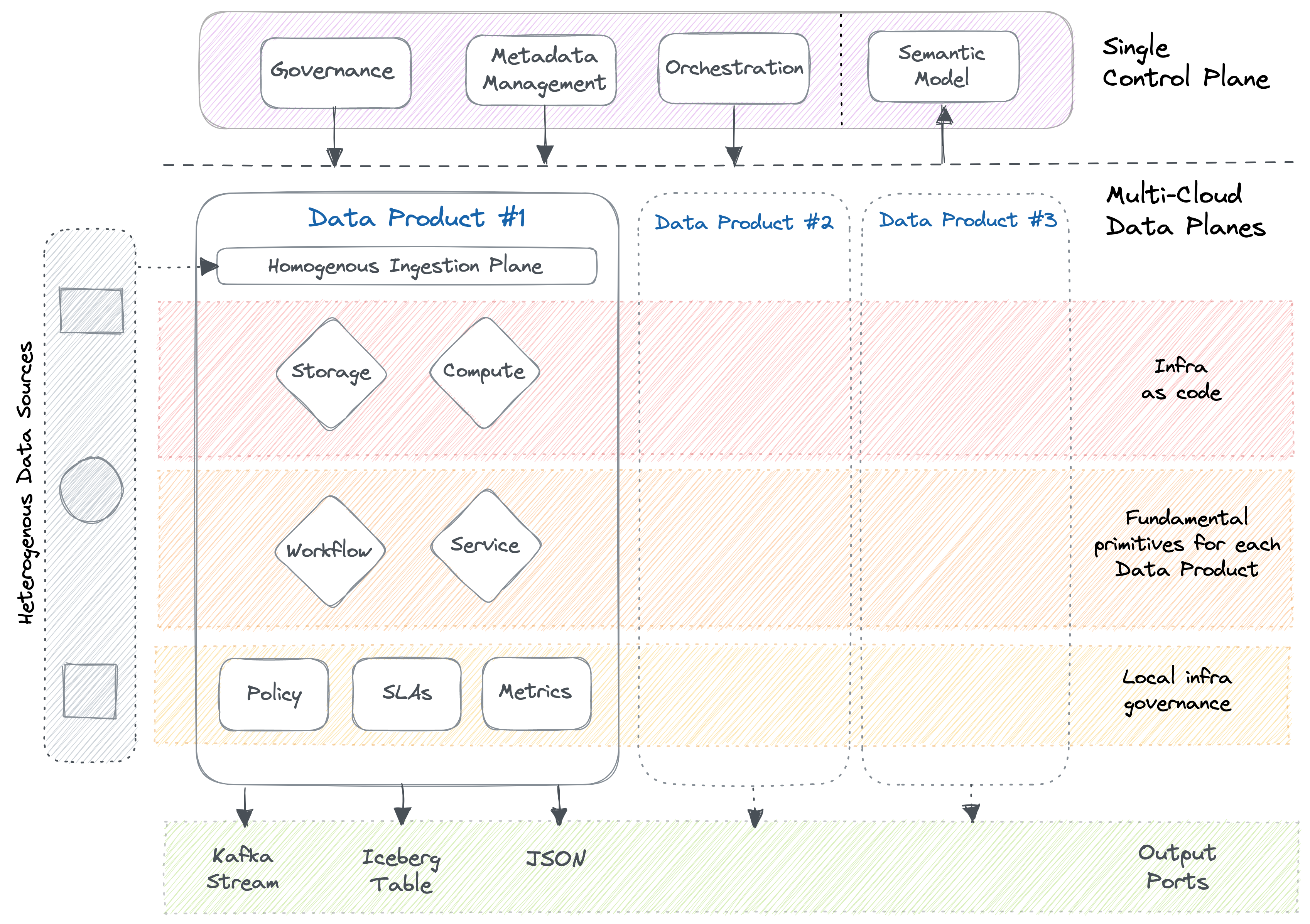
The above is a 10,000 ft. view of Data Products as enabled through the infrastructure specification of a data developer platform (DDP).
Some key observations to note here:
Before we move to the solutions, let’s have a glance at the most persisting challenges of data modeling.
This article is a great resource to learn about these challenges at a glance.
Now, let’s look at the data product landscape one more time.
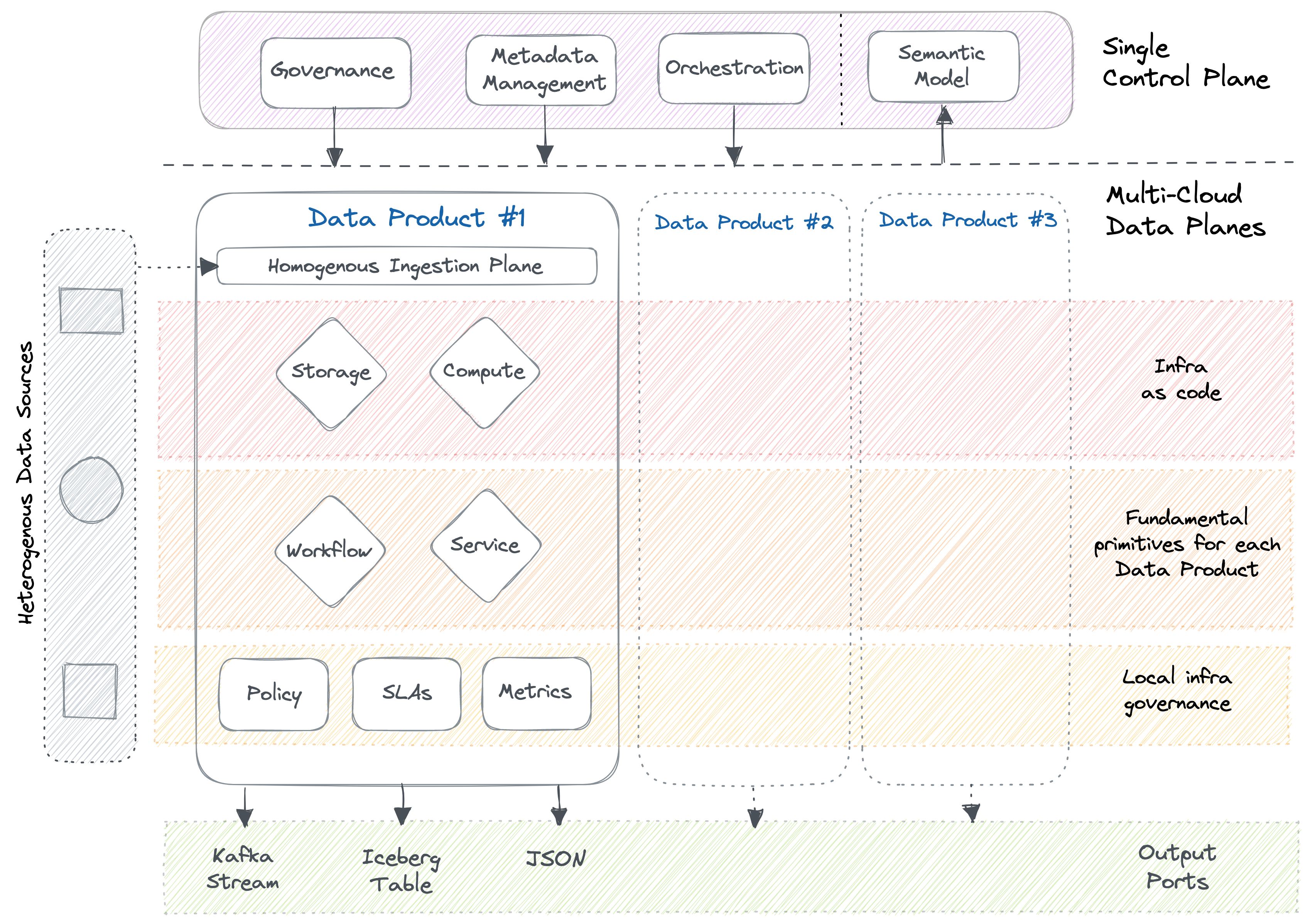
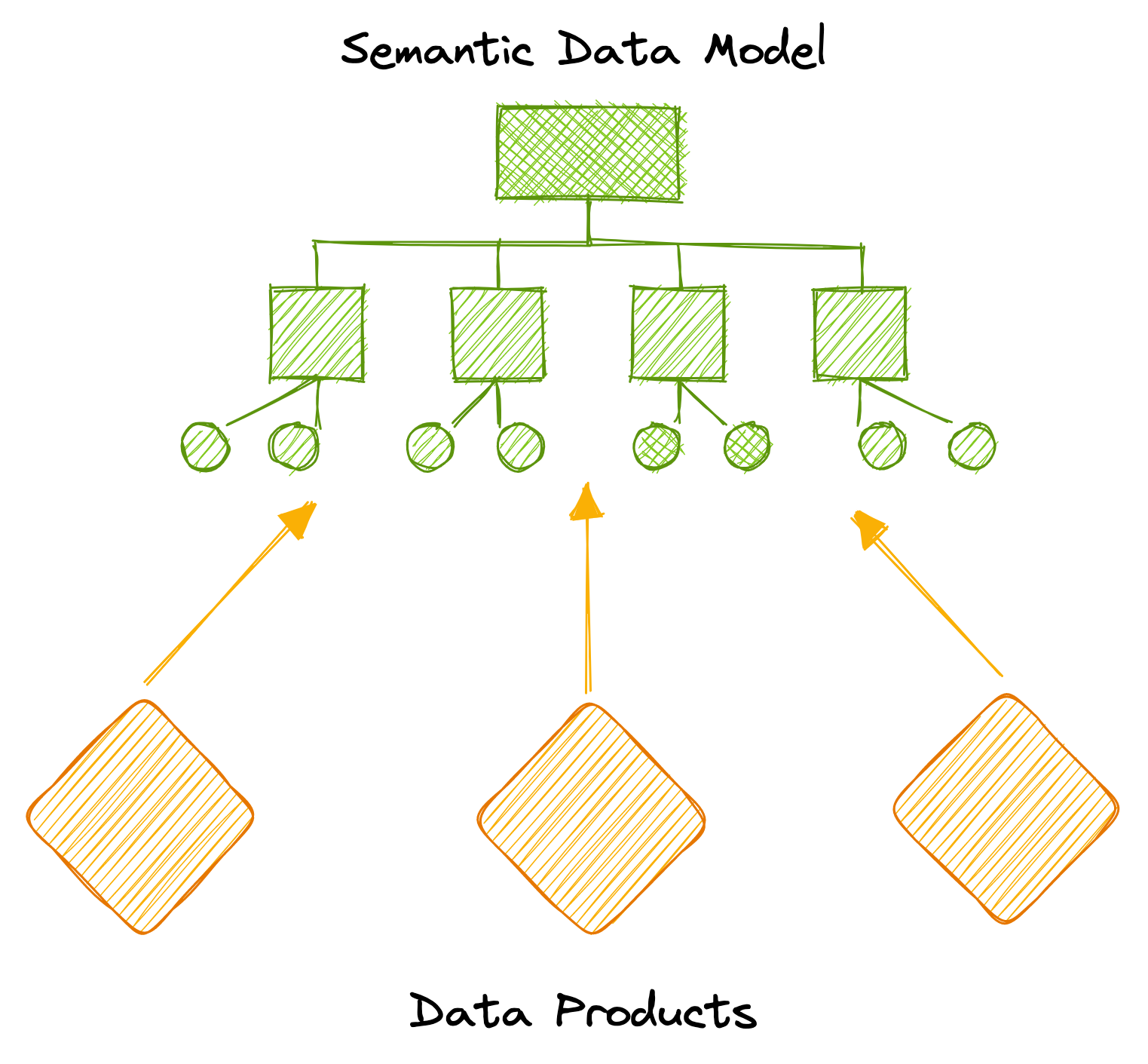
This landscape proposes a logical abstraction or a semantic data model that essentially decouples the modeling layer from the physical realm of data. The Semantic Model consumes data entities fed as data products.
It is essential to realise that not all data can be curated as data products and, in fact, shouldn’t be curated as data products. Otherwise, it would result in more data around data products than the actual data owned by the organisation. It is simply not practical.
Instead, there should only be a select few data products owned by an organisation. And this would be data that represent the core entities the business works with. In real-world scenarios, most businesses have limited operations within 10-15 key entities. It, therefore, makes sense to curate high definition product-like experiences for these select few. For example, a customer360 data product gives a well-rounded view of the customer entity.
Every such data product has inherent quality checks and governance standards that are declaratively taken care of by the data product’s underlying infrastructure once the SLAs are defined by business counterparts and mapped to the physical layer by engineering counterparts. Any data that is activated through the semantic data model is, therefore, a derivative of high-quality and well-governed data products channelling into the model.
Data evolution is one of the biggest challenges for stubborn data pipelines - the primary cause behind multiple breakages at the hint of slight change or disruption in data.
In the data product landscape, every data product is maintained by a specification file or a data contract that, alongside quality and governance conditions, also specifies the semantics and shape of the data. This could be represented as the ‘SLAs’ components in the represented landscape.
Every time a change, such as a difference in column type, column meaning, or name, is initiated in prevalent stacks, it would break all downstream pipelines. Whereas, in a stack embedded with contracts, the breakage or change is caught at the specification level itself, which, paired with the respective config file in a DDP, allows dynamic configuration management or single-point change across pipelines, layers, environments, and data planes.
If the change is non-desirable, the change is pushed back to the producer from the higher spec level for revision or validation.
In this article, we shared an overview of the objectives of data models, data products as a construct and the data product landscape as implemented through a DDP infra spec, and understood how it becomes an enabler for data modeling.
We discussed how abstracting the data model as a semantic construct helps to shift the ownership and accountability to business teams, thus, unburdening the central teams and omitting bottlenecks.
And in conclusion, we saw how data products as a layer before logically abstracted data models largely solve data quality, governance, evolution, and collaboration challenges that are often seen in traditional and modern data delivery approaches.
Most of the concepts in the article are largely conveyed through diagrams instead of text for ease of consumption.
Travis Thompson (Co-Author): Travis is the Chief Architect of the Data Operating System Infrastructure Specification. Over the course of 30 years in all things data and engineering, he has designed state-of-the-art architectures and solutions for top organisations, the likes of GAP, Iterative, MuleSoft, HP, and more.
Animesh is the Chief Technology Officer & Co-Founder @Modern, and a co-creator of the Data Operating System Infrastructure Specification. During his 20+ years in the data engineering space, he has architected engineering solutions for a wide range of A-Players, including NFL, GAP, Verizon, Rediff, Reliance, SGWS, Gensler, TOI, and more.
Since its inception, ModernData101 has garnered a select group of Data Leaders and Practitioners among its readership. We’d love to welcome more experts in the field to share their story here and connect with more folks building for better. If you have a story to tell, feel free to email your title and a brief synopsis to the Email Editor.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


