



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...





TABLE OF CONTENT




This is the first of a two-part series exploring the scope of data products in a dynamic landscape. This article delves into managing the evolving scope of individual data products in a Data Mesh architecture.
The building blocks of the Data Mesh architecture are data products and discrete items that make data usable to others. While a good Data Mesh will contain many data products, as the number proliferates, this can introduce complexity and governance challenges. Therefore, it’s essential to have a robust framework to manage dependencies, coordinate updates and ensure data consistency across the ecosystem.
This involves defining clear ownership and accountability for each data product and assigning dedicated teams or individuals to handle development, maintenance, and evolution.
1. Challenges are caused by having multiple data products for the same data source
2. Impact of multiple DPs reading from the same operational system
3. Duplication due to different data products addressing the same business needs
4. The need for strong governance and ownership structures
Organizations attempting to shift into a federated data environment via Data Mesh require strong data governance to avoid the accidental explosion of data products that can lead to increased complexity, duplication of effort, and ownership issues.
When multiple data products are created for the same data source, it puts a strain on the source systems. This also has the potential to result in performance issues for transaction applications. While it’s common to have different data products reading various categories of data from the source systems, it is crucial to carefully design the relationships between data products and source data, considering the specific needs and requirements of each data product.
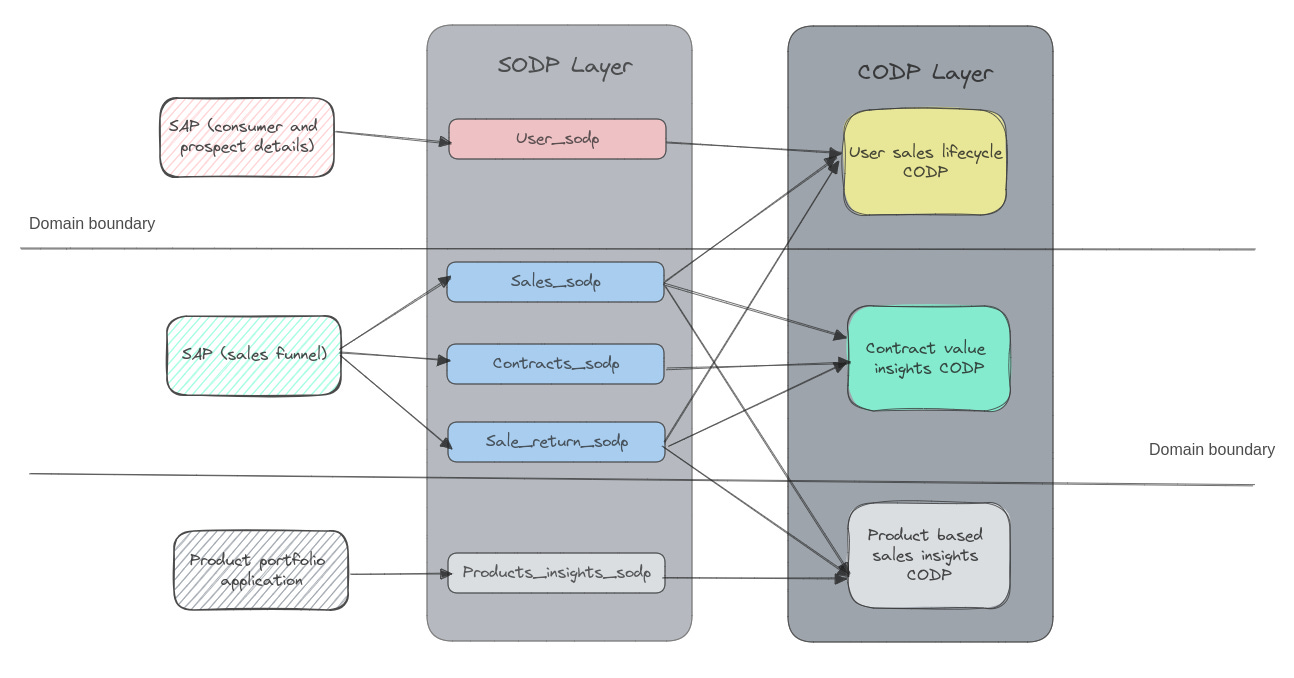
Leveraging source-oriented data products (SoDP) and promoting data product reusability serves as a strategic means to alleviate undue stress on source systems, yielding a streamlined and efficient operational landscape. This approach helps to avoid unnecessary replication of data in the Data Mesh or data catalogue, leading to a more streamlined and efficient data ecosystem. It enables consumers to access the required information from the appropriate data product without encountering redundant or conflicting data.
This helps:
1. Improve data quality
2. Simplify data discovery
3. Ensure consistency across the organization’s data landscape
By addressing complexities and governance issues, organizations can streamline their data product ecosystem, ensuring efficient collaboration, adherence to standards, and effective management of data assets. This helps teams to work cohesively, and fosters trust in the data products and the Data Mesh architecture.
To strike a balance between granularity and simplicity, creating data products that are modular, agile; and aligned with the overall objectives of the organisation is crucial.
Duplication can also develop because of different domain teams solving the same or similar data use cases. This is particularly visible in consumer-oriented data products (CODPs) generated through the collaboration of multiple data products. Another reason could be that different teams require the same data use cases to be addressed or that one team is attempting to build a data product for a specific use case.
One way to manage duplications in the Data Mesh is by implementing a feedback-based ranking system. This system considers the maintenance of Service Level Objectives (SLOs) and Service Level Indicators (SLIs) of data products. A well-maintained data product that meets the required SLOs and SLIs will receive higher quality points, resulting in a higher ranking during the discovery phase. The data product will receive more visibility with a higher rank, leading to increased search and use. Hence, it promotes continuous improvement.
This approach is referred to as a “feedback-based ranking system” or a “quality-based ranking system.” It aligns with the principles of feedback-driven development, quality management, and data product lifecycle management. The implementation of such a system involves the following:
1. Data product discovery mechanisms
2. Feedback collection and analysis
3. Ranking algorithms
4. Retirement and archival processes.
📝 Note from Editor: Learn more about SLOs and SLO evolution here
How to Build Data Products | Evolve: Part 4/4
As part of this ranking system, a fitness function can be used to evaluate the performance and quality of data products. A fitness function is a mathematical function that assesses the data product based on predefined criteria, such as data quality, reliability, timeliness, availability, user satisfaction, and adherence to service level agreements (SLAs). By incorporating relevant metrics and feedback from users, such as usage patterns, user ratings, response times, and data accuracy, the fitness function assigns scores or rankings to data products.
By leveraging a fitness function, the system can objectively evaluate and prioritize data products based on their performance against the defined criteria.
Data product versioning is the systematic monitoring and control of modifications to the data product as it evolves. Like software versioning, it involves the allocation of a distinct identifier or label to diverse iterations or releases of the data product. This identifier plays a pivotal role in distinguishing and singling out the data product versions, enabling efficient administration of updates and changes.

Versioning a data product:
Navigating the complexities of evolving individual data products within a Data Mesh architecture demands a strategic approach. Robust governance, ownership structures, and source-oriented data products (SoDP) are essential to ensure streamlined operations and data consistency.
Keep watching this space for Part 2!
We highly appreciate this contribution from Ayush Sharma! Feel free to connect with him and learn more about Data Products and Data Mesh 💠
.avif)
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



