
.avif "Brij Mohan Singh")




TABLE OF CONTENT
Most organisations are currently whiteboarding how to incorporate AI into their data monetisation strategy or how AI can help directly impact monetisable metrics: customer-facing apps and experiences.

To meet ambitious goals with AI, we need to have ambitious goals for data first- the food for AI. Clip the problem of Garbage-In-Garbage-Out at the root.

Enter Data Products. Here’s an example of how Data Products are a game changer for LLMs & AI in general. But in this piece, we want to dedicatedly talk about optimising Data Product development through AI to build and scale Data Products more quickly, naturally, and effectively.
FAQ: Aren’t Data Products built to drive better AI solutions?
How does it make sense the other way around?
Classes of AI
There are different classes of AI with different complexities. From simple models to uber-complex neural networks and tree-algorithms. At the operational level, even simple AI structures can prove extremely effective. For example, AI-powered data crawlers for identifying anomalous database updates.
This does not require a high contextual understanding and can operate at a very fundamental level of structural patterns. More reason why the simplest AI - Regression is still the most in-use form of AI
The data product lifecycle greatly benefits from such operational AI of many classes. From Design to Evolution, Data Products could and are being developed at a pace quicker than previously imagined. Any apparent complexities are trimmed down to simpler operations through AI augmentation.
Challenges Orgs Face While Building Data Products
While data products are the solution to several data challenges, the process of building these purpose-driven data products may be perceived as a big cultural jump by many organisations, especially ones with their toes deep in legacy systems.
- Lack of enough skills in data teams to serve product-like functions and roles
- Inability to Scale into an ecosystem of Data Products (lack of skills & resources)
- Data Product-Washing: Adding another layer of redundancies instead of an authentic data product layer (lack of product mindset and understanding)
- High time-burn in the data product lifecycle (misunderstanding product implementation)
- Prioritisation mishaps: The number #1 skill of any product driver is prioritisation, but with so many pre-existing requests, it’s easy to lose sight
As you can observe, most challenges stem from cultural or mindset gaps, which is undeniably a big resistance to true Data Product adoption. Adopting the “Product Mindset” cannot just be dumped on data citizens who’ve been used to working a certain way for a long time across traditional or modern data stacks.
AI is closer to humans than any other technology. At least in the realm of data. It is able to step in where the human mind would wander or resist, making processes seem more natural and simpler. In essence, AI doesn’t just help dissolve habitual resistances and evolve culture around stubborn processes, but in doing so, takes us forward in establishing data products at scale.
This article will look into the key areas where AI can complement the data product journey and bridge the data and its users gap.
Key Areas Where AI Complements The Data Product Journey
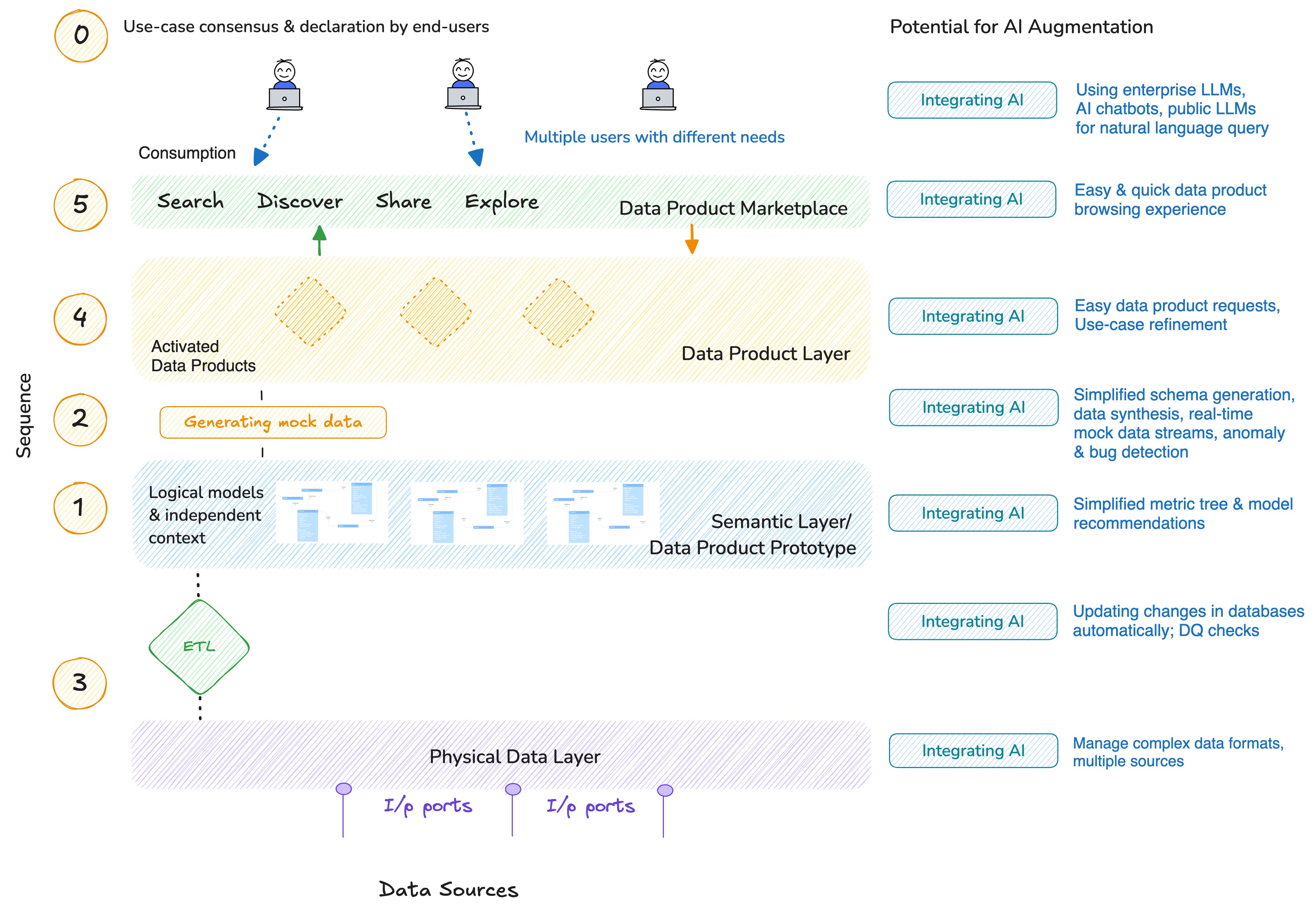
0-1. Polishing Processes at the Semantic Layer


Prioritizing the Right Use Case
The process of identifying the critical use cases across domains has to be largely manual, given that it involves a high degree of strategy and critical thinking. However, using metrics and insights from existing processes or data products could add an extra edge.
For example, a Marketing Manager can ask an existing Data Product, “Which customer segment has performed poorly over the last two quarters, and what are the potential anomalies associated with this segment".”
Based on the insights, new use cases can be developed to improve segment performance. Here’s more on how Data Products help with use case expansion.
We have discussed the process of building these purpose-driven metric-first data products in one of our earlier blogs. For those of you who want to access the details, here’s the link.
At a glance, this is how the process looks:
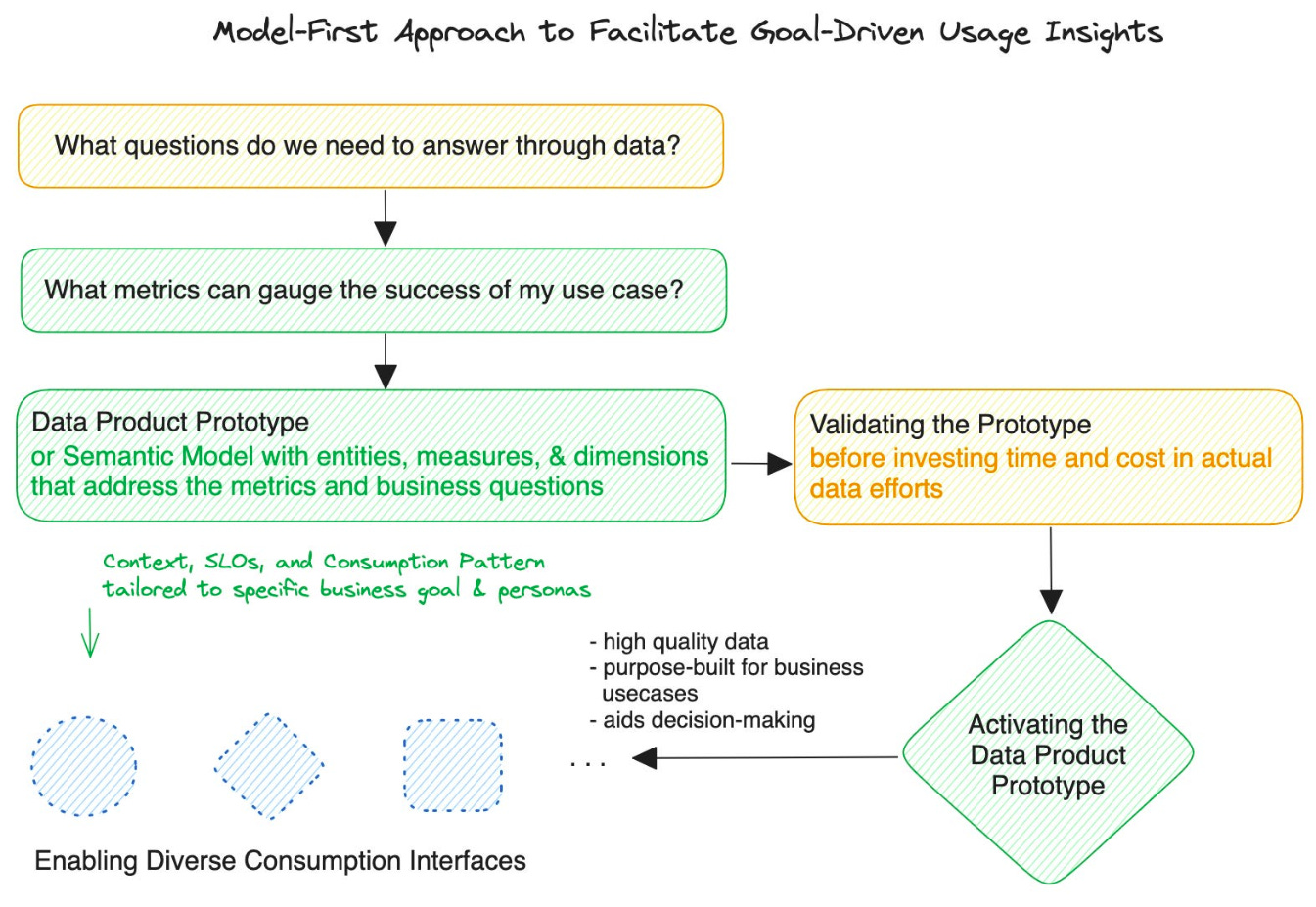
The semantic layer is powered by the logical models of the data product prototypes. And this is initiated by business questions.
Imagine an enterprise using ChatGPT or their enterprise LLM
These tools instantly empower everyone to ask questions proficiently without any expert skills or qualifications. Without having to talk to a REST interface, master complex SQL queries, or configure intricate APIs, you just need to learn how to ask the question (which is also super important).
While we identify the business pain points and develop a few questions around them, AI can help us develop further questions or recommend modifications to existing questions. This helps create a larger ‘question tree’, and the more the right questions are created, the more accurate will be the metrics built around those questions.
Solving the Blank-Canvas Problem to Fastrack Metric Trees
The blank canvas issue is one of the biggest friction points across all human-driven processes. Just like writer’s block, it can be challenging to whiteboard a bunch of metrics and figure out potential associations based on the queries and questions demanded by the use case at hand.
While AI (lower classes) wouldn’t give you the perfect results that match your domain’s goals or context, it helps to instantly overcome the blank canvas ditch. You get a fair idea of where and how potential relationships could be and then you pick up from there with strategic ability and context that’s only accessible to humans.
Just by using a public LLM like ChatGPT or an enterprise LLM that has greater context into the company's business domain (like e-commerce), the PMs, SMEs, and other stakeholders involved can quickly get recommendations for more intricate sub-questions. This cuts down time for brainstorming and quickly offers a large number of questions that can be directly used or help trigger new ideas and strategies.
Solving the Blank-Canvas Problem to Fastrack Logical Models or the Data Product Prototype
Rinse and repeat the process for the semantic models. Where AI can chip in:
- Recommending associations.
- Recommending contextual descriptions/tags for entities, measures, & dimensions.
- Recommending standard access SLOs usually implemented at that domain’s level
- Recommending quality checks based on the entity, dimension, or measure’s description, meaning, or tags
2. Simplifying Mock Data Generation

Generating mock data streams for validating data product prototypes can be a cumbersome task due to the complexity and low-level nuances of domain-specific data. But AI attempts to make it a cakewalk today.
Let’s assume you are on the operations team in the moving enterprise and want to build a data product, say, ‘Route Efficiency Optimiser.’
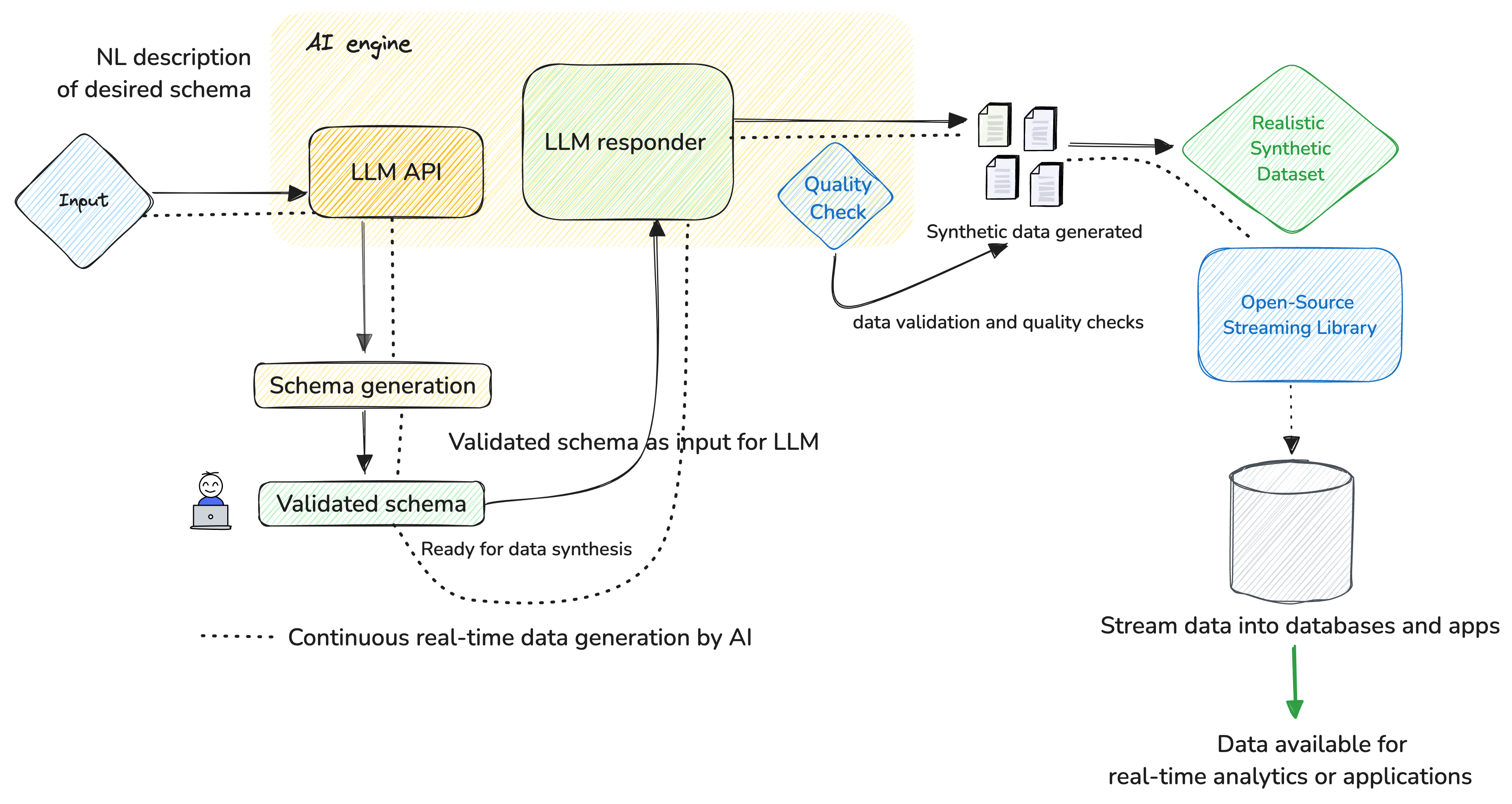
Schema Generation
A schema for a logistics dataset might include columns like Route ID, Vehicle ID, Start Location, End Location, Distance, Travel Time, Delivery Volume, Delivery Time Windows, Cost, etc.
AI can interpret this schema and generate the appropriate data types, such as:
- integers for Route ID, Vehicle ID, Delivery Volume, and Stop Count;
- floats for Distance, Travel Time, Delivery Volume, and Cost, and
- strings for Start Location, End Location, and Delivery Time Windows.
AI can then analyze this data to identify patterns, optimize routes, and improve overall route efficiency. AI can handle more complex structures, such as nested JSON objects or arrays, which are common in real-world data scenarios.
An AI engine also enables finding relationships between data assets, such as tables or other entities, that can be joined for a data product.
The process of schema generation is equally aided by AI in both stages of creating mock data as well as while dealing with the real data.
Data Synthesis
Once the schema is defined, AI can generate synthetic data that mimics real-world data patterns. This includes:
- Randomized Data Generation: Creating diverse data points that follow specified distributions, such as generating a range of transaction amounts for financial data.
- Pattern Recognition: Generating data that follows specific patterns or correlations, such as time series data for monitoring systems.
Real-Time Mock Data Streams
Using APIs to send prompts and receive generated schemas. For example, integrating with OpenAI's API allows for seamless schema creation. OpenAI's GPT-4 or similar LLMs. AI can generate real-time mock data streams, which is essential for testing event-driven architectures and real-time analytics platforms.
This is particularly useful for applications like real-time personalization, fraud detection, and dynamic inventory management.
3. Simplifying Processes at the Physical Data Layer

Let’s take the example of a Moving company.
Assume you are on the operations team in the moving enterprise and want to build a data product, say, ‘Route Efficiency Optimiser ' that optimizes delivery routes to reduce fuel consumption, time, and operational costs.
To achieve this, they need to integrate data from various sources such as GPS tracking systems, traffic data, customer addresses, and vehicle performance metrics.
At the physical data layer, this would require diverse datasets acquired from different sources. What does the AI engine do here?
🦀 Simplifies data extraction with AI-driven data crawlers
AI-driven tools can automatically discover and connect to different data sources, including databases, APIs, and cloud storage. In this case, the AI-driven connectors can automatically fetch real-time and historical traffic data from services like Google Maps or Waze to help understand traffic patterns and adjust routes accordingly.
AI-powered crawlers can pull real-time location data from GPS devices installed in vehicles. This data is crucial for tracking vehicle positions, optimizing routes in real-time, and ensuring timely deliveries.
Seamlessly obtaining data from multiple data sources paves the way for combining these datasets and using them to build the required data products. In this case, the combined data from telematics systems, vehicular GPS, and maps render vehicle performance data, delivery data, different vehicle metrics, and more.
🕵️ Enables easier identification of workflow segments
AI-driven algorithms and tools enable orgs to easily detect workflow segments that can automate repetitive tasks like extraction, categorization, and validation of data. NLP algorithms also help sort large volumes of textual data and extract relevant information & insights quickly and accurately.
♻️ Helps automate low-level transformations
By simplifying low-level tasks with AI, data engineers can focus on more advanced tasks such as designing data applications, data models, and insight generation. AI could help automate low-level transformation rules, such as normalizing location data, low-level aggregation, and enriching delivery schedules with traffic predictions.
For instance, an AI-powered ETL tool in the same Moving and Removal company extracts GPS data from the fleet's tracking systems every hour. This data is automatically transformed into standardized formats (e.g., converting different timestamp formats into a unified format) and then loaded into their analytics database.
By automating this routine ETL task, the company’s data engineers now focus on advanced tasks such as designing sophisticated data models and predicting optimal delivery routes by analyzing traffic data, vehicle performance, and weather conditions.
4-5. Simplifying Processes in the Data Product Layer and Consumption in the Data Product Marketplace


📩 Smarter Requests on the Data Product + Request Prioritisation
Multiple teams across your org put up several data product requests that are often difficult to filter, sort, and handle as a whole. Again, users, while requesting data products, often struggle with the tiresome processes of writing down specifications.
AI can step in by:
- Improve the quality of requests by prompting recommendations
- Help providers understand the context of requests more naturally to decide on priorities
🚀Consumption: Accelerating the search for datasets
There would always be a surplus of data. The benefit of data products is that it channels out only usable and reliable data. The data experience gap could be closed further through AI augmentation.
Just like any other e-commerce shopping experience, a data product marketplace greatly benefits from AI’s recommendation power.
- Based on your user role, AI would optimally highlight Products suitable for you or ones that your domain uses frequently
- Based on product usage, AI would recommend top assets within the data product or guide the user through an optimised consumption path
- Browsing experience also benefits from AI integration. Recommendations, along with role-specific filters and categories.
- Based on user history, AI also streamlines the go-to insights or metrics on the consumption interface for the user to dive into—like an analytics dashboard smartly weeding through data surplus.
This ensures personalised user experiences - closing that last-mile gap between humans and data.
Final Word: The Significance of Personalised Experiences
A few years ago, Forbes estimated that 86% of buyers would pay more for a great customer experience. That number is only expected to have gone up in the rapid transition we witnessed during the last two years. More recently, McKinsey estimated that the 25 top-performing retailers were digital leaders. They are 83% more profitable and took over 90% of the sector’s gains in market capitalization.
Experience is No Longer a Competitive Edge, but a Must-Have
Most of the brands that are successfully thriving today have consistently focused on becoming experience-first. They have tapped into data at every touchpoint across the customer journey to truly graph out the customer’s behavioural patterns. Any new event gives them the advantage of tracking down the potential decisions of the customer so they can fork their operations accordingly.
Customer’s Dependency on Personalisation
Customers are used to transactional experiences and consider them the bare minimum. Thus, their attention today is automatically drawn towards brands that provide more than the bare bones. In fact, most have started depending on data personalization to guide their purchase decisions. Personalization is the new currency.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
📝 Meet the Authors!

Find me on LinkedIn

Find me on LinkedIn
From The MD101 Team
Bonus for Sticking With Us to the End! 🧡
Here’s your own copy of the Actionable Data Product Playbook. With over 200 downloads so far and quality feedback, we are thrilled with the response to this 6-week guide we’ve built with industry experts and practitioners. Stay tuned on moderndata101.com for more actionable resources from us!







